Kettle初识
目录
- Kettle初识
- 起源
- 关于Hitachi Vantara 公司
- Kettle初识
- 基本概念
- 体系结构
- 下载获取kettle
- 名词解释
- Kettle的组件
- 转换与作业的执行方式
- kettle转换之多线程以及job并行问题
- 解决kettle调度效率低,不可高并发调度方法
- Kettle之Carte最佳实践
- kettle日志
- kitchen命令行执行job
- Kettle集成
- kettle编译安装
- IDEA启动
- 常用集成解决方案
- kettle文件同步相关
- FTP文件同步
- 业务场景
- 使用Kettle从FTP拉取文件
- Kettle 日志的保存
- kettle工具二次开发
- Etl工具之Kettle与java集成
- java调用kettle jar包生成kjb文件
- kettle工具二次开发-代码启动JOB
- Kettle — 自定义插件
- 源码基本认识
- KettleEnvironment.init()详解
- 加载插件流程/架构
- Kettle — 转换机制
- 其他参考
- 其他概念基础
- ETL\数据仓库\大数据相关概念
- HIVE和HBASE区别
- 数据仓库和大数据
Kettle初识
官方社区https://community.hitachivantara.com/community/products-and-solutions/pentaho
起源
Kettle是一个Java编写的ETL工具,主作者是Matt Casters,2003年就开始了这个项目。
2005年12月,Kettle从2.1版本开始进入了开源领域,一直到4.1版本遵守LGPL协议,从4.2版本开始遵守Apache Licence 2.0协议。
Kettle在2006年初加入了开源的BI公司Pentaho, 正式命名为:Pentaho Data Integeration,简称“PDI”。
自2017年9月20日起,Pentaho已经被合并于日立集团下的新公司: Hitachi Vantara。
总之,Kettle可以简化数据仓库的创建,更新和维护,使用Kettle可以构建一套开源的ETL解决方案。
关于Hitachi Vantara 公司
转型密码@Hitachi Vantara到底是怎样一家公司?
参考URL: https://blog.csdn.net/Bmo40mqfG249H/article/details/78775259
日立成立Hitachi Vantara:致力于解决世界最棘手商业和社会挑战的新数字公司
参考URL: https://www.sohu.com/a/193226023_115007
Hitachi Vantara,一家“三合一”的新公司,2017年9月才刚刚成立,它很可能成为未来物联网市场上的一个“狠角色”。不过,熟悉HDS的人对于由HDS和Hitachi Insight Group、Pentaho整合在一起的Hitachi Vantara很可能会有一种老友重逢的感觉,才几个月不见就像重新焕发了青春。Hitachi Insight Group、Pentaho的专长是当前炙手可热的人工智能、大数据、物联网,它们与提供基础架构和云平台的HDS整合在一起。
Hitachi Vantara是日立有限公司全资子公司,帮助以数据为本的市场领军者发现并利用其数据中的价值进行智能创新,以取得对企业和社会举足轻重的成果。 我们将技术、知识产权和行业知识相结合,提供数据管理解决方案,帮助企业改善客户体验,开发新的收入来源和降低业务成本。 只有Hitachi Vantara能够通过结合深层信息技术(IT)、运营技术(OT)和领域专长来提升您的创新优势。 我们与各地的机构合作,充分发掘数据的价值。
Kettle初识
[推荐]参考URL: https://www.jianshu.com/p/2a7ace927825
[推荐]参考URL: https://wenku.baidu.com/view/826e280f366baf1ffc4ffe4733687e21af45ff8b.html
Kettle是一款采用纯JAVA实现的开源ETL工具,属于开源商务智能软件Pentaho的一个重要组成部分。Kettle提供一系列的组件用于完成各种上面所说的抽取、转换、加载的工作。正如Kettle一词的中文意思水壶一样,Kettle的开发人员希望使用kettle处理数据就像从水壶中倒水出来一样–把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle中两个核心是转换(transformation)与作业(job):
转换(transformation):完成数据ETL工作;

作业(job): 定义一个完成整个工作流的控制;
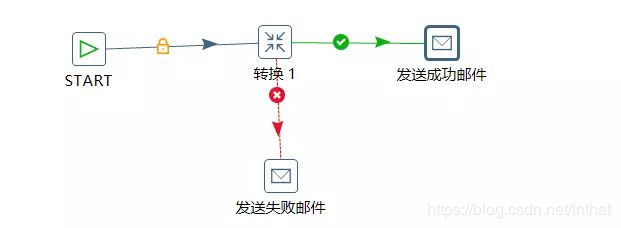
基本概念
-
Transformation: 完成针对数据的基础转换,即一个数据转换的过程。
