Recall, Precision, and Average Precision
原博:https://blog.csdn.net/pkueecser/article/details/8229166
信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
分类: 1.自然语言处理/机器学习在信息检索、分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常重要,因此最近根据网友的博客做了一个汇总。
准确率、召回率、F1
信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate),召回率也叫查全率,准确率也叫查准率,概念公式:
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
图示表示如下:

注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图:

如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。
所以,在两者都要求高的情况下,可以用F1来衡量。
- F1 = 2 * P * R / (P + R)
公式基本上就是这样,但是如何算图1中的A、B、C、D呢?这需要人工标注,人工标注数据需要较多时间且枯燥,如果仅仅是做实验可以用用现成的语料。当然,还有一个办法,找个一个比较成熟的算法作为基准,用该算法的结果作为样本来进行比照,这个方法也有点问题,如果有现成的很好的算法,就不用再研究了。
AP和mAP(mean Average Precision)
mAP是为解决P,R,F-measure的单点值局限性的。为了得到 一个能够反映全局性能的指标,可以看考察下图,其中两条曲线(方块点与圆点)分布对应了两个检索系统的准确率-召回率曲线
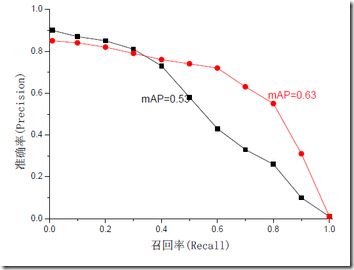
可以看出,虽然两个系统的性能曲线有所交叠但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。
从中我们可以 发现一点,如果一个系统的性能较好,其曲线应当尽可能的向上突出。
更加具体的,曲线与坐标轴之间的面积应当越大。
最理想的系统, 其包含的面积应当是1,而所有系统的包含的面积都应当大于0。这就是用以评价信息检索系统的最常用性能指标,平均准确率mAP其规范的定义如下:(其中P,R分别为准确率与召回率)
ROC和AUC
ROC和AUC是评价分类器的指标,上面第一个图的ABCD仍然使用,只是需要稍微变换。

回到ROC上来,ROC的全名叫做Receiver Operating Characteristic。
ROC关注两个指标
True Positive Rate ( TPR ) = TP / [ TP + FN] ,TPR代表能将正例分对的概率
False Positive Rate( FPR ) = FP / [ FP + TN] ,FPR代表将负例错分为正例的概率
在ROC 空间中,每个点的横坐标是FPR,纵坐标是TPR,这也就描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此我们可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0)(1,1),实际上(0, 0)和(1, 1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。如图所示。

用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。
于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance。
AUC计算工具:
http://mark.goadrich.com/programs/AUC/
P/R和ROC是两个不同的评价指标和计算方式,一般情况下,检索用前者,分类、识别等用后者。
参考链接:
http://www.vanjor.org/blog/2010/11/recall-precision/
http://bubblexc.com/y2011/148/
http://wenku.baidu.com/view/ef91f011cc7931b765ce15ec.html
基础学习笔记——Recall, Precision, and Average Precision
以下内容绝大部分内容翻译自:
Mu Zhu , Recall, Precision, and Average Precision. Working Paper 2004-09 Department of Statistics & Actuarial Science University of Waterloo.
1. 先介绍一些基础内容和符号说明
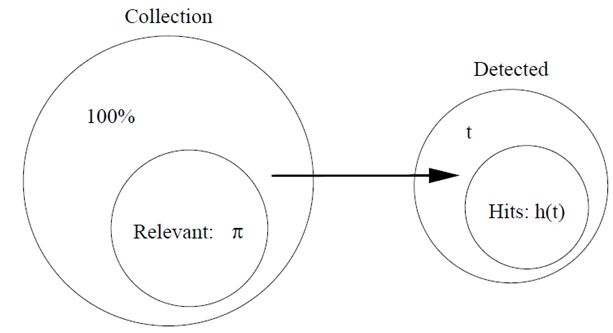
C:一个很大item的集合。
π:集合中相关的item的集合(π<< 1)。
t:算法所识别出的item的集合。
h(t):t中确实相关的item的集合,通常这部分称作命中(相反的是丢失)
下面看一些典型的“命中”曲线
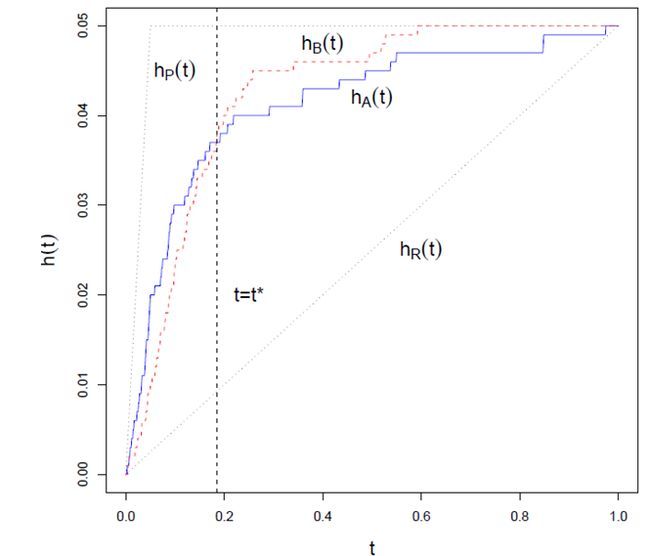
假设其中相关item为5%。
hP(t)曲线是理想的曲线,几乎排在前面的所有的识别都命中了,直到5%,所有的相关item都耗尽了,曲线不再变化。
hR(t)曲线是随机选择的曲线
hA(t)和hB(t)是典型的识别曲线
(两条曲线相交是可能的)
“命中曲线”能够很清楚地告诉我们一个模型或者是算法的性能好坏。例如,如果在任何时候,有 hA(t)>hB(t),则算法A毫无疑问比算法B出色;如果一般情况下,一条曲线总是随着t的增长而快速增长,则这个算法被认为是强壮的;特别的,一个最好的算法应该拥有最大地斜率,直到 t=π。
然而,我们需要的不仅是对算法好坏的评估和比较,而是要往好的方面来调整算法。经常,我们需要半人工地来产生一些算法的最优经验参数就像交叉验证。举例来说,对于
K - nearest-neighbor算法,我们必须选择最合适的K,然后通过交叉验证找出出色的值。因此,我们可以看到,我们更为需要的是一个评估值,而不是一条曲线。
两个数值化的评估方法通常是:recall和precision
2. 简单介绍 Recall 和 Precision
简单定义:
Recall:在所有item中识别出相关item的概率。
Precision:在算法所识别出的item中,真正相关的概率。
