RANK、DENSE_RANK以及ROW_NUMBER区别
场景
数据库查询中,很多时候都会遇到对数据进行分组,然后组内排序加序号的需求。应用
对于组内排序一般有三个函数可供使用,它们是RANK()、DENSE_RANK()以及ROW_NUMBER()。它们都是对分过组的数据排序加序号,不过又有各自的区别。
语法
它们的语法是一样的,如下:
ROW_NUMBER() OVER([PARTITION BY col1] ORDER BY col2)
DENSE_RANK() OVER([PARTITION BY col1] ORDER BY col2)
RANK() OVER([PARTITION BY col1] ORDER BY col2)区别
三个函数都是按照col1分组内从1开始排序其中,ROW_NUMBER() 是没有重复值的排序(即使两条记录相同,序号也不重复的),不会有同名次。
DENSE_RANK() 是连续的排序,两个第二名仍然跟着第三名。
RANK() 是跳跃排序,两个第二名下来就是第四名。
使用
下面用一个例子代码来说明一下区别。在例子中我们对员工工资按部门分组进行排序。注意rank的序号变化。WITH workers AS(
SELECT 'DOM1' dept, 'zhangsan' names , 23 age, 4000 salaries FROM dual UNION ALL
SELECT 'DOM1' dept, 'lisi' names , 35 age, 9000 salaries FROM dual UNION ALL
SELECT 'DOM1' dept, 'zhangchen' names, 35 age, 9000 salaries FROM dual UNION ALL
SELECT 'DOM1' dept, 'qiansi' names , 35 age, 4000 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'wangwu' names , 26 age, 6500 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'maliu' names , 28 age, 6000 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'zhaoqi' names , 26 age, 5000 salaries FROM dual UNION ALL
SELECT 'DOM1' dept, 'liba' names , 23 age, 3000 salaries FROM dual
)
SELECT s.names,s.salaries,s.names,dept, ROW_NUMBER() OVER(PARTITION BY dept ORDER BY salaries DESC)rank FROM workers s;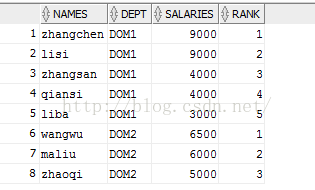
SELECT s.names, dept, s.salaries, DENSE_RANK() OVER(PARTITION BY dept ORDER BY salaries DESC)rank FROM workers s;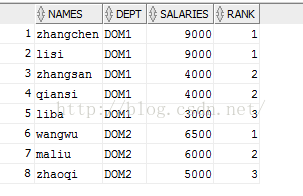
SELECT s.names, dept, s.salaries, RANK() OVER(PARTITION BY dept ORDER BY salaries DESC)rank FROM workers s;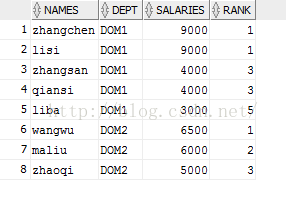
总之,使用的时候一定要看自己的需要。