Python3 多线程下载代码
根据http://www.oschina.net/code/snippet_70229_2407修改而来的增强版。貌似原版源自Axel这个多线程下载工具。
'''
Created on 2014-10-24
@author: Maple
'''
import sys
import os
import time
import getopt
import urllib.request
import urllib.parse
from threading import Thread
#===============================================================================
# def download(url, output=os.getcwd(), blocks=6, proxies=local_proxies)
# output:输出文件路径,默认为当前路径
# blocks:线程数
# proxies:代理地址
#===============================================================================
local_proxies = {}#代理地址
class Maple(Thread):
version = "Mozilla/5.0"
def __init__(self, threadname, url, filename, ranges=0, proxies={}):
Thread.__init__(self, name=threadname)
self.name = threadname
self.url = url
self.proxies = proxies
self.filename = filename
self.ranges = ranges
self.downloaded = 0
def run(self):
try:
self.downloaded = os.path.getsize( self.filename ) #获取已下载的文件字节块块,支持断点续传
except OSError:
#print 'never downloaded'
self.downloaded = 0
opener=GetUrlOpener(self.proxies) #根据代理参数生成相应的url opener
if self.ranges: #ranges为线程需要下载的文件块的字节范围
# rebuild start poind
self.startpoint = self.ranges[0] + self.downloaded #从已下载字节块后的位置开始下载
# This part is completed
if self.startpoint >= self.ranges[1]:
self.downloaded = self.ranges[1] - self.ranges[0]
print ('Part %s has been downloaded over.' % self.filename)
return
opener.addheaders=[('Range','bytes={}-{}'.format(self.startpoint, self.ranges[1])),('User-agent','Mozilla/5.0')] #添加请求头部内容,仅下载指定范围的字节,伪装成浏览器请求
print ('task %s will download from %d to %d' % (self.name, self.startpoint+1, self.ranges[1]+1))
else: #ranges未指定(文件大小未知,无法切割),从已下载字节块后的位置开始下载剩余全部字节
self.startpoint = self.downloaded
opener.addheaders=[('Range','bytes={}-'.format(self.startpoint)),('User-agent','Mozilla/5.0')]
self.fetchsize = 16384 #每次读取的字节数
self.urlhandle = opener.open(self.url) #打开文件地址
data = self.urlhandle.read( self.fetchsize )
while data: #循环读取数据写入临时文件,并更新已下载字节数
filehandle = open( self.filename, 'ab+' )
filehandle.write( data )
filehandle.close()
self.downloaded += len( data )
data = self.urlhandle.read( self.fetchsize )
def Sec2Time(second): #将秒数转换为标准时间格式。以为有现成的函数,结果愣是没找到
day=second//(3600*24)
second-=day*3600*24
hour=second//3600
second -=hour*3600
minute=second//60
second-=minute*60
if day == 0:
if hour == 0:
if minute == 0:
return '{:0.2f}S.'.format(second)
else:
return '{:02}M:{:0.2f}S'.format(minute,second)
else:
return '{:02}H:{:02}M:{:0.2f}S'.format(hour,minute,second)
else:
return '{:03}D:{:02}H:{:02}M:{:0.2f}S'.format(day,hour,minute,second)
def GetUrlOpener(proxies={}): #分析代理参数,返回url opener。完整代理格式:user/passwd@http://127.0.0.1:8087。如格式不同,需要修改此分析函数
if proxies:
try:
ap=proxies.split('@')
if len(ap) > 1:
auth=ap[0]
addr=ap[1]
else:
addr=ap[0]
auth=''
if '://' in addr:
ptype=addr[:addr.find('://')]
phost=addr[addr.find('://')+3:]
else:
ptype='http'
phost=addr
proxy={ptype:ptype+'://'+phost}
proxy_handler = urllib.request.ProxyHandler(proxy)
except Exception as ex:
print(ex)
return urllib.request.build_opener()
try:
authlist=auth.split('/')
if len(authlist) > 1:
user=authlist[0]
passwd=authlist[1]
proxy_auth_handler = urllib.request.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm',phost,user,passwd)
opener = urllib.request.build_opener(proxy_handler,proxy_auth_handler)
else:
opener = urllib.request.build_opener(proxy_handler)
return opener
except Exception as ex:
print(ex)
return urllib.request.build_opener(proxy_handler)
else:
# urlHandler=urllib.request.urlopen(url)
return urllib.request.build_opener()