形式化定义:
设 ω 是集合 C 中随机取出的一个元素
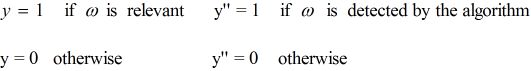
则
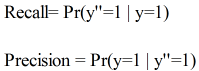
或者可以表示成

3. Recall 和 Precision 之间的关系
引理1:
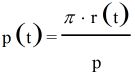
证明: 根据贝叶斯公式,可以得到:
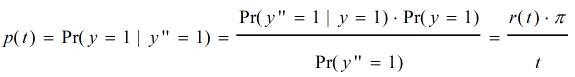
注意:在这里,我们将Precision和Recall都看作是关于自变量 t 的函数,因为一般来说,随着 t 的变化,算法的一些表现也会跟着变化。
h(t) , r(t) , p(t) 都看作是连续光滑的曲线,因为集合C足够大。
引理2:
1. r(0) = 0 r(1) = 1
2. r'(t) >= 0 (t∈[0,1])
证明:
1. 显然,当 t = 0 时,Recall必然为0,因为没有item被检测;
当 t = 1 时,Recall必然等于1,因为所有的item都被检测了,那么也必定包括所有相关的item;
2. 显然,r (t+△t) > r(t) 或者 r (t+△t) = r(t)
所以,r (t+△t) >= r(t)
假设 t 在几乎任何一点都可导,则有:
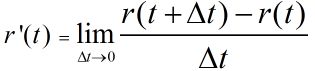 所以 r'(t) >= 0 ( t∈[0,1] )
所以 r'(t) >= 0 ( t∈[0,1] )
引理2说明了 r(t) 是一个非递减函数,而且对于一个典型的识别算法来说,一般都有 r''(t) <= 0,即识别率是渐渐减缓的,直观上来说
随着 t 的上升,识别变得越来越困难。
假设1:假设 r(t) 是二次可微函数,则 r''(t) <= 0 , t∈[0,1].
引理3:假设 p(t) 可微,若假设1成立,则 p'(t)<= 0 , t∈[0,1].
证明:
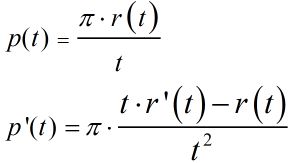
根据中值定理,存在 S ∈[0,t].
使得 r(t) - r(0) = r'(s) (t - 0)
∵ r(0) = 0;
∴ r(t) = r'(s)t
又根据假设1, 有 r''(t) <= 0
所以 r'(s) >= r'(t) (s<=t)
所以 r'(s)t >= r'(t)t
即 r(t) >= r'(t)t
则 p'(t) <= 0
根据之前所证明的,r'(t) >= 0,可以看出,Recall和Precision的确存在某些相互影响的关系。
(此证明基于假设1,r(t)的二阶导数小于等于0,即r''(t)是凸函数)
所以说,单用这两个之中的某一个来评估和比较都不太合适,下面介绍的AP将会同时考虑Recall和Precision,因此常被用来作为衡量和评估的标准。
4. Average Precision(AP)
首先,Precision能被表示成Recall的函数,p(r), 因为 p(t) = π*r(t)/t ,具体见上所述。
AP的定义如下:
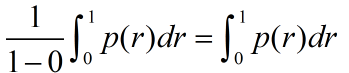
引理4:设r(t)可微函,则:
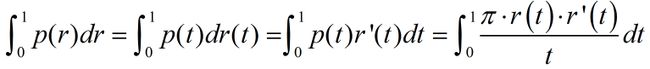
某些情况下,AP并不怎么直观,当 r'(t) = 0时,p(t)必然decreasing in t (无论在哪个区间内)
上面这句话不是特别理解。。。。
然而,因为dr为0,那么AP无论如何不会在此区间内发生变化。
下面举一些例子:
1. Random Selection:
假设 h(t) = π*t,即相关的比例在所有识别的比例中保持为 π
则 r(t) = h(t)/π = t
此时:AP = π
2. Perfect Detection:
h(t)= t [0,π]
h(t)=π (π,1]
这说明:前π个识别,全部命中,即h(t) = t,当π被耗尽时,h(t) = π,保持不变
这是最理想识别,也说明:
r(t) = t/π [0,π]
r(t) = 1 (π,1]
此时的AP = 1;
3. 实际应用中:
假设有n个测试item,将他们根据置信度又高到底排列后,计算:
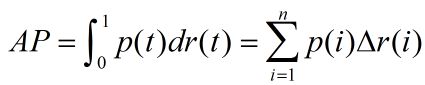
其中,△r(i)表示后一次识别后,recall的变化量,
p(i)可表示为:R/i ,其中R前i个item中,相关的item个数。
因此AP也可表示为:
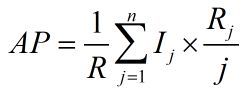
其中,R表示测试集所有的relavant的item个数;
n表示测试集中item的数量;
Ij = 1,如果第j个item相关,否则,Ij = 0;
Rj,前j个item中,相关的item个数;
下面看个例子:
假设这些item的置信度已经由高到底排列:
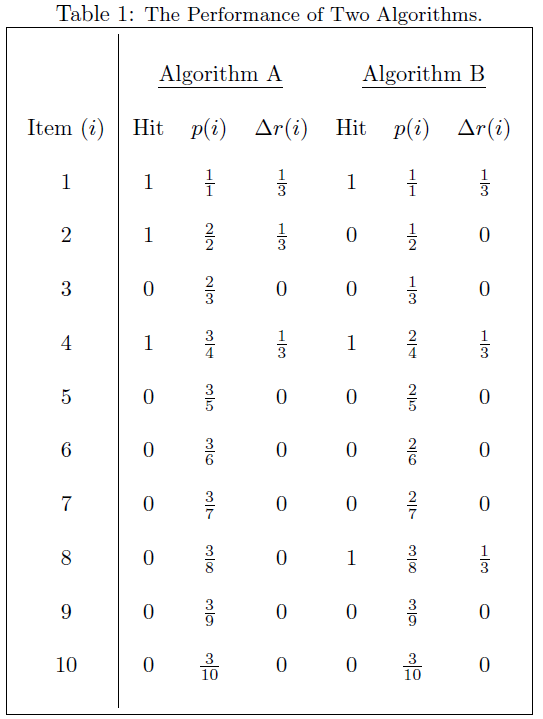
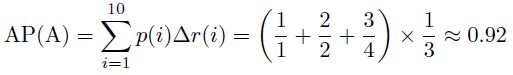
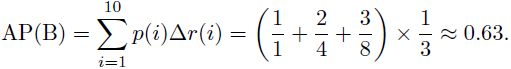
因此,算法A好于算法B。
由此也可以看出,AP这个衡量标准更偏爱识别得早的算法。
后略。
希望大家帮忙改正。
-
IR Evaluation
1.Precision & Recall
2.F-Score
3.ROC Curve ( Receiver Operatng Characteristics)
4.Area under the ROC curve
5.Eleven-point interpolated average precision
5.MAP (Mean average precision)
Precision & Recall
在Information Retrieval 中,最直接用來衡量一個model的效能就是Precision & Recall
Precision : Tp / Tp + Fp , 即表示在所有Retrieve出的document中,有多少是Relevance.
Recall : Tp / Tp + Tn , 即表示在所有Relevance的document中,有多少是被Retrieve到.
在理論上,Precision跟Recall之間是無絕對的對應關係,
但在實際應用上,通常Precision會隨著Retrieval document越多而遞減,而Recall則會遞增.
For Example(假設database中,relevance的document數目為10)
| document |