定义对数据操作的容器,数据操作就是数据从输入到输出的一个过程,可以理解为比Job粒度更小一级的容器,我们将任务分解成Job,然后需要将Job分解成一个或多个Transformation,每个Transformation只完成一部分工作。
-
Step:步骤,是Transformation 的功能单元,用来完成整个转换过程的一个特定步骤。
是Transformation内部的最小单元,每一个Step完成一个特定的功能。
-
Job: 一个作业,由不同的逻辑功能的entry组成,数据从一个entry组件传递到另一个entry组件,并在entry组件中进行的处理。
负责将Transformation组织在一起进而完成某一工作,通常我们需要把一个大的任务分解成几个逻辑上隔离的Job,当这几个Job都完成了,也就说明这项任务完成了。
-
Job Entry:即job型组件。用来完成特定功能应用,是job的组成单元、执行单元。
Job Entry是Job内部的执行单元,每一个Job Entry用于实现特定的功能,如:验证表是否存在,发送邮件等。可以通过Job来执行另一个Job或者Transformation,也就是说Transformation和Job都可以作为Job Entry。
-
Hop:工作流或转换过程的流向指示,从一个组件指向另一个组件,在kettle工程中有三种hop,无条件流向、判断为真时流向、判断为假时流向。
用于在Transformation中连接Step,或者在Job中连接Job Entry,是一个数据流的图形化表示。
 在Kettle中Job中的JobEntry是串行执行的,故Job中必须有一个Start的JobEntry;Transformation中的Step是并行执行的。
在Kettle中Job中的JobEntry是串行执行的,故Job中必须有一个Start的JobEntry;Transformation中的Step是并行执行的。
体系结构
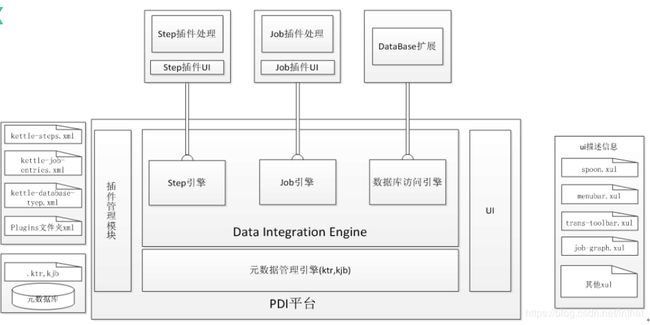 Kettle平台是整个系统的基础,包括元数据管理引擎,数据集成引擎,UI和插件管理模块。
Kettle平台是整个系统的基础,包括元数据管理引擎,数据集成引擎,UI和插件管理模块。
- 元数据管理引擎
管理ktr、kjb或者元数据库,插件通过该引擎获取基本信息,主要包括TransMeta、JobMeta和StepMeta三个类。
TransMeta类,定义了一个转换(对应一个.ktr文件),提供了保存和加载该文件的方法。
JobMeta类,同样对应于一个工作(对应一个.kjb文件),提供保存和加载方法。
StepMeta类,保存的是Step的一些公共信息的类,每个类的具体的元数据将保存在实现了StepMetaInterface的类里面。 - 数据集成引擎
数据集成引擎包括Step引擎、Job引擎和数据库访问引擎三大部分,主要负责调用插件,并返回相应信息。 - UI
通过xul实现菜单栏、工具栏,其中TransGraph类和JobGraph类用于显示转换和job的类。 - 插件管理模块
插件管理引擎主要负责插件的注册
Spoon在启动的时候会对所有插件进行注册,并保存在PluginRegistry类里面。平台通过查找PluginRegistry注册表获取插件信息。Kettle安装插件需要进行重启,卸载插件也只需简单的删除plugins目录结构下的对应的文件即可。
下载获取kettle
kettle之旅–下载获取kettle/pdi
参考URL: https://ask.hellobi.com/blog/cimen/14363
国内镜像下载:http://mirror.bit.edu.cn/pentaho/Data Integration/(北京理工大学开源软件镜像服务)
说明:国内大学提供镜像服务,下载速度可以,缺点,版本更新不会很及时,基本都是目前主流版本。
建议访问github源码,编译使用。
名词解释
-
KETTLE_HOME:
KETTLE_HOME是指kettle的home目录,默认位置为(以windows为例):C:\Users\Administrator.kettle;我们可以通过设置系统环境变量KETTLE_HOME来自定义该目录位置。在KETTLE_HOME目录下会存在如下配置文件:kettle.properties:全局环境参数配置文件;
repositories.xml:资源库描述文件;
share.xml:共享对象描述文件; -
资源库(repository):
资源库相当于一个Kettle工程目录。这个工程所有的作业与转换,数据库连接信息,参数变量都将保存在这个资源库。启动一个作业与转换的前提条件也是先连接上所在的资源库。kettle中资源库分为文件资源库与数据库资源库。
**文件资源库 **需要指定一个文件系统的目录作为资源库根目录。使用文件资源库所有作业与转换会以文件的形式保存在该资源库根目录下。作业文件扩展名为.kjb,转换的件扩展名则为.ktr。文件资源库的好处是便于迁移,只要将.kjb或.ktr拷贝到其他资源目录下就可以完成迁移。
数据库资源库 需要指定一个数据库连接,这个连接可以是JDBC形式也可以是JNDI或ODBC。Kettel会生成一个数据库脚本,在指定数据库中生成一系列相关的表用于存储作业与转换以及相关的数据库连接信息和参数变量配置。数据库资源库的好处是安全,连接一个数据库资源库是需要进行用户认证的。
