Python爬虫:新浪微博用户的微博内容和图片
import requests
import urllib
import time
import os
from tqdm import tqdm
from urllib.parse import urlencode
from pyquery import PyQuery as pq
import datetime
host = 'm.weibo.cn'
base_url = 'https://%s/api/container/getIndex?' % host
user_agent = 'User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1 wechatdevtools/0.7.0 MicroMessenger/6.3.9 Language/zh_CN webview/0'#这里的user_agent是网上找的
user_id = str(3261134763)#这串数字就是用户id
headers = {
'Host': host,
'Referer': 'https://m.weibo.cn/u/%s'%user_id,
'User-Agent': user_agent
}
def get_single_page(page):
params = {
'type': 'uid',
'value': 1665372775,
'containerid': int('107603' + user_id),#containerid就是微博用户id前面加上107603
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('抓取错误'+e.args)
# 解析页面返回的json数据
def analysis_page(json,pic_filebagPath):#保存图片的文件夹路径
items = json.get('data').get('cards')
for item in items:
item = item.get('mblog')
if item:
data = {
'created_at': item.get('created_at'),#微博创建日期
'text': pq(item.get("text")).text(), # 仅提取内容中的文本
'attitudes': item.get('attitudes_count'),#点赞数
'comments': item.get('comments_count'),#评论数
'reposts': item.get('reposts_count')#转发数
}
base_data[len(base_data)] = data#把得到的数据字典存入总字典
if pic_choice == 'y':#如果选择保存图片
pics = item.get('pics')
if pics:
for pic in pics:
picture_url = pic.get('large').get('url')#得到原图地址
pid = pic.get('pid')#图片id
pic_name = pid[25:]#构建保存图片文件名,timestr_standard是一个把微博的created_at字符串转换为‘XXXX-XX-XX’形式日期的一个函数
download_pics(picture_url,pic_name,pic_filebagPath)#下载原图
def download_pics(pic_url,pic_name,pic_filebagPath): #pic_url大图地址,pic_name保存图片的文件名
pic_filePath = pic_filebagPath + '\\'
try:
if pic_url.endswith('.jpg'):#保存jpg图片
f = open(pic_filePath + str(pic_name)+".jpg", 'wb')
if pic_url.endswith('.gif'):#保存gif图片
f = open(pic_filePath + str(pic_name)+".gif", 'wb')
f.write((urllib.request.urlopen(pic_url)).read())
f.close()
except Exception as e:
print(pic_name+" error"+e)
time.sleep(0.1)#下载间隙
if __name__ == '__main__':
base_data = {}
page = input('请输入你要爬取的页数') # 可输入爬取页数,或者输入‘all’爬取所有微博
pic_choice = input('是否需要存储图片?y/n') # 选择是否保存图片
time_start = time.time()
try:
json = get_single_page(1)
screen_name = json.get('data').get('cards')[0].get('mblog').get('user').get('screen_name') # 博主昵称
total = json.get('data').get('cardlistInfo').get('total') # 博主微博总条数
if pic_choice == 'y': # 如果选择保存图片,则分配图片保存路径
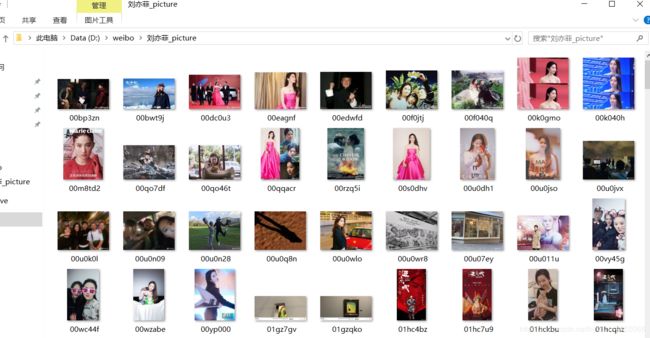
pic_filebagPath = 'D:weibo\\%s_picture' % screen_name
os.makedirs(pic_filebagPath) # 建立文件夹
else:
pic_filebagPath = None # 选择不保存文件夹则不分配路径
if page == 'all': # 寻找总条数
page = total // 10
while get_single_page(page).get('ok') == 1:
page = page + 1
print('总页数为:%s' % page)
page = int(page) + 1
for page in tqdm(range(1, page)): # 抓取数据
json = get_single_page(page)
analysis_page(json, pic_filebagPath)
except Exception as e:
print('error:'+e)
finally:
base_dataPath = 'D:weibo\\base_data_%s.txt' % screen_name # base_data保存地址和文件名
f = open(base_dataPath, 'w+', encoding='utf-8')
for i in range(len(base_data)):
s = str(base_data[i])+'\n'
f.write(s)
f.close()