Positive/Negtive |
Precision |
Recall |
|---|---|---|---|
| 1 |
+ |
1/1=100% |
1/10=10% |
| 2 |
+ |
2/2=100% |
2/10=20% |
| 3 |
- |
2/3=67% |
2/10=20% |
| 4 |
+ |
3/4=75% |
3/10=30% |
| ... |
... |
... |
... |
而如果我們要使用單一個measure來evaluation搜尋的效能,
使用的通常為F-Score.
F-Score
F-score就是Precision與Recall的調和平均數(Harmonic Mean),
即 F = 2/(1/p + 1/r) = 2pr/(p+r)
而有時也會給予Precision及Recall不同的權重(weight)來進行計算,
即F = 2 / [a*(1/p)+(1-a)*(1/r)] = (b*b+1)pr / (b*b)p+r
若取b=1則F就等同於原來的式子,
若b>1,代表weight較偏重於Recall,
若0 前面所介紹的Precison & Recall 以及 F-score,針對的都是未排序的document, 但在實際的search engine中,所search的結果之間都是經過排序的, 因此就有人提出了 Eleven-point interpolated average precision, MAP(Mean Average Precision) 以及NDCG (normal discount cumulative gain). ROC Curve Y軸為True Positive (或稱為sensitivity或recall),而X軸為False Positive (或稱為1-Specificity), 一個Query的回傳結果分為兩個Part,一個為相關的set,另一個為不相關的set, 而True Positive指的就是相關的set在所有相關的document中佔有多大比例.[即 tp / (tp + tn)] False Positive則是指不相關的set在所有不相關的document中佔有多大的比例.[即 fp /(fp+fn)] 當一個system越好時,則它的ROC Curve會較偏向於左邊. 關於此點,我們固定Y軸來看,若一個System的 Recall越高,則有兩種狀況, 第一:回傳的Result不大,但Corpus中的Relevance document有很高的比例都被retrieval到了. 第二:回傳的Result很大,讓Corpus中的Relevance document有很高的比例都被retrieval到了. 如果為第一點,則False positive會很低,因為回傳的結果有大部份都是不相關,則整個ROC curve會 往左邊靠,但如果是第二點,則False positive會很高,因為回傳的結果有大部份都是不相關, 此時ROC curve會往右邊偏移. 因此可得知,若一個System較好,則其ROC Curve必定較為偏向右邊.(即起伏較快) 以下圖來講,C的curve在回傳較少的result時便可達到100% recall, 而A curve相對來說則需要較多的result才能達到100% recall. 因此C 這個System相對於A來說,其performance是較好的. (ref:http://clincancerres.aacrjournals.org/content/12/23/6985.full) Area under the ROC Curve (AUC): AUC即是計算ROC Curve的曲線下面積(即下圖的A區域), 以下圖來看,假設HR(C)代表的是回傳的結果中佔所有相關document的比例, 而FAR(C)則是代表回傳的結果中佔有不相關document的比例, 則此曲線下的面積值,即是HR(C)*FAR(C)再由0積分到1. 而其道理同ROC Curve,若AUC的value較高,則表示一個System可正確的區分 正確及錯誤的狀況. (ref:http://www.acadametrics.co.uk/roc.htm) Eleven-point interpolated average precision 11-point interpolated average precision是將Recall分為11個等級, 分別為 0.0 , 0.1 , 0.2 , 0.3 , ... , 1.0 , 分別表示全部資料的 0% , 10% , 20% , ... , 100% 而每個等級上的precision則取目前此點之後的Max precision,而為什麼要這樣子 , 因為在 11-point interpolated average precision上的一個基本假設是:如果我們可以增加View set中 relevance document 的比利的話, 那user都會想要去看更多的document. 由此方法所繪出的Precision-Recall Curve在某種程度上就可以看出不同方法在document ranking上的好壞. MAP (Mean average precision) MAP 不同於11-point interpolated average precision,它提供了使用single value來判讀 不同method在document ranking上的好壞, 它的計算方式如下: 1.首先先計算個別Query所retrieval出的average precision. 2.再將每個Query所得的average precision求其算數平均數(Arithmetic Mean),所得即為MAP. 在信息检索、分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常重要,因此最近根据网友的博客做了一个汇总。 准确率、召回率、F1 信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate),召回率也叫查全率,准确率也叫查准率,概念公式: 召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数 准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数 图示表示如下:
注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图: 如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。 所以,在两者都要求高的情况下,可以用F1来衡量。 公式基本上就是这样,但是如何算图1中的A、B、C、D呢?这需要人工标注,人工标注数据需要较多时间且枯燥,如果仅仅是做实验可以用用现成的语料。当然,还有一个办法,找个一个比较成熟的算法作为基准,用该算法的结果作为样本来进行比照,这个方法也有点问题,如果有现成的很好的算法,就不用再研究了。 AP和mAP(mean Average Precision) mAP是为解决P,R,F-measure的单点值局限性的。为了得到 一个能够反映全局性能的指标,可以看考察下图,其中两条曲线(方块点与圆点)分布对应了两个检索系统的准确率-召回率曲线 可以看出,虽然两个系统的性能曲线有所交叠但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。 从中我们可以 发现一点,如果一个系统的性能较好,其曲线应当尽可能的向上突出。 更加具体的,曲线与坐标轴之间的面积应当越大。 最理想的系统, 其包含的面积应当是1,而所有系统的包含的面积都应当大于0。这就是用以评价信息检索系统的最常用性能指标,平均准确率mAP其规范的定义如下:(其中P,R分别为准确率与召回率) ROC和AUC ROC和AUC是评价分类器的指标,上面第一个图的ABCD仍然使用,只是需要稍微变换。 回到ROC上来,ROC的全名叫做Receiver Operating Characteristic。 ROC关注两个指标 True Positive Rate ( TPR ) = TP / [ TP + FN] ,TPR代表能将正例分对的概率 False Positive Rate( FPR ) = FP / [ FP + TN] ,FPR代表将负例错分为正例的概率 在ROC 空间中,每个点的横坐标是FPR,纵坐标是TPR,这也就描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此我们可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0)(1,1),实际上(0, 0)和(1, 1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。如图所示。 用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。 于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance。 AUC计算工具: http://mark.goadrich.com/programs/AUC/ P/R和ROC是两个不同的评价指标和计算方式,一般情况下,检索用前者,分类、识别等用后者。 参考链接: http://www.vanjor.org/blog/2010/11/recall-precision/ http://bubblexc.com/y2011/148/ http://wenku.baidu.com/view/ef91f011cc7931b765ce15ec.html 以下内容绝大部分内容翻译自: Mu Zhu , Recall, Precision, and Average Precision. Working Paper 2004-09 Department of Statistics & Actuarial Science University of Waterloo. 1. 先介绍一些基础内容和符号说明 C:一个很大item的集合。 π:集合中相关的item的集合(π<< 1)。 t:算法所识别出的item的集合。 h(t):t中确实相关的item的集合,通常这部分称作命中(相反的是丢失) 下面看一些典型的“命中”曲线 假设其中相关item为5%。 hP(t)曲线是理想的曲线,几乎排在前面的所有的识别都命中了,直到5%,所有的相关item都耗尽了,曲线不再变化。 hR(t)曲线是随机选择的曲线 hA(t)和hB(t)是典型的识别曲线 (两条曲线相交是可能的) “命中曲线”能够很清楚地告诉我们一个模型或者是算法的性能好坏。例如,如果在任何时候,有 hA(t)>hB(t),则算法A毫无疑问比算法B出色;如果一般情况下,一条曲线总是随着t的增长而快速增长,则这个算法被认为是强壮的;特别的,一个最好的算法应该拥有最大地斜率,直到 t=π。 然而,我们需要的不仅是对算法好坏的评估和比较,而是要往好的方面来调整算法。经常,我们需要半人工地来产生一些算法的最优经验参数就像交叉验证。举例来说,对于 K - nearest-neighbor算法,我们必须选择最合适的K,然后通过交叉验证找出出色的值。因此,我们可以看到,我们更为需要的是一个评估值,而不是一条曲线。 两个数值化的评估方法通常是:recall和precision 2. 简单介绍 Recall 和 Precision 简单定义: Recall:在所有item中识别出相关item的概率。 Precision:在算法所识别出的item中,真正相关的概率。 形式化定义: 设 ω 是集合 C 中随机取出的一个元素 则 或者可以表示成 3. Recall 和 Precision 之间的关系 引理1: 证明: 根据贝叶斯公式,可以得到: 注意:在这里,我们将Precision和Recall都看作是关于自变量 t 的函数,因为一般来说,随着 t 的变化,算法的一些表现也会跟着变化。 h(t) , r(t) , p(t) 都看作是连续光滑的曲线,因为集合C足够大。 引理2: 1. r(0) = 0 r(1) = 1 2. r'(t) >= 0 (t∈[0,1]) 证明: 1. 显然,当 t = 0 时,Recall必然为0,因为没有item被检测; 当 t = 1 时,Recall必然等于1,因为所有的item都被检测了,那么也必定包括所有相关的item; 2. 显然,r (t+△t) > r(t) 或者 r (t+△t) = r(t) 所以,r (t+△t) >= r(t) 假设 t 在几乎任何一点都可导,则有: 引理2说明了 r(t) 是一个非递减函数,而且对于一个典型的识别算法来说,一般都有 r''(t) <= 0,即识别率是渐渐减缓的,直观上来说 随着 t 的上升,识别变得越来越困难。 假设1:假设 r(t) 是二次可微函数,则 r''(t) <= 0 , t∈[0,1]. 引理3:假设 p(t) 可微,若假设1成立,则 p'(t)<= 0 , t∈[0,1]. 证明: 根据中值定理,存在 S ∈[0,t]. 使得 r(t) - r(0) = r'(s) (t - 0) ∵ r(0) = 0; ∴ r(t) = r'(s)t 又根据假设1, 有 r''(t) <= 0 所以 r'(s) >= r'(t) (s<=t) 所以 r'(s)t >= r'(t)t 即 r(t) >= r'(t)t 则 p'(t) <= 0 根据之前所证明的,r'(t) >= 0,可以看出,Recall和Precision的确存在某些相互影响的关系。 (此证明基于假设1,r(t)的二阶导数小于等于0,即r''(t)是凸函数) 4. Average Precision(AP) 首先,Precision能被表示成Recall的函数,p(r), 因为 p(t) = π*r(t)/t ,具体见上所述。 AP的定义如下: 引理4:设r(t)可微函,则: 某些情况下,AP并不怎么直观,当 r'(t) = 0时,p(t)必然decreasing in t (无论在哪个区间内) 上面这句话不是特别理解。。。。 然而,因为dr为0,那么AP无论如何不会在此区间内发生变化。 下面举一些例子: 1. Random Selection: 假设 h(t) = π*t,即相关的比例在所有识别的比例中保持为 π 则 r(t) = h(t)/π = t 此时:AP = π 2. Perfect Detection: h(t)= t [0,π] h(t)=π (π,1] 这说明:前π个识别,全部命中,即h(t) = t,当π被耗尽时,h(t) = π,保持不变 这是最理想识别,也说明: r(t) = t/π [0,π] r(t) = 1 (π,1] 此时的AP = 1; 3. 实际应用中: 假设有n个测试item,将他们根据置信度又高到底排列后,计算: 其中,△r(i)表示后一次识别后,recall的变化量, p(i)可表示为:R/i ,其中R前i个item中,相关的item个数。 因此AP也可表示为: 其中,R表示测试集所有的relavant的item个数; n表示测试集中item的数量; Ij = 1,如果第j个item相关,否则,Ij = 0; Rj,前j个item中,相关的item个数; 下面看个例子: 假设这些item的置信度已经由高到底排列: 因此,算法A好于算法B。 由此也可以看出,AP这个衡量标准更偏爱识别得早的算法。 后略。 希望大家帮忙改正。 1.Precision & Recall 2.F-Score 3.ROC Curve ( Receiver Operatng Characteristics) 4.Area under the ROC curve 5.Eleven-point interpolated average precision 5.MAP (Mean average precision) Precision & Recall 在Information Retrieval 中,最直接用來衡量一個model的效能就是Precision & Recall Precision : Tp / Tp + Fp , 即表示在所有Retrieve出的document中,有多少是Relevance. Recall : Tp / Tp + Tn , 即表示在所有Relevance的document中,有多少是被Retrieve到. 在理論上,Precision跟Recall之間是無絕對的對應關係, 但在實際應用上,通常Precision會隨著Retrieval document越多而遞減,而Recall則會遞增. For Example(假設database中,relevance的document數目為10) document Positive/Negtive Precision Recall 1 + 1/1=100% 1/10=10% 2 + 2/2=100% 2/10=20% 3 - 2/3=67% 2/10=20% 4 + 3/4=75% 3/10=30% ... ... ... ... 而如果我們要使用單一個measure來evaluation搜尋的效能, 使用的通常為F-Score. F-Score F-score就是Precision與Recall的調和平均數(Harmonic Mean), 即 F = 2/(1/p + 1/r) = 2pr/(p+r) 而有時也會給予Precision及Recall不同的權重(weight)來進行計算, 即F = 2 / [a*(1/p)+(1-a)*(1/r)] = (b*b+1)pr / (b*b)p+r 若取b=1則F就等同於原來的式子, 若b>1,代表weight較偏重於Recall, 若0 前面所介紹的Precison & Recall 以及 F-score,針對的都是未排序的document, 但在實際的search engine中,所search的結果之間都是經過排序的, 因此就有人提出了 Eleven-point interpolated average precision, MAP(Mean Average Precision) 以及NDCG (normal discount cumulative gain). ROC Curve Y軸為True Positive (或稱為sensitivity或recall),而X軸為False Positive (或稱為1-Specificity), 一個Query的回傳結果分為兩個Part,一個為相關的set,另一個為不相關的set, 而True Positive指的就是相關的set在所有相關的document中佔有多大比例.[即 tp / (tp + tn)] False Positive則是指不相關的set在所有不相關的document中佔有多大的比例.[即 fp /(fp+fn)] 當一個system越好時,則它的ROC Curve會較偏向於左邊. 關於此點,我們固定Y軸來看,若一個System的 Recall越高,則有兩種狀況, 第一:回傳的Result不大,但Corpus中的Relevance document有很高的比例都被retrieval到了. 第二:回傳的Result很大,讓Corpus中的Relevance document有很高的比例都被retrieval到了. 如果為第一點,則False positive會很低,因為回傳的結果有大部份都是不相關,則整個ROC curve會 往左邊靠,但如果是第二點,則False positive會很高,因為回傳的結果有大部份都是不相關, 此時ROC curve會往右邊偏移. 因此可得知,若一個System較好,則其ROC Curve必定較為偏向右邊.(即起伏較快) 以下圖來講,C的curve在回傳較少的result時便可達到100% recall, 而A curve相對來說則需要較多的result才能達到100% recall. 