odps编写UDF 利用Gson提取JSON
开头:
楼主近期参加了阿里云的平台赛,安全云计算。使用阿里云的odps平台进行数据转换,因为原始数据是json字符串,因此需要自己编写UDF进行json字符串的提取
搜索良久,自己总结了json提取的整个平台操作和编写流程。在此做一些分享,希望能帮助像我一样的新手更快入手云平台上,希望更多人参加云计算比赛,祝阿里云平台发展越来越好。
思路:
1.本地编译udf需要导入官方的maven骨架-------第一章
2. 因为变量都是如
[{\"time\":7149,\"type\":0,\"target\":\"****\"},{\"time\":5718,\"type\":1,\"target\":\"****\"}]
的包含多个对象的json字符串,我们希望返回所有对象的time数据的均值,方差等
因此编写UDF,利用java的GSON包,提取json返回统计数据组成的字符串(因为udf一次只能返回一个String结果,返回格式为"time_avg time_var type_count")-------第二章
3. 数加平台上利用split_part语句,将第二步中得到的空格+统计数据的字符串,转换为一个个的统计变量-----第三章
第一章
安装maven
下载maven
http://mirrors.hust.edu.cn/apache/maven/maven-3/3.3.9/binaries/
配置 maven 环境变量:
Win10:我的电脑---右键属性----系统高级设置---高级---环境变量
系统变量中新建:MAVEN_HOME = D:\Development\apache-maven-3.0.4
系统变量path添加:path = %MAVEN_HOME%\bin
如果发现报错,可能是没有安装java,没有设置JAVA_HOME
系统变量新建JAVA_HOME 值为C:\Program Files\Java\jdk1.6.0_23
打开 cmd,在里面敲:mvn –version
显示如下即正确
Apache Maven 3.3.9(bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015-11-11T00:41:47+08:00)
Maven home: G:\apache-maven-3.3.9\bin\..