-
数据库连接:
创建资源库连接作为数据源或资源库。kettle支持绝大多数数据库系统。 -
元数据(meta):
是指用于描述作业与转换属性的数据。上面说到的.kjb和.ktr文件实际存储的就是元数据的描述信息,同样的数据库资源库中保存的也是元数据信息。执行转换和作业时,kettel首先加载的是各自的元数据,然后生成作业或转换实例,再执行。元数据好比是Class,而实例则是Object。 -
变量与参数:
变量(variable): 变量可以是定义在kettle.properties中的全局变量,也可以是通过设置变量步骤和获取变量步骤在作业运行中动态设置与使用;变量使用时的格式为${变量名};需要注意的是设置变量所设置的变量在同一个转换里是不能被获取变量获取的,必须在一个作业中的下一个转换中使用,这是因为转换的步骤是并行运行的。
参数(parameter): 参数分为命名参数与位置参数,他们区别是是否存在参数名称。显然命名参数的名称,而且它还有默认值。我们可以在作业与转换的元数据中设置好命名参数以及它的默认值,在运行时传入指定值或者不传值使用默认值;
而位置参数则是通过’?'作为站位符,运行时按传入顺序一个个替换为传入的值。
Kettle的组件
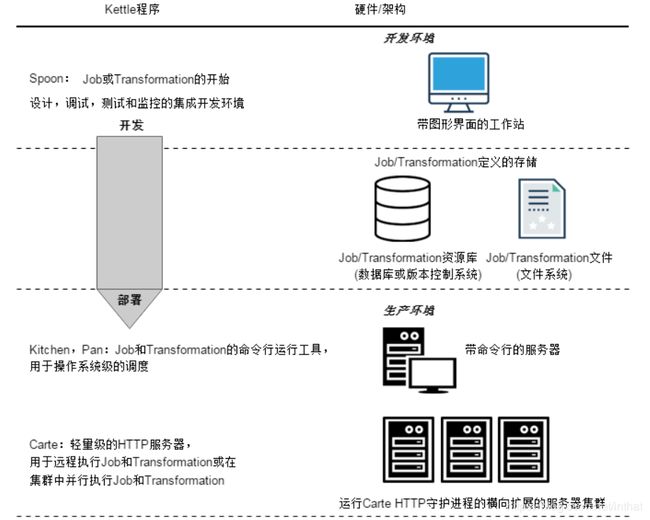
Kettle提供了如下组件:
- spoon(汤勺):一个基于SWT的IDE工具。常用完成转换(transformation)与作业(job)脚本的设计;
- kitchen(厨师):命令行工具,用于执行作业(job);
- pan(煎锅): 命令行工具,用于执行转换(transformation);
- carte(菜单): http服务器,用于监听HTTP请求,完成远程执行转换(transformation)与作业(job)。另外也可以用于实现集群。
从图中可知,实际使用Kettle时,利用Spoon做为开发工具,设计好作业与转换,以及相关参数与变量并保存在资源库中。生成环境中,使用kitchen或pan启动作业或转换。同时,根据实际需求与数据量,决定是否使用carte进行远程调用或者集群部署。
转换与作业的执行方式
Kettle中使用转换(transformation)完成数据ETL全部工作。转换由多个步骤(step)组成,如文本文件输入,过滤输出行,执行SQL脚本等。各个步骤使用跳(hop)来链接。 跳定义了一个数据流通道(也就是上图看到的带箭头的连线),即数据由一个步骤流(跳)向下一个步骤。在Kettle中数据的最小单位是行(row),数据流中流动其实是缓存的行集(RowSet)。
因为转换(transformation)以并行方式执行,所以必须存在一个串行的调度工具来执行转换,这就是kettle中的作业(job)。
kettle步骤通信
kettle调优中有个重要的参数:记录集合里面的记录数。
该数量是指组件与组件之间通信的【缓存队列】的size大小,Kettle内部用List实现该缓存队列,每一条语句都会被封装成一个 RowSet对象,如下图所示,每个组件之间都会有个List队列,源step每次会往该队列写一条数据,目标step每次会从队列读取一条数据。
影响
kettle里面转换是并行的,数据是一条一条流经每个组件,队列大小采用默认的10000条即可。
kettle转换之多线程以及job并行问题
Pentaho Kettle 简单并行处理
参考URL: https://blog.csdn.net/rav009/article/details/79034001
[推荐]kettle转换之多线程
参考URL: https://blog.csdn.net/neweastsun/article/details/39857733
Kettle7 ( Pentaho Data Integration )源码分析 每个step都有一个线程负责运行
参考URL: https://blog.csdn.net/weidenglu11/article/details/62424207
KETTLE一行一行执行方法
参考URL: https://blog.csdn.net/why_00/article/details/46349313
[推荐]Kettle记录集合RowSet数量
参考URL: https://blog.csdn.net/u014307117/article/details/80600257
-
step并行:
-
job并行:
根据Kettle的设计所有的step在transformation里是并行运行的, 所以在transformation里无法做到针对某一个step记日志, 因为记日志那步会在transformation一开始就执行 而不会等待你要关注的那个step完成才开始.
可以把记日志的功能放到job里去。
对于job, job不是并行的, 而是根据箭头有先后执行顺序的.
1) 在一个job里, 有若干步是并行的, 等待这些并行的全部处理完成后再执行下一步, 怎么做到?
答: 把并行的部分封装在一个子job里
2)在job里怎么做到并行:
并行前的一步右键点击: “Run Next Entries in Parallel”
解决kettle调度效率低,不可高并发调度方法
解决kettle调度效率低,不可高并发调度方法
参考URL: https://blog.csdn.net/u010192222/article/details/78401674
kettle调度监控最佳实践
参考URL: https://my.oschina.net/u/944575/blog/1557410
[推荐]http://www.taskctl.com/forum/detail_124.html
由于是采用系统外部命令来调用kettle作业,所以每次调起一个转换或作业的时候,就会消耗大量的时间(>10秒)来初始化一个新的kettle运行环境。在并行调用多个kettle作业的时候,特别是调用数据资源库里的作业,容易引起系统级别的错误,带来不稳定性。
Kettle作为用户规模最多的开源ETL工具,强大简洁的功能深受广大ETL从业者的欢迎。但kettle本身的调度监控功能却非常弱。连Pentaho官方都建议采用crontab(Unix平台)和计划任务(Windows平台)来完成调度功能。调用kettle作业,实际上是通过pan和kitchen命令去调用。每一次调用都会重新初始化kettle运行环境,这个过程占用大量的时间。并且每启动一个kettle运行环境都相当于启动一个JVM进程。每个JVM则会占用几百兆(默认设置)的内存。所以同时运行几个作业,也会消耗大量内存资源。极端情况则可能会导致kettle内存溢出,产生致命错误。
https://my.oschina.net/u/944575/blog/1557410
http://www.taskctl.com/forum/detail_124.html
上述是Taskctl出的解决方案,但是如果我本身不愿意在多学习一个调度工具,其实也是可以用这个的。安装这个服务后,默认会生成两个调度插件,分别对应trans和job两种类型的。我们现在需要做的就是用crontab调用调度插件,配合着正确的参数值,就可以正常调度了,非常简单,而且效率也很高。
下面是我调度Linux下kettle配置的一个crontab范例,仅供大家参考
0 0 * * * /home/kettle/shell/cprunsoapktr.sh “/home/kettle/mykettle/my.ktr” “” “”
这个是我们trans作业。是直接调用文件,而且也没有参数,如果有差异,在安装服务是按需选择,调用的时候有细微的差异。执行效率比原来有大幅的提升,而且也不在开辟多个JVM环境,造成服务器资源的问题
Kettle之Carte最佳实践
Kettle之Carte最佳实践
参考URL: https://baijiahao.baidu.com/s?id=1594430341632871491&wfr=spider&for=pc
Kettle有多种运行模式,最简单易用的是直接运行Kitchen/Pan应用程序来执行job/transformations,但每次运行任务时,kitchen/pan都要启动一次。而应用的启动是有代价的,并且如果服务器上同时跑了很多Kitchen/Pan程序,也不利于资源分配和监控。
Carte是一个轻量级的web服务,允许远程请求HTTP进行监控、启动、停止在Carte服务上运行的job和trans。运行Carte的服务器在kettle术语里称为slave server。
Carte可以利用起来做分布式、集群相关部署。
kettle日志
【Kettle从零开始】第十弹之Kettle运行日志介绍
参考URL: https://blog.csdn.net/rotkang/article/details/21028157
kettle案例九-----linux使用kettle
参考URL: https://blog.csdn.net/zzq900503/article/details/79110810
日志存储有两种方式:一种是文本文件存储日志,另一种是资源库存储日志(注:Kettle资源库日志分两类,一类是Job日志,一类是Trans日志)。
kitchen命令行执行job
参考URL: https://www.cnblogs.com/tangbinghaochi/p/7680224.html
- Kitchen——作业执行器
是一个作业执行引擎,用来执行作业。这是一个命令行执行工具, 参数说明如下- -rep:Repositoryname 任务包所在存储名
- -user:Repositoryusername 执行人
- -pass:Repositorypassword 执行人密码
- -job:Thenameofthejobtolaunch 任务包名称
- -dir:Thedirectory(don’tforgettheleading/or)
- -file:Thefilename(JobXML)tolaunch
- -level:Thelogginglevel(Basic,Detailed,Debug,Rowlevel,Error,Nothing)指定日志级别
- -log:Theloggingfiletowriteto 指定日志文件
- -listdir:Listthedirectoriesintherepository 列出指定存储中的目录结构。
- -listjobs:Listthejobsinthespecifieddirectory 列出指定目录下的所有任务
- -listrep:Listthedefinedrepositories 列出所有的存储
- -norep:Don’tlogintotherepository 不写日志
示例: 1. Windows 中多个参数以 / 分隔,key 和 value 之间以:分隔
作业存储在文件
Kitchen /level:Basic>D:\etl.log /file:F:\Kettledemo\email.kjb
作业存储在数据库
Kitchen /rep kettle /user admin /pass admin /job F_DEP_COMP
( Rep 的值为数据库资源库 ID)
- Linux 中参数以 –分隔
作业存储在文件
kitchen.sh-file=/home/job/huimin.kjb >> /home/ log/kettle.log
作业存储在数据库
./kitchen.sh -rep=kettle1 -user=admin -pass=admin -level=Basic -job=job
问题整理:
- 卡在creating configuration from pentaho.big.data.impl.cluster.cfg
Kettle集成
[推荐]官方参考URL: https://wiki.pentaho.com/display/EAI/The+PDI+SDK
kettle通常作为工具使用,但是你也可以把kettle当作开发库来使用,让它为你的软件和解决方案服务。
kettle编译安装
petaho kettle 8.0源码编译
参考URL: https://blog.csdn.net/llovedan/article/details/79099561
pentaho专题系列之kettle篇–kettle源码编译
参考URL: https://www.cnblogs.com/shenlanzhizun/p/7364961.html
[推荐]petaho kettle 8.1.0.0源码编译过程
参考URL: https://blog.csdn.net/li575563191/article/details/82725166
01、petaho kettle 8.0源码编译
参考URL: https://blog.csdn.net/llovedan/article/details/79099561
利用IDEA的 maven install成功。\assemblies\pdi-ce\target目录会多一个pdi-ce-8.3.0.0-SNAPSHOT.zip的压缩包
最终打包zip是在,assemblies\core\client\src\assembly\assembly.xml中打包出来的。
库和类路径
kettle可以作为Java API来使用,API由以下四个部分构成。
- Core: 包括Kettle的核心类,保存在kettle-core.jar文件中。
- Database:包括Kettle数据库相关的类,保存在kettle-db.jar文件中。
- Engine: Kettle运行时类,保存在kettle-engin.jar类中。
- GUI: 基于Eclipse SWT的图形界面相关的类,如Spoon保存在kettle-ui-swt.jar文件。
遇到问题:
- 在编译到PDI Client Plugins时,出现报错
[WARNING] The POM for org.pentaho.di.plugins:google-bigquery-plugin:zip:8.3.0.0-SNAPSHOT is missing, no dependency information available
[ERROR] Failed to execute goal on project pdi-plugins: Could not resolve dependencies for project org.pentaho.di:pdi-plugins:pom:8.3.0.0-SNAPSHOT: Failure to find org.pentaho.di.plugins:google-bigquery-plugin:zip:8.3.0.0-SNAPSHOT in http://nexus.pentaho.org/content/groups/omni/ was cached in the local repository, resolution will not be reattempted until the update interval of pentaho-public has elapsed or updates are forced -> [Help 1]
使用readme中官方描述的setting还是报错。
was cached in the local repository, resolution will not be reattempted until
参考URL: https://blog.csdn.net/zyf_balance/article/details/47171723
还是解决不了,最后 pom中删掉 google-bigquery-plugin的依赖。
- 卡在[INFO] Building PDI Client Community Edition 8.3.0.0-SNAPSHOT
[INFO] ------------------------------------------------------------------------
Downloading: http://nexus.pentaho.org/content/groups/omni/org/pentaho/di/pdi-plugins/8.3.0.0-SNAPSHOT/pdi-plugins-8.3.0.0-20181210.110458-4.zip
发现这个zip文件很大856MB所以,下载慢。
你可以单独浏览器下载,直接替换到相应的目录。
大数据相关插件zip包也很大,下载,不下,请手动下载替换到相应目录。
https://nexus.pentaho.org/content/groups/omni/pentaho/pentaho-big-data-plugin/8.3.0.0-SNAPSHOT/pentaho-big-data-plugin-8.3.0.0-20190107.151805-32.zip
IDEA启动
kettle8.0源码编译
参考URL: https://blog.csdn.net/ajiu_9999/article/details/83306305
- 修改一下UI 子模块的中的pom.xml文件改成Windows的swt包
org.eclipse.swt
org.eclipse.swt.win32.win32.x86_64
然后修改 file ->Project Structure -> Modules -> kettle-ui-swt -> Dependencies 中将如下图中所示:将windows的swt放在前面,先加载,后面的linux的swt的jar包就不会再加载(这个如果你是在linux系统下的话,就不用修改这些)然后修改 file ->Project Structure -> Modules -> kettle-ui-swt -> Dependencies 中将如下图中所示:将windows的swt放在前面,先加载,后面的linux的swt的jar包就不会再加载(这个如果你是在linux系统下的话,就不用修改这些)
3.
然后将先前maven 编译打包后的这里的所有文件拷贝到代码的ui目录下
遇到问题:
1.kettle 8 源码启动,报错:
java.lang.UnsatisfiedLinkError: Could not load SWT library. Reasons:
no swt-gtk-4623 in java.library.path
no swt-gtk in java.library.path
Can’t load library: C:\Users\Administrator.swt\lib\win32\x86_64\swt-gtk-4623.dll
Can’t load library: C:\Users\Administrator.swt\lib\win32\x86_64\swt-gtk.dll
at org.eclipse.swt.internal.Library.loadLibrary(Unknown Source)
at org.eclipse.swt.internal.Library.loadLibrary(Unknown Source)
at org.eclipse.swt.internal.C.(Unknown Source)
at org.eclipse.swt.internal.Converter.wcsToMbcs(Unknown Source)
at org.eclipse.swt.internal.Converter.wcsToMbcs(Unknown Source)
at org.eclipse.swt.widgets.Display.(Unknown Source)
at org.pentaho.di.ui.spoon.Spoon.main(Spoon.java:658)
解决方法:
修改 file ->Project Structure -> Modules -> kettle-ui-swt -> Dependencies 中将如下图中所示:将windows的swt放在前面,先加载,后面的linux的swt的jar包就不会再加载(这个如果你是在linux系统下的话,就不用修改这些)然后修改 file ->Project Structure -> Modules -> kettle-ui-swt -> Dependencies 中将如下图中所示:将windows的swt放在前面,先加载,后面的linux的swt的jar包就不会再加载
- log4j:ERROR Could not parse file [plugins\kettle5-log4j-plugin\log4j.xml].
Kettle5 log4j插件使用
参考URL: https://blog.csdn.net/d6619309/article/details/52694037
有时候根据我们实际的需求,需要将日志保存起来,便于日后分析错误、排除故障。所幸在kettle5中有一个内置插件,叫做kettle5-log4j-plugin。本来以为只要将log4j.xml放在kettle安装目录,并在plugins目录下集成这个插件后就可以将kettle中执行的日志统统追加到log4j配置的日志输出位置。但是事实上,kettle官方源码里面并没有在KettleEnvironment中初始化注册logging plugin。所以我们需要做的是,在Kettle环境初始化过程中初始化注册logging plugin。
解决方案:
将assemblies\plugins\target 下的打包zip插件中的kettle5-log4j-plugin拷贝到 源码的plugins目录下
- org.pentaho.di.core.exception.KettleException:
java.lang.NoClassDefFoundError: com/google/api/client/json/JsonFactory
com/google/api/client/json/JsonFactory
常用集成解决方案
实际生产当中我们不太可能打开spoon,以人工形式来执行作业或转换,这就需要一种集成方案,来通过我们的应用程序自动的执行作业或转换。
这里有两套执行方案:
一是比编写好kitchen或者pan脚本,通过应用程序调用这些脚本。或者将脚本放入系统定时任务中,以周期形式来调用;
二是利用carte搭建服务器,应用程序远程调用服务启动作业或转换;
三是可以完全将kettle的API集成到应用程序,以代码的形式,通过API来调用,甚至代替spoon来进行维护。
以上三种方案都是可以实现的,采用哪套,完全取决于实际项目需求。
kettle文件同步相关
FTP文件同步
[推荐]官方https://wiki.pentaho.com/display/EAI/Get+a+file+with+FTP
业务场景
使用Kettle从FTP拉取文件
Kettle 日志的保存
Kettle api 二次开发之 日志的保存
参考URL: https://www.cnblogs.com/Leechg/p/7195859.html
使用kettle做数据抽取的时候可以使用图形化的工具配置日志保存参数,选择数据库连接,输入日志表名称,
点击sql 执行对应的sql创建日志表即可。
点击保存之后,日志配置会保存在trans或者job的配置文件中。这样当使用api调取trans或者job配置文件进行数据抽取的时候就会自动把转换日志存储到配置的数据表中。
kettle工具二次开发
Etl工具之Kettle与java集成
[推荐]官方参考URL: https://wiki.pentaho.com/display/EAI/The+PDI+SDK
官方SDK: https://github.com/pentaho/pdi-sdk-plugins
java api调用Kettle作业需要引用jar包最小集
参考URL: https://blog.csdn.net/cakecc2008/article/details/79291620
Etl工具之Kettle与java集成二
参考URL: https://blog.csdn.net/xiaosemei/article/details/77868737
java调用kettle jar包生成kjb文件
官方参考: https://github.com/pentaho/pdi-sdk-plugins
kettle工具二次开发-代码启动JOB
官方参考: https://github.com/pentaho/pdi-sdk-plugins
kettle工具二次开发-代码启动JOB
参考URL: http://www.cnblogs.com/pangblog/p/3268626.html
java调用kettle API执行ktr或者kjb文件。
Kettle — 自定义插件
Kettle — 自定义插件
参考URL: https://blog.csdn.net/u013468915/article/details/82629810
源码基本认识
Kettle — 源码启动和代码结构分析
参考URL: https://blog.csdn.net/u013468915/article/details/82630045
官方Developer Center
参考URL:https://help.pentaho.com/Documentation/8.2/Developer_Center
kettle的源码结构
kettle-core:kettle的核心模块,包括一些数据处理等。
kettle-dbdialog:kettle数据库连接界面逻辑。
kettle-engine:kettle的引擎,负责执行kettle的具体作业和转换的逻辑,并会调用core模块。
kettle-ui-swt:用户界面模块,包括用户界面显示的xul文件,通过后端代码编写的Dialog以及国际化等。
pdi-assemblies:该模块用于项目的生成,里面主要包括各个工具启动的脚本、静态资源、帮助文档、组件简单的事例(ktr/kjb)、第三方包引用等。
pdi-engine-ext:kettle引擎扩展模块。
pdi-plugins:kettle的核心插件模块,如果我们要自定义组件,可以参考该模块的组件。
integrantion:集成测试模块。
Kettle中的Transformation中包含多个step组件, 当运行transformation时, 这些组件并不是串行初始化的.
每个作业控件都能在engine项目的org.pentaho.di.job.entries包下面找到相应实现,类似的转换控件能在engine项目的org.pentaho.di.trans.steps包下面找到相应实现。
在界面配置有问题在ui项目看实现,运行中出错,找问题在engine项目中找。作业控件一般属性和业务逻辑都在一个类中,转换控件一般会分为*Data、*Meta和一个业务实现类、若干相关工具类。Data用于保存运行数据,Meta用于保存配置元数据,有与资源库交互的实现。
KettleEnvironment.init()详解
[推荐]关于kettle初始化的那点事
参考URL: https://blog.csdn.net/luthreestone/article/details/75299157
-
KettleEnvironment.init()
(1) 首先判断KettleClientEnvironment是否初始化,没初始化的话就调用
进行初始化。该方法完成的动作主要是:创建.kettle文件夹及kettle.properties(不存在的话)
读取kettle.properties的配置
初始化KettleLogStore
加载部分plugin,并在PluginRegistry中注册这些plugin
其中加载plugin的代码如下所示:
这几个插件都是代码core目录里面定义的,这个几个类都是单例实现。
调KettleClientEnvironment.init(); 加载如下插件
public static synchronized void init() throws KettleException {
init( Arrays.asList( LoggingPluginType.getInstance(),
ValueMetaPluginType.getInstance(),
DatabasePluginType.getInstance(),
ExtensionPointPluginType.getInstance(),
TwoWayPasswordEncoderPluginType.getInstance() ) );
}
(2) 判断是否需要初始化JDNI,如果需要就调用
JndiUtil.initJNDI();
(3) 加载的plugin,并在PluginRegistry中注册这些plugin,加载的plugin如下所示:
init( Arrays.asList(
RowDistributionPluginType.getInstance(),
StepPluginType.getInstance(),
StepDialogFragmentType.getInstance(),
PartitionerPluginType.getInstance(),
JobEntryPluginType.getInstance(),
JobEntryDialogFragmentType.getInstance(),
LogTablePluginType.getInstance(),
RepositoryPluginType.getInstance(),
LifecyclePluginType.getInstance(),
KettleLifecyclePluginType.getInstance(),
ImportRulePluginType.getInstance(),
CartePluginType.getInstance(),
CompressionPluginType.getInstance(),
AuthenticationProviderPluginType.getInstance(),
AuthenticationConsumerPluginType.getInstance(),
EnginePluginType.getInstance()
), simpleJndi );
(4) 初始化kettle变量,通过调用
KettleVariablesList.init();
来初始化kettle-variables.xml里面的kettle变量。
(5) 初始化调用注册的KettleLifecyclePluginType插件类型的监听器,并将这些监听器注册到JVM关闭钩子上,这体现在方法initLifecycleListeners()里。
(6) 完成流程(1)至(5) 之后 KettleEnvironment就算初始化成功了。
- PluginRegistry.init()流程分析
这个方法会间接调用该类的init( boolean keepCache )方法。主要作用是为了完成所有插件类的动态加载(加载到classpath)。
for ( final PluginTypeInterface pluginType : pluginTypes ) {
log.snap( Metrics.METRIC_PLUGIN_REGISTRY_PLUGIN_TYPE_REGISTRATION_START, pluginType.getName() );
registry.registerType( pluginType );
log.snap( Metrics.METRIC_PLUGIN_REGISTRY_PLUGIN_TYPE_REGISTRATION_STOP, pluginType.getName() );
}
对于每一种插件类型PluginTypeInterface都需要调用:
registry.registerType( pluginType )
在registerType()方法会调用
pluginType.searchPlugins()
在PluginRegistry.init()方法还会加载KETTLE_PLUGIN_CLASSES配置项中的插件,多个插件以逗号隔开。通常都是在开发debug模式才用这个配置项来加载需要测试的插件。
searchPlugins()方法默认会搜索3种类型的插件:
(1) 内置插件(registerNatives)
registerNatives();
(2) 注解插件(registerPluginJars)
registerPluginJars();
(3) xml配置的外置插件(registerXmlPlugins)
registerXmlPlugins();
例如:
(1) StepPluginType的registerNatives方法会遍历加载kettle内置的kettle-steps.xml中所有的step组件,然后通过调用:
registry.registerPlugin( pluginType, pluginInterface )
将组件注册到PluginRegistry。
(2) registerPluginJars方法会从以下文件夹加载jar包:
- plugins/
- {kettle.dir}/plugins/
如果jar包中含有该插件类型的注解来修饰一个插件类,那么该插件类将被注册到PluginRegistry。
(3) registerXmlPlugins方法会从特定文件夹下去加载plugin.xml文件:
plugins/steps/
{kettle.dir}/plugins/steps/
并从该文件中获取对应的插件并注册到PluginRegistry。
PluginRegistry维护一个HashMap来存放注册的组件(pluginMap),其中key是每一种插件类型,value保存该插件类型的所有插件类集合(List)。
总结:
(1) 在KettleEnvironment.init()方法里面主要实现了Kettle各种插件类型插件的动态加载以及注册到PluginRegistry。这个方法将所有插件动态加载到项目的classpath中,包括插件依赖的jar包。
(2) 如果开发kettle客户端程序,那么首要调用的方法肯定是KettleEnvironment.init()。
转载自:http://blog.csdn.net/d6619309/article/details/50654355
加载插件流程/架构
kettle api 方式加载plugins 里面的插件
参考URL: https://blog.csdn.net/dqswuyundong/article/details/64127178
[推荐]学习kettle插件
参考URL: https://blog.csdn.net/qq_38340127/article/details/76998003
[推荐]kettle插件加载流程
参考URL: https://blog.csdn.net/czmacd/article/details/52957188
从功能上看,Kettle内部的对象和外部插件没有任何区别。因为它们使用的API都是一样的,它们只是在运行时的加载方式不同。
从Kettle4以后,Kettle内部有一个插件注册系统,它负责加载各种内部和外部插件。插件有以下两个标识属性。
插件类型:由PluginTypeInterface接口定义。例如StepPluginType、JobEntryPluginType、PartitionerPluginType和RepositoryPluginType。
插件ID:这是一个字符串数组,用来唯一标识一个插件。因为旧的插件可以被新的插件代替,一个插件可以有多个ID。在大多数情况下,插件只使用一个单一的字符串,如TableInput是“表输入”步骤的ID,MYSQL是MySQL数据库类型的ID。
当Kettle环境初始化以后,插件注册系统首先加载所有的内部对象,Kettle读取下面的配置文件来加载内部对象,这些配置文件位于Kettle的.jar文件中。
Kettle-steps.xml:内部转换步骤。
Kettle-job-entries.xml:内部作业项。
Kettle-partition-plugins.xml:内部分区类型。
Kettle-database-types.xml:内部数据库类型。
Kettle-repositories.xml:内部资源库类型。
插件注册系统加载了所有的内部对象后,就要搜索可用的外部插件。通过浏览plugins/目录的各个子目录下的.jar文件来完成。它搜索特定的Kettle annotations来判断一个类是否是插件。
因为在内部对象加载后才加载插件,所以插件会替代相同ID的已加载的内部对象。例如,你创建了插件,插件的ID是TableInput,就可以替换Kettle标准的“表输入”步骤。这个功能可以让你用插件替换Kettle内置的步骤。可以通过子类继承方式,直接扩展已有步骤的某些功能。
根据jar包注册插件(通过注解方释来描述插件)。首先,Windows下先会默认从[plugins, plugins\steps, C:\Users\Administrator.kettle\plugins, C:\Users\Administrator.kettle\plugins\steps]这几个目录中查找StepPluginType类型的插件jar包;然后,调用handlePluginAnnotation():通过注解解析出所有插件相关的描述属性,并构造Plugin对象;接着,把该插件信息保存到pluginMap与categoryMap对应插件类型的value(List)中;最后 ,触发该插件类型的添加、改变插件的事件 。
- 如何修改加载插件的路径
关键字:
KETTLE_PLUGIN_BASE_FOLDERS
Kettle — 转换机制
[推荐]参考URL: https://blog.csdn.net/u013468915/article/details/82630120
- StepInterface继承体系
BaseStep实现了StepInterface是各step具体实现类的基类。完成了公用的处理函数,如putRow(),但是对于更具体的processRow()在StepBase的子类中。StepBase的主要成员有
public ArrayList inputRowSets,outputRowSets;
StepBase的子类每次从inputRowSets中取出一行数据,向outputRowSets中写入一行数据。
例如: TableInputData
- StepDataInterface继承体系
实现StepDataInterface接口的类为数据类,当插件执行时,对于每个执行执行的线程都是唯一的。保存于step相关的数据信息,比如行的元数据信息。
步骤间交互通信类
RowSet
RowSet的实现类,负责步骤之间的相互通信,rowset对象即是前一个step的成员也是后一个step的成员,访问是线程安全的。
RowSet类中包含源step,目标step和由源向目标发送的一个rowMeta和一组data。其中data数据是以行为单位的队列(queueArray)。一个RowSet作为此源step的outputrowsets的一部分。同时作为目标step的inputRowsets一部分。源Step每次向队列中写一行数据,目标step每次从队列中读取一行数据。
行元数据
所有的data均擦除为object对象。步骤与步骤之间以行为单位进行处理,自然需要知道每行的结构,即行元数据。行元数据至少需要包括类型、名称,当然还可能包括字段长度、精度等常见内容。
行元数据不仅在执行的时候需要,而且在转换设置的时候同样需要。每个步骤的行元数据都会保存在.ktr文件或者数据库里面,所以可以根据步骤名称从TransMeta对象中获取行元数据。
行元数据的UML类图结构如下所示,主要有单元格元数据组成行元数据。在现有的版本中,支持的数据类型有String、Date、BigNumber、Boolean、SerializableType、Binary、Integer、Numberic。
元数据与数据关系
Trans中的ETL过程(每个step)以行为单位处理,其中行的元数据信息RowMeta和数据信息统一保存在RowSet对象中。
RowSet的数据信息在queArray队列中。
其他参考
Kettle日常使用汇总整理
参考URL: https://www.cnblogs.com/lsy-blogs/p/8268318.html
其他概念基础
ETL\数据仓库\大数据相关概念
[推荐]漫画:什么是数据仓库?
参考URL: https://blog.csdn.net/bjweimengshu/article/details/79256504
基于大数据体系构建数据仓库——第一节——认识数据仓库
参考URL: https://blog.csdn.net/dajiangtai007/article/details/80238539
传统数仓建设更多的基于成熟的商业数据集成平台,比如Teradata、Oracle、Informatica等,技术体系比较成熟完善,但相对比较封闭,对实施者技术面要求也相对专业且单一,一般更多应用于银行、保险、电信等“有钱”行业。
基于大数据的数仓建设一般是基于非商业、开源的技术,常见的是基于hadoop生态构建,涉及技术较广泛、复杂,同时相对于商业产品,稳定性、服务支撑较弱,需要自己维护更多的技术框架。
Apache Hive是一个构建在Hadoop基础设施之上的数据仓库。通过Hive可以使用HQL语言查询存放在HDFS上的数据。HQL是一种类SQL语言,这种语言最终被转化为Map/Reduce. 虽然Hive提供了SQL查询功能,但是Hive不能够进行交互查询–因为它只能够在Haoop上批量的执行Hadoop。
HIVE和HBASE区别
参考URL: https://www.cnblogs.com/justinzhang/p/4273470.html
hive与hbase的联系与区别
参考URL: https://www.cnblogs.com/xubiao/p/5571176.html
hbase和hive的差别是什么,各自适用在什么场景中?
参考URL: http://blog.51cto.com/xpleaf/2090122
[推荐]Hive、Pig、HBase的关系与区别,值得收藏!
参考URL: https://blog.csdn.net/qq_33161208/article/details/79441129
应用场景
Hive适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。Hive不应该用来进行实时的查询。因为它需要很长时间才可以返回结果。
Hbase非常适合用来进行大数据的实时查询。Facebook用Hbase进行消息和实时的分析。它也可以用来统计Facebook的连接数。
总结
Hive和Hbase是两种基于Hadoop的不同技术--Hive是一种类SQL的引擎,并且运行MapReduce任务,Hbase是一种在Hadoop之上的NoSQL 的Key/vale数据库。当然,这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也可以从Hive写到Hbase,设置再从Hbase写回Hive。
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。
在大数据架构中,Hive和HBase是协作关系,数据流一般如下:
通过ETL工具将数据源抽取到HDFS存储;
通过Hive清洗、处理和计算原始数据;
HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
数据应用从HBase查询数据;
数据仓库和大数据
浅谈数据仓库和大数据
参考URL: https://blog.csdn.net/Gospelanswer/article/details/78208761
[推荐]谈谈大数据时代下的数据仓库
参考URL: https://blog.csdn.net/wang7807564/article/details/81607866
数据仓库是一个抽象的概念,而实现的载体则是我们常见的各种数据库表。比如传统行业中用到的Oracle、Teradata(简称TD)、GreenPlum(简称GP),互联网行业中用到的Hive、Spark。它的一个主要应用点的体现就是我们企业中建设的数据平台。
数据仓库与数据库的区别,一个以数据分析为主,另一个以数据的增删查改为主。