因此C 這個System相對於A來說,其performance是較好的. (ref:http://clincancerres.aacrjournals.org/content/12/23/6985.full) Area under the ROC Curve (AUC): AUC即是計算ROC Curve的曲線下面積(即下圖的A區域), 以下圖來看,假設HR(C)代表的是回傳的結果中佔所有相關document的比例, 而FAR(C)則是代表回傳的結果中佔有不相關document的比例, 則此曲線下的面積值,即是HR(C)*FAR(C)再由0積分到1. 而其道理同ROC Curve,若AUC的value較高,則表示一個System可正確的區分 正確及錯誤的狀況. (ref:http://www.acadametrics.co.uk/roc.htm) Eleven-point interpolated average precision 11-point interpolated average precision是將Recall分為11個等級, 分別為 0.0 , 0.1 , 0.2 , 0.3 , ... , 1.0 , 分別表示全部資料的 0% , 10% , 20% , ... , 100% 而每個等級上的precision則取目前此點之後的Max precision,而為什麼要這樣子 , 因為在 11-point interpolated average precision上的一個基本假設是:如果我們可以增加View set中 relevance document 的比利的話, 那user都會想要去看更多的document. 由此方法所繪出的Precision-Recall Curve在某種程度上就可以看出不同方法在document ranking上的好壞. MAP (Mean average precision) MAP 不同於11-point interpolated average precision,它提供了使用single value來判讀 不同method在document ranking上的好壞, 它的計算方式如下: 1.首先先計算個別Query所retrieval出的average precision. 2.再將每個Query所得的average precision求其算數平均數(Arithmetic Mean),所得即為MAP. 在信息检索、分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常重要,因此最近根据网友的博客做了一个汇总。 准确率、召回率、F1 信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate),召回率也叫查全率,准确率也叫查准率,概念公式: 召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数 准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数 图示表示如下:
注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图: 如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。 所以,在两者都要求高的情况下,可以用F1来衡量。 公式基本上就是这样,但是如何算图1中的A、B、C、D呢?这需要人工标注,人工标注数据需要较多时间且枯燥,如果仅仅是做实验可以用用现成的语料。当然,还有一个办法,找个一个比较成熟的算法作为基准,用该算法的结果作为样本来进行比照,这个方法也有点问题,如果有现成的很好的算法,就不用再研究了。 AP和mAP(mean Average Precision) mAP是为解决P,R,F-measure的单点值局限性的。为了得到 一个能够反映全局性能的指标,可以看考察下图,其中两条曲线(方块点与圆点)分布对应了两个检索系统的准确率-召回率曲线 可以看出,虽然两个系统的性能曲线有所交叠但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。 从中我们可以 发现一点,如果一个系统的性能较好,其曲线应当尽可能的向上突出。 更加具体的,曲线与坐标轴之间的面积应当越大。 最理想的系统, 其包含的面积应当是1,而所有系统的包含的面积都应当大于0。这就是用以评价信息检索系统的最常用性能指标,平均准确率mAP其规范的定义如下:(其中P,R分别为准确率与召回率) ROC和AUC ROC和AUC是评价分类器的指标,上面第一个图的ABCD仍然使用,只是需要稍微变换。 回到ROC上来,ROC的全名叫做Receiver Operating Characteristic。 ROC关注两个指标 True Positive Rate ( TPR ) = TP / [ TP + FN] ,TPR代表能将正例分对的概率 False Positive Rate( FPR ) = FP / [ FP + TN] ,FPR代表将负例错分为正例的概率 在ROC 空间中,每个点的横坐标是FPR,纵坐标是TPR,这也就描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此我们可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0)(1,1),实际上(0, 0)和(1, 1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。如图所示。 用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。 于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance。 AUC计算工具: http://mark.goadrich.com/programs/AUC/ P/R和ROC是两个不同的评价指标和计算方式,一般情况下,检索用前者,分类、识别等用后者。 参考链接: http://www.vanjor.org/blog/2010/11/recall-precision/ http://bubblexc.com/y2011/148/ http://wenku.baidu.com/view/ef91f011cc7931b765ce15ec.html 以下内容绝大部分内容翻译自: Mu Zhu , Recall, Precision, and Average Precision. Working Paper 2004-09 Department of Statistics & Actuarial Science University of Waterloo. 