利用tf-idf词向量和卷积神经网络做文本多分类
首先了解一下tf-idf,通过一段小代码
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = TfidfVectorizer()
x= vectorizer.fit_transform(corpus)
a=x.toarray()
print(type(x))
print(type(a))输出结果:
import numpy as np
import pandas as pd
import jieba
import re
np.random.seed(1337) # for reproducibility
from keras.datasets import mnist
from keras.utils import np_utils
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Activation, Convolution1D, MaxPooling1D, Flatten, Dropout
from keras.optimizers import Adam
data_train=pd.read_excel(r'C:\Users\admin\Desktop\text_cf\zzyw.xlsx',sheetname='训练集')
df_data=data_train[['一级','二级','三级','四级','五级','六级','投诉详情描述']]
# 导入标签集
df_lables=pd.read_excel(r'C:\Users\admin\Desktop\text_cf\zzyw.xlsx',sheetname='label')
df_lables.fillna('',inplace=True)
df_lables['标签'] = df_lables['一级'] + df_lables['二级'] + df_lables['三级'] + df_lables['四级'] + df_lables['五级'] + df_lables['六级']
lables_list = df_lables['标签'].tolist()
print('3:分类标签字段汇合成功')
df_data.fillna('',inplace=True)
df_data['标签'] = df_data['一级'] + df_data['二级'] + df_data['三级'] + df_data['四级'] + df_data['五级'] + df_data['六级']
df_data = df_data[df_data['投诉详情描述'] != '']
#标签表预处理
dig_lables = dict(enumerate(lables_list))
lable_dig = dict((lable,dig) for dig, lable in dig_lables.items())
print(lable_dig)
# 数据集标签预处理
df_data['标签_数字'] = df_data['标签'].apply(lambda lable: lable_dig[lable])
print('4:数据预处理')
print(len(lable_dig))
# 测试集标签预处理
data_test=pd.read_excel(r'C:\Users\admin\Desktop\text_cf\zzyw.xlsx',sheetname='测试集')
data_test.fillna('',inplace=True)
data_test['标签'] = data_test['一级'] + data_test['二级'] + data_test['三级'] + data_test['四级'] + data_test['五级'] + data_test['六级']
data_test = data_test[data_test['投诉详情描述'] != '']
def seg_sentences(sentence):
# 去掉特殊字符
sentence = re.sub(u"([^\u4e00-\u9fa5\u0030-\u0039\u0041-\u005a\u0061-\u007a])","",sentence)
sentence_seged = list(jieba.cut(sentence.strip()))
return sentence_seged
df_data['投诉分词']=df_data['投诉详情描述'].apply(seg_sentences)
df_data['投诉分词数量']=df_data['投诉分词'].apply(lambda x: len(x))
data_test['投诉分词']=data_test['投诉详情描述'].apply(seg_sentences)
data_test['投诉分词数量']=data_test['投诉分词'].apply(lambda x: len(x))
corpus =pd.concat([df_data['投诉分词'],data_test['投诉分词']]).astype(str).values
vectorizer = TfidfVectorizer()
vectorizer=vectorizer.fit(corpus)
x= vectorizer.transform(df_data['投诉分词'].astype(str).values)
y= vectorizer.transform(data_test['投诉分词'].astype(str).values)
num_classes = len(dig_lables)
train_lables = to_categorical(df_data['标签_数字'],num_classes=num_classes)
a=x.toarray()
#因为我这边x.shape是(9859, 8120)
X_train = a.reshape(-1,1624, 5)
b=y.toarray()
X_test = b.reshape(-1,1624, 5)
model = Sequential()
model.add(Convolution1D(32,5,
border_mode='same', # Padding method
input_shape=(1624, 5) # height & width
))
model.add(Activation('relu'))
model.add(MaxPooling1D(
pool_size=2,
strides=2,
border_mode='same', # Padding method
))
model.add(Convolution1D(64, 5, border_mode='same'))
model.add(Activation('relu'))
model.add(MaxPooling1D(pool_size=2, border_mode='same'))
model.add(Dropout(0.3))
model.add(Flatten())
model.add(Dropout(0.3))
model.add(Dense(4096))
model.add(Activation('relu'))
model.add(Dense(1024))
model.add(Activation('relu'))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
adam = Adam(lr=1e-4)
model.compile(optimizer=adam,
loss='categorical_crossentropy',
metrics=['accuracy'])
print('Training ------------')
# Another way to train the model
print(model.summary())
model.fit(X_train,train_lables, nb_epoch=8, batch_size=32,)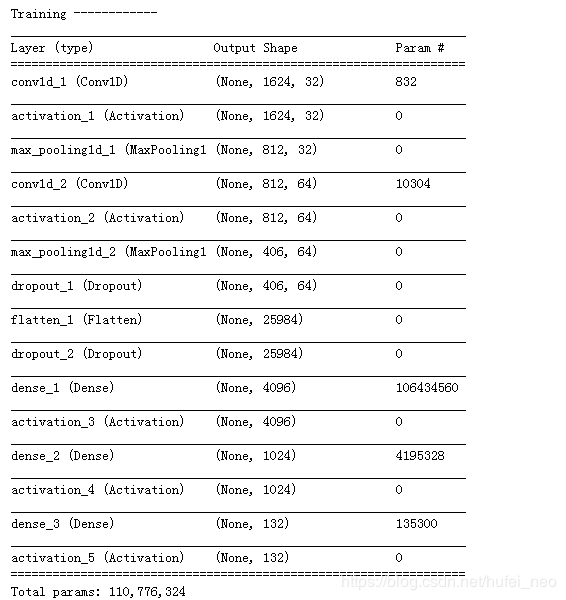
参数的计算方式是 : 832=32*5*5+32
10304=64*32*5+64
106434560=25984*4096+4096
4195328=4096*1024+1024
135300=1024*132+132
测试
# Evaluate the model with the metrics we defined earlier
y_test_evl=model.predict(X_test)
c=[i.argmax() for i in y_test_evl]
data_test['分类结果_预测'] = [dig_lables[dig] for dig in c]
# 准确率
from sklearn import metrics
metrics.accuracy_score(data_test['标签'],data_test['分类结果_预测'])