Java version: 1.8.0_102, vendor: OracleCorporation
Java home: C:\ProgramFiles\Java\jdk1.8.0_102\jre
Default locale: zh_CN, platform encoding:GBK
OS name: "windows 10", version:"10.0", arch: "amd64", family: "dos"
配置eclipse 的maven环境
参考http://jingyan.baidu.com/article/60ccbceb01de4d64cbb19756.html
1) 添加远程repository
Eclipse中依次点击window-> Preferences -> Maven -> Arthetypes ,在打开的对话框中点击 Add Remote Catalog按钮:
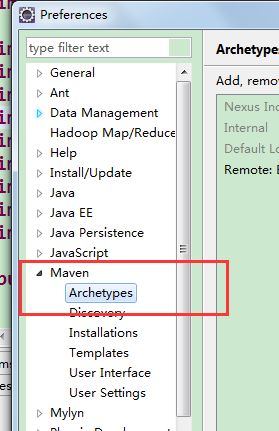
图38添加远程repository
在打开的对话框中, Catalog File 填入 http://maven.sdk.de.yushanfang.com/SNAPSHOT,Description 填入Base Archetypes
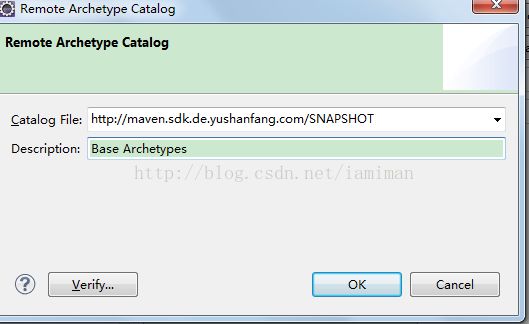
图39 配置远程repository
新建项目
1) 在Eclipse中依次点击File -> New -> Project.选择maven项目:
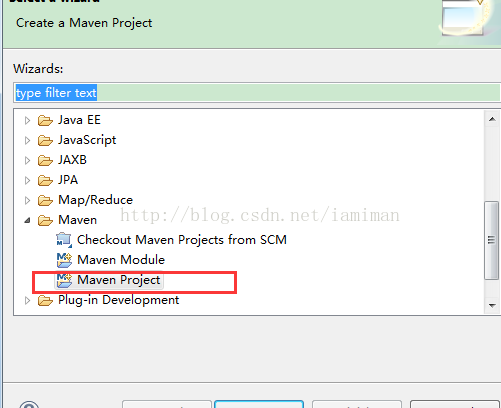
图40 选择maven工程
2) 配置并点击
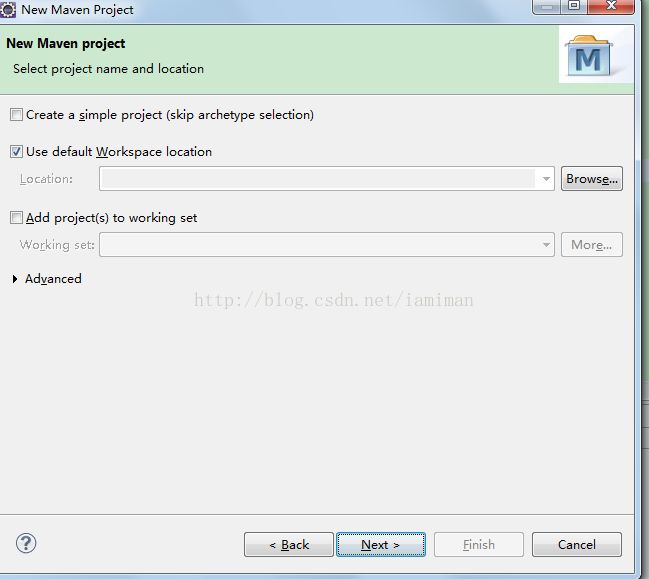
图41 Maven项目配置(1)
3) 按照下图选择:
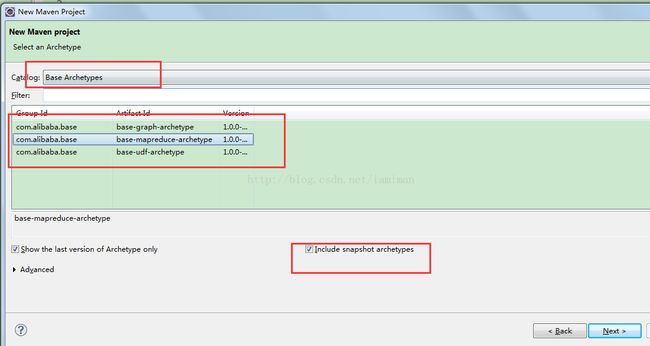
图42 项目配置(2)
4) 点击
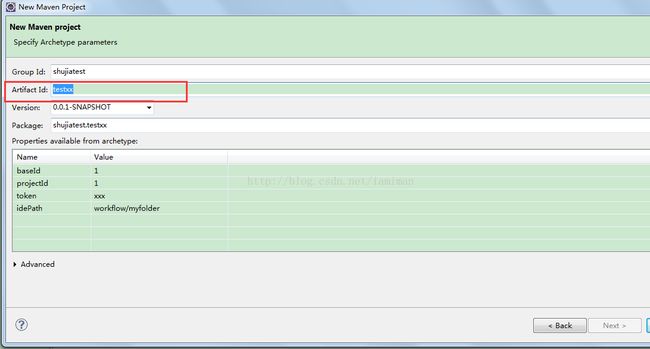
图43 项目配置(3)
至此环境搭建OK。
编写UDF
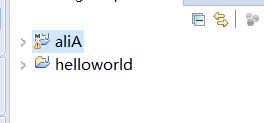
我的artifact ID 为aliA