1. 先介绍一些基础内容和符号说明 C:一个很大item的集合。 π:集合中相关的item的集合(π<< 1)。 t:算法所识别出的item的集合。 h(t):t中确实相关的item的集合,通常这部分称作命中(相反的是丢失) 下面看一些典型的“命中”曲线 假设其中相关item为5%。 hP(t)曲线是理想的曲线,几乎排在前面的所有的识别都命中了,直到5%,所有的相关item都耗尽了,曲线不再变化。 hR(t)曲线是随机选择的曲线 hA(t)和hB(t)是典型的识别曲线 (两条曲线相交是可能的) “命中曲线”能够很清楚地告诉我们一个模型或者是算法的性能好坏。例如,如果在任何时候,有 hA(t)>hB(t),则算法A毫无疑问比算法B出色;如果一般情况下,一条曲线总是随着t的增长而快速增长,则这个算法被认为是强壮的;特别的,一个最好的算法应该拥有最大地斜率,直到 t=π。 然而,我们需要的不仅是对算法好坏的评估和比较,而是要往好的方面来调整算法。经常,我们需要半人工地来产生一些算法的最优经验参数就像交叉验证。举例来说,对于 K - nearest-neighbor算法,我们必须选择最合适的K,然后通过交叉验证找出出色的值。因此,我们可以看到,我们更为需要的是一个评估值,而不是一条曲线。 两个数值化的评估方法通常是:recall和precision 2. 简单介绍 Recall 和 Precision 简单定义: Recall:在所有item中识别出相关item的概率。 Precision:在算法所识别出的item中,真正相关的概率。 形式化定义: 设 ω 是集合 C 中随机取出的一个元素 则 或者可以表示成 3. Recall 和 Precision 之间的关系 引理1: 证明: 根据贝叶斯公式,可以得到: 注意:在这里,我们将Precision和Recall都看作是关于自变量 t 的函数,因为一般来说,随着 t 的变化,算法的一些表现也会跟着变化。 h(t) , r(t) , p(t) 都看作是连续光滑的曲线,因为集合C足够大。 引理2: 1. r(0) = 0 r(1) = 1 2. r'(t) >= 0 (t∈[0,1]) 证明: 1. 显然,当 t = 0 时,Recall必然为0,因为没有item被检测; 当 t = 1 时,Recall必然等于1,因为所有的item都被检测了,那么也必定包括所有相关的item; 2. 显然,r (t+△t) > r(t) 或者 r (t+△t) = r(t) 所以,r (t+△t) >= r(t) 假设 t 在几乎任何一点都可导,则有: 引理2说明了 r(t) 是一个非递减函数,而且对于一个典型的识别算法来说,一般都有 r''(t) <= 0,即识别率是渐渐减缓的,直观上来说 随着 t 的上升,识别变得越来越困难。 假设1:假设 r(t) 是二次可微函数,则 r''(t) <= 0 , t∈[0,1]. 引理3:假设 p(t) 可微,若假设1成立,则 p'(t)<= 0 , t∈[0,1]. 证明: 根据中值定理,存在 S ∈[0,t]. 使得 r(t) - r(0) = r'(s) (t - 0) ∵ r(0) = 0; ∴ r(t) = r'(s)t 又根据假设1, 有 r''(t) <= 0 所以 r'(s) >= r'(t) (s<=t) 所以 r'(s)t >= r'(t)t 即 r(t) >= r'(t)t 则 p'(t) <= 0 根据之前所证明的,r'(t) >= 0,可以看出,Recall和Precision的确存在某些相互影响的关系。 (此证明基于假设1,r(t)的二阶导数小于等于0,即r''(t)是凸函数) 4. Average Precision(AP) 首先,Precision能被表示成Recall的函数,p(r), 因为 p(t) = π*r(t)/t ,具体见上所述。 AP的定义如下: 引理4:设r(t)可微函,则: 某些情况下,AP并不怎么直观,当 r'(t) = 0时,p(t)必然decreasing in t (无论在哪个区间内) 上面这句话不是特别理解。。。。 然而,因为dr为0,那么AP无论如何不会在此区间内发生变化。 下面举一些例子: 1. Random Selection: 假设 h(t) = π*t,即相关的比例在所有识别的比例中保持为 π 则 r(t) = h(t)/π = t 此时:AP = π 2. Perfect Detection: h(t)= t [0,π] h(t)=π (π,1] 这说明:前π个识别,全部命中,即h(t) = t,当π被耗尽时,h(t) = π,保持不变 这是最理想识别,也说明: r(t) = t/π [0,π] r(t) = 1 (π,1] 此时的AP = 1; 3. 实际应用中: 假设有n个测试item,将他们根据置信度又高到底排列后,计算: 其中,△r(i)表示后一次识别后,recall的变化量, p(i)可表示为:R/i ,其中R前i个item中,相关的item个数。 因此AP也可表示为: 其中,R表示测试集所有的relavant的item个数; n表示测试集中item的数量; Ij = 1,如果第j个item相关,否则,Ij = 0; Rj,前j个item中,相关的item个数; 下面看个例子: 假设这些item的置信度已经由高到底排列: 因此,算法A好于算法B。 由此也可以看出,AP这个衡量标准更偏爱识别得早的算法。 后略。 希望大家帮忙改正。 1.Precision & Recall 2.F-Score 3.ROC Curve ( Receiver Operatng Characteristics) 4.Area under the ROC curve 5.Eleven-point interpolated average precision 5.MAP (Mean average precision) Precision & Recall 在Information Retrieval 中,最直接用來衡量一個model的效能就是Precision & Recall Precision : Tp / Tp + Fp , 即表示在所有Retrieve出的document中,有多少是Relevance. Recall : Tp / Tp + Tn , 即表示在所有Relevance的document中,有多少是被Retrieve到. 在理論上,Precision跟Recall之間是無絕對的對應關係, 但在實際應用上,通常Precision會隨著Retrieval document越多而遞減,而Recall則會遞增. For Example(假設database中,relevance的document數目為10) document Positive/Negtive Precision Recall 1 + 1/1=100% 1/10=10% 2 + 2/2=100% 2/10=20% 3 - 2/3=67% 2/10=20% 4 + 3/4=75% 3/10=30% ... ... ... ... 而如果我們要使用單一個measure來evaluation搜尋的效能, 使用的通常為F-Score. F-Score F-score就是Precision與Recall的調和平均數(Harmonic Mean), 即 F = 2/(1/p + 1/r) = 2pr/(p+r) 而有時也會給予Precision及Recall不同的權重(weight)來進行計算, 即F = 2 / [a*(1/p)+(1-a)*(1/r)] = (b*b+1)pr / (b*b)p+r 若取b=1則F就等同於原來的式子, 若b>1,代表weight較偏重於Recall, 若0 前面所介紹的Precison & Recall 以及 F-score,針對的都是未排序的document, 但在實際的search engine中,所search的結果之間都是經過排序的, 因此就有人提出了 Eleven-point interpolated average precision, MAP(Mean Average Precision) 以及NDCG (normal discount cumulative gain). ROC Curve Y軸為True Positive (或稱為sensitivity或recall),而X軸為False Positive (或稱為1-Specificity), 一個Query的回傳結果分為兩個Part,一個為相關的set,另一個為不相關的set, 而True Positive指的就是相關的set在所有相關的document中佔有多大比例.[即 tp / (tp + tn)] False Positive則是指不相關的set在所有不相關的document中佔有多大的比例.[即 fp /(fp+fn)] 當一個system越好時,則它的ROC Curve會較偏向於左邊. 關於此點,我們固定Y軸來看,若一個System的 Recall越高,則有兩種狀況, 第一:回傳的Result不大,但Corpus中的Relevance document有很高的比例都被retrieval到了. 第二:回傳的Result很大,讓Corpus中的Relevance document有很高的比例都被retrieval到了. 如果為第一點,則False positive會很低,因為回傳的結果有大部份都是不相關,則整個ROC curve會 往左邊靠,但如果是第二點,則False positive會很高,因為回傳的結果有大部份都是不相關, 此時ROC curve會往右邊偏移. 因此可得知,若一個System較好,則其ROC Curve必定較為偏向右邊.(即起伏較快) 以下圖來講,C的curve在回傳較少的result時便可達到100% recall, 而A curve相對來說則需要較多的result才能達到100% recall. 因此C 這個System相對於A來說,其performance是較好的. (ref:http://clincancerres.aacrjournals.org/content/12/23/6985.full) Area under the ROC Curve (AUC): AUC即是計算ROC Curve的曲線下面積(即下圖的A區域), 以下圖來看,假設HR(C)代表的是回傳的結果中佔所有相關document的比例, 而FAR(C)則是代表回傳的結果中佔有不相關document的比例, 則此曲線下的面積值,即是HR(C)*FAR(C)再由0積分到1. 而其道理同ROC Curve,若AUC的value較高,則表示一個System可正確的區分 正確及錯誤的狀況. (ref:http://www.acadametrics.co.uk/roc.htm) Eleven-point interpolated average precision 11-point interpolated average precision是將Recall分為11個等級, 分別為 0.0 , 0.1 , 0.2 , 0.3 , ... , 1.0 , 分別表示全部資料的 0% , 10% , 20% , ... , 100% 而每個等級上的precision則取目前此點之後的Max precision,而為什麼要這樣子 , 因為在 11-point interpolated average precision上的一個基本假設是:如果我們可以增加View set中 relevance document 的比利的話, 那user都會想要去看更多的document. 由此方法所繪出的Precision-Recall Curve在某種程度上就可以看出不同方法在document ranking上的好壞. MAP (Mean average precision) MAP 不同於11-point interpolated average precision,它提供了使用single value來判讀 不同method在document ranking上的好壞, 它的計算方式如下: 1.首先先計算個別Query所retrieval出的average precision. 2.再將每個Query所得的average precision求其算數平均數(Arithmetic Mean),所得即為MAP.
信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
分类: 1.自然语言处理/机器学习
![]()
基础学习笔记——Recall, Precision, and Average Precision
所以 r'(t) >= 0 ( t∈[0,1] )
所以说,单用这两个之中的某一个来评估和比较都不太合适,下面介绍的AP将会同时考虑Recall和Precision,因此常被用来作为衡量和评估的标准。
IR Evaluation
信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
分类: 1.自然语言处理/机器学习
![]()
基础学习笔记——Recall, Precision, and Average Precision
所以 r'(t) >= 0 ( t∈[0,1] )
所以说,单用这两个之中的某一个来评估和比较都不太合适,下面介绍的AP将会同时考虑Recall和Precision,因此常被用来作为衡量和评估的标准。
IR Evaluation