def GetUrlFileInfo(url,proxies={}): #获取要下载的文件的信息,包括文件名,文件类型和文件大小
scheme, netloc, path, query, fragment = urllib.parse.urlsplit(url) #分析url
filename=urllib.parse.unquote(path) #如果url中的文件名部分存在中文,将其正确解码出来
filename=filename.split('/')[-1]
opener=GetUrlOpener(proxies) #通过网络请求读取响应头部,根据头部获取文件信息。文件名以服务器返回的文件名信息为准
urlHandler=opener.open(url)
headers=urlHandler.info()
if 'Content-Disposition' in headers: #Content-Disposition字段有可能获取到文件名,不过可能是乱码,没找到解决办法
disposition=headers.get('Content-Disposition')
if 'filename=' in disposition:
filename = disposition.split('filename=')[1]
if filename[0] == '"' or filename[0] == "'":
filename = filename[1:-1]
filename=urllib.parse.unquote(filename)
if filename:
(name,ext)=os.path.splitext(filename)
else:
(name,ext)=('Unknown','')
if 'Content-Length' in headers: #获取文件长度,如果获取失败,则只能使用单线程下载
length=int(headers.get('Content-Length'))
else:
length=-1
(type, kind)=headers.get('Content-Type').split('/') #获取文件类型,备用
infos=[(name,ext),(type,kind),length]
return infos
def SpliteBlocks(totalsize, blocknumber): #根据指定的线程数参数和获取到的文件长度划分各线程的下载范围
blocksize = totalsize//blocknumber
ranges = []
for i in range(0, blocknumber-1):
ranges.append((i*blocksize, i*blocksize +blocksize - 1))
ranges.append(( blocksize*(blocknumber-1), totalsize -1 ))
return ranges
def islive(tasks): #检查各线程是否全部下载完成
for task in tasks:
if task.isAlive():
return True
return False
def download(url, target=os.getcwd(), blocks=6, proxies=local_proxies):
flag=True
print('Retrieving resource information...')
url=urllib.parse.quote(url,safe='/%&@=+?$;,:') #将提供的url编码,非英文字符将被编码为标准格式
try:
infos=GetUrlFileInfo(url,proxies) #获取文件信息
except Exception as ex:
print(ex)
flag=False
if flag:
if not os.path.exists(target):
os.makedirs(target)
size=infos[2] #获取到的文件大小
output=os.path.join(target,''.join(infos[0])) #根据获取到的文件名和指定的保存目录生成完整路径
type=infos[1][0]
starttime=time.time() #开始计时
print('Infomation:')
print('FileName:{0} FileType:{1} FileLength:{2}'.format(''.join(infos[0]),'/'.join(infos[1]),infos[2] if int(infos[2]) > 0 else 'Unknown')) #打印获取到的文件信息
if size > 0: #size大于0表示成功获取文件长度,可以进行多线程下载
print('Starting multithread download...')
ranges = SpliteBlocks( size, blocks )
else: #只能单线程下载,线程数置1,ranges置空,
print('Starting single thread download...')
ranges=()
blocks=1
threadname = [ infos[0][0]+"_thread_%d" % i for i in range(0, blocks) ] #生成线程名
filename = [ infos[0][0]+ "_tmpfile_%d" % i for i in range(0, blocks) ] #生成各线程的临时文件名
tasks = []
for i in range(0,blocks): #生成下载线程,设置为后台线程后启动,将线程加入到线程列表中
task = Maple( threadname[i], url, filename[i], ranges[i] if ranges else ranges,proxies)
task.setDaemon( True )
task.start()
tasks.append( task )
time.sleep( 1 )
downloaded = 0
while islive(tasks): #统计线程列表中各线程的状态,输出下载进度
downloaded = sum( [task.downloaded for task in tasks] )
if size > 0:
process = downloaded/float(size)*100
show = '\rFilesize:%d Downloaded:%d Completed:%.2f%%' % (size, downloaded, process)
else:
show = '\rDownloaded:%d ' % downloaded
sys.stdout.write(show)
sys.stdout.flush()
time.sleep( 0.2 )
endtime=time.time() #下载完成后停止计时
consuming=Sec2Time(endtime-starttime)
if size > 0: #多线程下载的后续处理
downloadsize = 0
for i in filename:
downloadsize += os.path.getsize(i)
if downloadsize == size:
show = '\rFilesize:%d Downloaded:%d Completed:%.2f%%\n' % (size, downloadsize,100)
else:
show = '\nSize is not mathed!\n'
flag=False
else: #单线程下载的后续处理
show = '\nTotal Size: %d\n'% downloaded
sys.stdout.write(show)
sys.stdout.flush()
if flag: #确认下载的临时文件没问题后将各文件整合为最终的目标文件
print('Integrating files...')