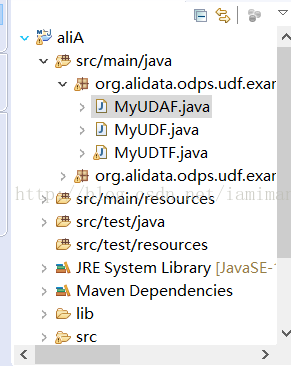
打开后发现
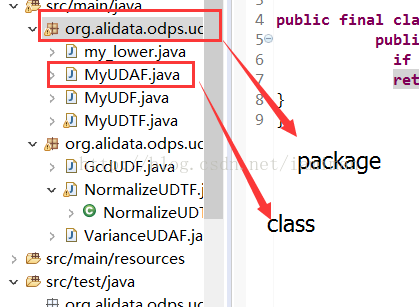
右键package处新建一个class,命名为my_lower
内容写着
packageorg.alidata.odps.udf.examples;
importcom.aliyun.odps.udf.UDF;
publicfinalclass my_lowerextends UDF {
public String evaluate(Strings) {
if (s ==null) {returnnull; }
returns.toLowerCase();
}
}
然后保存,右键该jave文件(如果是单独一个函数class,则就export该java,如果是一个package中多个class,应该要上传整个package
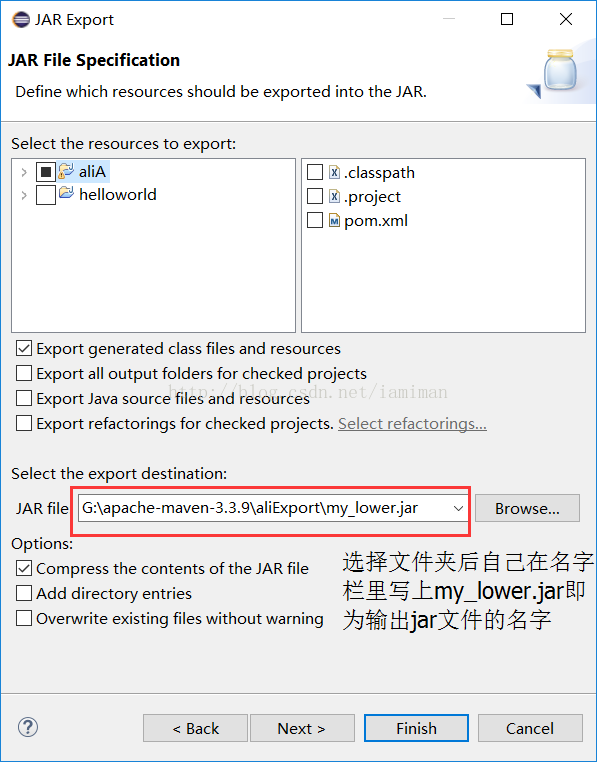
接着finish即可
平台加载使用jar
l 上传资源到数加平台;进入IDE后,点击加号->上传资源:
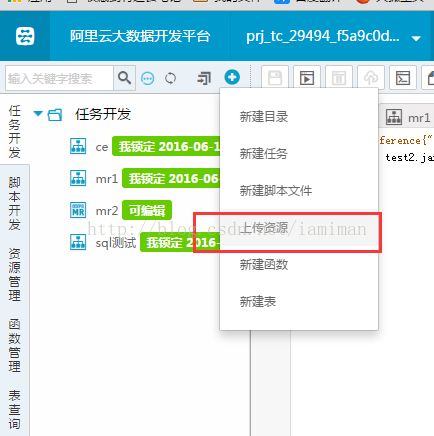
图49 上传资源按钮
l 输入名称、资源类型和上传的jar包,并提交:
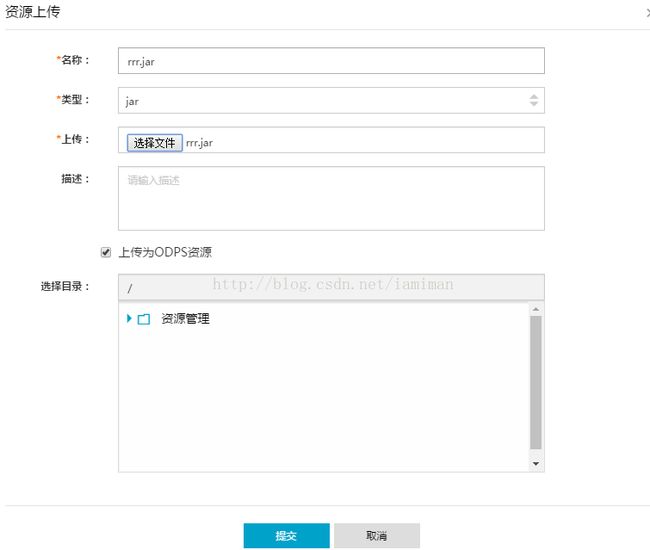
图50 上传资源配置
l 点击+号并点击<新建任务>:
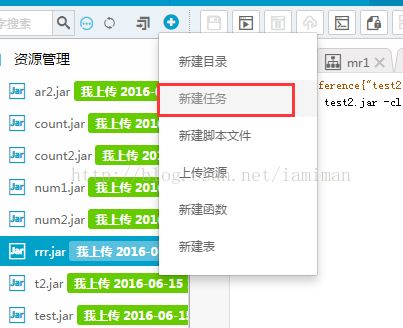
图51 新建任务按钮
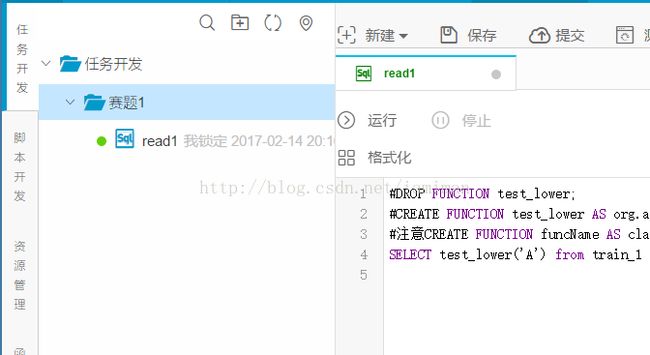
在任务开发处新建了目录赛题1 然后继续新建一个sql的任务
写入:
CREATE FUNCTION test_lower ASorg.alidata.odps.udf.examples.my_lower USING my_lower.jar;
#DROP FUNCTION test_lower;#丢弃函数
#注意CREATE FUNCTIONfuncName AS class_name from jar_name 其中的class_name必须
SELECT test_lower('A') from train_1 ;
即可
第二章:
第一章最后部分编写了一个,将传入字符串转换为小写并返回,的UDF。在比赛中遇到的json字符串为对象数组,在odps中,需要使用com.google.gson.Gson包,从json字符串中提取信息。
举例:"[{\"time\":7149,\"type\":0,\"target\":\"****\"},{\"time\":5718,\"type\":1,\"target\":\"****\"}]"
1. 我们希望能提取出整个字符串的所有对象,计算全部对象的time的均值和方差,但是udf可以接受多个参数,只能返回一个结果,没有办法同时返回均值和方差,所有我将计算的均值和方差,用空格分隔形成一个新的字符串,这个字符串作为新的变量
2. 不同的变量的json对象包含变量都不同,需要为每个类型的json对象新建对应的类,新建对应的计算函数。因此udf设计为可以传入两个参数,第一个参数为需要解析的json字符串,第二个参数让evalute函数决定使用哪个对象解析函数
3. 现实解析容易出现如:"[{\"time\":7149,\"type\":0,\"target\":\"****\"},{\"time\":5718,\"type\":1,\"target\":\"****\"]" 这样最后对象缺少了}的不完整的json字符串,gson解析时回返回unterminated ojbect exception, 或者"[]"这样没有任何对象的字符串,对象数目为0时无法进行统计,因此需要设置try catch 并返回读取异常时的特定结果,全都是-1.
具体的代码发布在github上,附上链接,欢迎指错,star和fork:
https://github.com/iamiamn/odps-json-extracter/tree/master/jsonProcess
第三章:
第二章完成udf编写,还需要在数加平台上使用SQL的split_part函数,把统计结果组成的字符串,提取形成一个个新变量。代码如下:
https://github.com/iamiamn/odps-json-extracter/blob/master/odps.sql
最后希望大家能取得好成绩,如果需要我分享例如正则匹配的操作流程,可以评论留言
参考资料
1.阿里云官方UDF编写指南
2.阿里云官方UDF插件开发指南
3.阿里云官方ODPS指南_MAVEN环境搭建指南