num=1
while os.path.exists(output): #防止与本地已存在文件重名
fname,fext=os.path.splitext(output)
if '('+str(num-1)+')'+fext in output:
output = output.replace('('+str(num-1)+')'+fext,'('+str(num)+')'+fext)
else:
fname += '('+str(num)+')'
output = fname+fext
num +=1
if len(filename) ==1 : #单线程下载的话,直接将下载的文件重命名为目标文件即可
os.rename(filename[0], output)
else: #多线程临时文件整合
filehandle = open( output, 'wb+' )
for i in filename:
try:
f = open( i, 'rb' )
filehandle.write( f.read() )
f.close()
os.remove(i)
except Exception as ex:
print(ex)
filehandle.close()
if os.path.exists(output):
print('Download Complete!')
else:
print('Failed to generate target file!')
try:
#os.remove(output)
pass
except:
pass
else:
for i in filename:
try:
os.remove(i)
pass
except:
pass
print('Download Failed!')
pass
print('Consuming: {}\n'.format(consuming)) #输出耗时
else:
print('Failed to retrieve resource information!')
sys.exit()
def main(argv): #处理传入参数,使用了getopt模块,另外有一个更强大的处理传入参数的模块optparse
try:
options,args=getopt.getopt(argv,'hu:f:n:p:',['help','url=','target=','num=','proxy='])
except Exception as ex:
print(ex)
sys.exit()
num = 2
url,target,proxies= '','',''
url = 'http://www.pygtk.org/dist/pygtk2-tut.pdf'
target = '/home/maple/Desktop'
#proxies = 'http://127.0.0.1:8087'
#proxies={}
for name, value in options:
if name in ('-h','--help'):
print('No Help ^^')
sys.exit()
if name in ('-u','--url'):
url = value
if name in ('-t','--target'):
target = value
if name in ('-n','--num'):
num = int(value)
if name in ('-p','--proxy'):
proxies=value
#check args
download(url,target,num,proxies)
if __name__ == '__main__':
main(sys.argv[1:])
这段代码在异常处理方面写得有些乱,没怎么关心异常处理,需要时再改吧
另外多线程下载时,如果使用了代理,会导致下载到的文件与服务器提供的文件大小不符。从而下载失败。我使用的是GoAgent,代理服务器会自动对目标文件进行多线程下载,无视程序指定的下载字节范围。第一个线程就会下载到完整的文件,其他线程会下载冗余内容。没有找到规范的处理办法。变通的处理办法有2种:
1、将使用了代理的多线程下载强制指定为单线程下载
2、不进行文件大小的校验,将多线程下载的0号临时文件重命名为目标文件,其他临时文件删除。
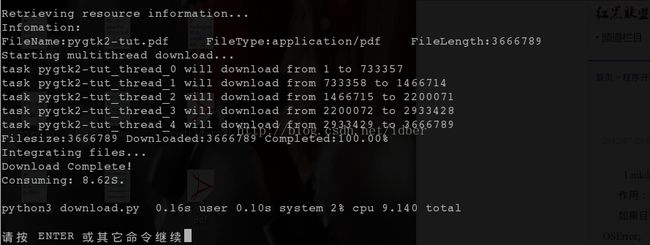
两种方法实现都很简单,但是破坏代码的整体逻辑。没有加入代码中。运行截图: