ElasticSearch 的 from+size、scroll、scroll-scan、sliced scroll-sacn、search after
参考文章:
使用scroll实现Elasticsearch数据遍历和深度分页
Elasticsearch 5.x 源码分析(3)from size, scroll 和 search after
ElasticSearch官方文档
Elasticsearch搜索类型讲解
理解“query then fetch”和“dfs query then fetch”
目录
1、ElasticSearch 搜索内部执行原理
(1)Query阶段
(2)Fetch 阶段
(3)ES搜索类型
2、from+size
3、scroll
(1)初始化
(2)遍历
4、Scroll-Scan
5、Sliced scroll-scan
6、search after
1、ElasticSearch 搜索内部执行原理
ElasticSearch 中,搜索一般包括两个阶段,query 和 fetch 阶段,可以简单的理解,query 阶段确定要取哪些 doc,fetch 阶段取出具体的 doc。
(1)Query阶段
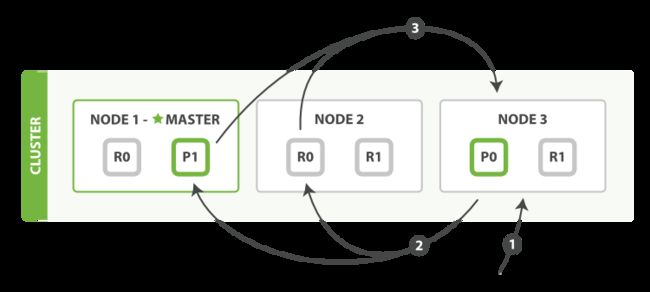
如上图所示,描述了一次搜索请求的 query 阶段。
-
Client 发送一次搜索请求,node3 接收到请求,然后,node3 创建一个大小为 from + size 的优先级队列用来存结果,我们管 node3 叫 coordinating node。
-
coordinating node 将请求广播到涉及到的 shards,每个 shard 在内部执行搜索请求,然后,将结果存到内部的大小同样为 from + size 的优先级队列里,可以把优先级队列理解为一个包含 topN 结果的列表。
-
每个 shard 把暂存在自身优先级队列里的数据返回给 coordinating node,coordinating node 拿到各个 shards 返回的结果后对结果进行一次合并,产生一个全局的优先级队列,存到自身的优先级队列里。
在上面的例子中,coordinating node 拿到 ( from + size ) * 3 条数据,然后合并排序后选择前面的 from + size 条数据存到优先级队列,以便 fetch 阶段使用。另外,各个分片返回给 coordinating node 的数据用于选出前 from + size 条数据,所以只需要返回唯一标记 doc 的 _id 以及用于排序的 _score 即可,这样也可以保证返回的数据量足够小。
coordinating node 计算好自己的优先级队列后,query 阶段结束,进入 fetch 阶段。
(2)Fetch 阶段
query 阶段只是知道了要取哪些数据,但是并没有取具体的数据,这就是 fetch 阶段要做的。
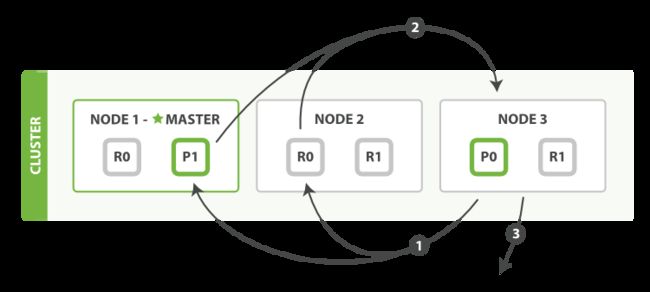
上图展示了 fetch 过程:
-
coordinating node 发送 GET 请求到相关 shards。
-
shard 根据 doc 的 _id 取到数据详情,然后返回给 coordinating node。
-
coordinating node 返回数据给 Client。
coordinating node 的优先级队列里有 from + size 个 _doc _id,但是在 fetch 阶段,并不需要取回所有数据,只需要取优先级队列里的第 from 到 from + size 条数据即可。
需要取的数据可能在不同分片,也可能在同一分片,coordinating node 使用 multi-get 来避免多次去同一分片取数据,从而提高性能。
(3)ES搜索类型
-
query and fetch:向索引的所有 shard 都发出查询请求,各 shard 返回的时候把元素文档( document )和计算后的排名信息一起返回。这种搜索方式是最快的。因为相比下面的几种搜索方式,这种查询方法只需要去 shard 查询一次。但是各个 shard 返回的结果的数量之和可能是用户要求的 size 的 n 倍( n 为 shard 数)。目前es5.3版本以后已经舍弃这个类型了。
-
query then fetch(默认的搜索方式):如果你搜索时,没有指定搜索方式,就是使用的这种搜索方式。这种搜索方式,大概分两个步骤,第一步,先向所有的 shard 发出请求,各 shard 只返回排序和排名相关的信息(注意,不包括文档 document ),然后按照各 shard 返回的分数进行重新排序和排名,取前 size 个文档。然后进行第二步,去相关的 shard 取 document。这种方式返回的 document 与用户要求的 size 是相等的。
-
DFS query and fetch:这种方式比第一种方式多了一个初始化散发( initial scatter )步骤(预查询每个 shard,询问 Term 和Document frequency,并根据 Term 和 Document frequency 进行打分),有这一步,据说可以更精确控制搜索打分和排名。目前es5.3版本以后已经舍弃这个类型了。
-
DFS query then fetch:比第2种方式多了一个初始化散发( initial scatter )步骤。
2、from+size
这种方式需要查询 from + size 的条数时,coordinate node 会向该索引的其余的 shards 发送同样的请求,等所有 shards 返回一共( from + size ) * shards 条数据后,在 coordinate node 做一次排序,最终抽取出真正的第 from 到 from + size 条结果。
举个例子,一个索引,有10亿数据,分10个 shards,然后,一个搜索请求,from=1,000,000,size=100,这时候,会带来严重的性能问题:CPU、内存、IO、网络带宽等等。CPU、内存和IO消耗容易理解,网络带宽问题稍难理解一点。在 query 阶段,每个 shards 需要返回 1,000,100 条数据给 coordinating node,而 coordinating node 需要接收 10 * 1,000,100 条数据,即使每条数据只有 _doc _id 和 _score,这数据量也很大了,而且,这才一个查询请求,那如果再乘以100呢?
所以在深度分页遍历时,from + size这种方式并不合适,但是可以采用 Elasticsearch 提供的 scroll 方式来实现深度分页的遍历。
String ip = "ip";
int port = 9200;
String index_name = "index";
String user_name = "user";
String passwd = "passwd";
RestClientBuilder builder = RestClient.builder(new HttpHost(ip, port, "http"));
// 鉴权
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(user_name, passwd));
builder.setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider));
RestHighLevelClient client = new RestHighLevelClient(builder);
SearchRequest searchRequest = new SearchRequest().indices(index_name);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(QueryBuilders.rangeQuery("gid").from(0).to(1000))
.from(0)
.size(200);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);3、scroll
scroll 可以理解为关系型数据库里的 cursor,因此,scroll 并不适合用来做实时搜索,而更适用于后台批处理任务,比如群发。
scroll 可以分为初始化和遍历两步,初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照,在遍历时,从这个快照里取数据,也就是说,在初始化后对索引插入、删除、更新数据都不会影响遍历结果。
from + size 和 scroll 都需要执行多次 fetch 阶段,但是相比于 from + size 方式,scroll 只做一次 query 阶段,一次将所有满足条件的结果都取出来,缓存到内存中,然后每次请求都是先在内存的快照中找到需要的 docid,然后去 shards 中获取数据。也就是说,from + size 会 query 多次,分页越深 query 的条数越多;而 scroll 一次会将全量数据取出,分页的深度对其没有影响。
scroll 使用方式如下,
(1)初始化
POST ip:port/index/type/_search?scroll=1m
{
"query": { "match_all": {}}
}初始化时需要像普通 search 一样,指明 index 和 type (当然,search 是可以不指明 index 和 type 的),然后,加上参数 scroll,表示暂存搜索结果的时间,其它就像一个普通的 search 请求一样。初始化返回一个 _scroll_id,_scroll_id 用来下次取数据用。
(2)遍历
POST /_search?scroll=1m
{
"scroll_id":"XXXXXXXXXXXXXXXXXXXXXXX I am scroll id XXXXXXXXXXXXXXX"
}这里的 scroll_id 即 上一次遍历取回的 _scroll_id 或者是初始化返回的 _scroll_id,同样的,需要带 scroll 参数。 重复这一步骤,直到返回的数据为空,即遍历完成。注意,每次都要传参数 scroll,刷新搜索结果的缓存时间。另外,不需要指定 index 和 type。设置 scroll 的时候,需要使搜索结果缓存到下一次遍历完成,同时,也不能太长,毕竟内存空间有限。
String ip = "ip";
int port = 9200;
String index_name = "index";
String user_name = "user";
String passwd = "passwd";
RestClientBuilder builder = RestClient.builder(new HttpHost(ip, port, "http"));
// 鉴权
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(user_name, passwd));
builder.setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider));
RestHighLevelClient client = new RestHighLevelClient(builder);
SearchRequest searchRequest = new SearchRequest()
.indices(index_name)
.scroll("2m");
// 初始化
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(QueryBuilders.rangeQuery("gid").from(0).to(1000))
.size(200);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 遍历
String scrollId = searchResponse.getScrollId();
while (true) {
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId).scroll("2m");
searchResponse = client.scroll(scrollRequest, RequestOptions.DEFAULT);
SearchHits hits2 = searchResponse.getHits();
if (hits2.getHits().length == 0)
break;
scrollId = searchResponse.getScrollId();
}4、Scroll-Scan
Elasticsearch 提供了 Scroll-Scan 方式进一步提高遍历性能。还是上面的例子,微信大V要给粉丝群发这种后台任务,是不需要关注顺序的,只要能遍历所有数据即可,这时候,就可以用Scroll-Scan。
Scroll-Scan 的遍历与普通 Scroll 一样,初始化存在一点差别。
POST ip:port/index/type/_search?search_type=scan&scroll=1m&size=50
{
"query": { "match_all": {}}
}需要指明参数:
-
search_type。赋值为 scan,表示采用 Scroll-Scan 的方式遍历,同时告诉 Elasticsearch 搜索结果不需要排序。
-
scroll。同上,传时间。
-
size。与普通的 size 不同,这个 size 表示的是每个 shard 返回的 size 数,最终结果最大为 number_of_shards * size。
Scroll-Scan 方式与普通 Scroll 有几点不同:
-
Scroll-Scan 结果没有排序,按 index 顺序返回,没有排序,可以提高取数据性能。
-
初始化时只返回 _scroll_id,没有具体的 hits 结果。
-
size 控制的是每个分片的返回的数据量而不是整个请求返回的数据量。
Scroll-Scan在ES 2.1版本中已经启用,但是仍可以使用 _doc 来实现,在请求时加上下述参数即可。
"sort":["_doc"]// 初始化阶段加上sort by _doc即可
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(QueryBuilders.rangeQuery("gid").from(0).to(1000))
.size(200)
.sort("_doc");5、Sliced scroll-scan
这种方式实际上就是并行的scroll-scan,通过传递slice参数,达到分块独立获取数据的目的。
POST ip:port/index/type/_search?scroll=1m
{
"query": { "match_all": {}},
"slice": {
"id": 0,
"max": 5
}
}
POST ip:port/index/type/_search?scroll=1m
{
"query": { "match_all": {}},
"slice": {
"id": 1,
"max": 5
}
}上边的示例可以单独请求两块数据,最终五块数据合并的结果与直接scroll-scan相同。其中max是分块数,id是第几块。官方文档中建议max的值不要超过shard的数量,否则可能会导致内存爆炸。
final int max = 5;
final CountDownLatch countDownLatch = new CountDownLatch(max);
for (int j = 0; j < max; j++) {
final int i = j;
Thread sliceThread = new Thread(new Runnable() {
@Override
public void run() {
try {
// scroll-scan 代码,唯一区别就是添加slice参数
/*SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(QueryBuilders.rangeQuery("gid").from(0).to(100))
.slice(new SliceBuilder("gid", i, max))
.size(100)
.sort("_doc");*/
countDownLatch.countDown();
} catch (IOException e) {
e.printStackTrace();
}
}
});
sliceThread.start();
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}6、search after
这是 Elasticsearch 5 新引入的一种分页查询机制,其实原理几乎就是和 scroll 一样,简单三句话介绍 search after 怎么用就是:
-
它必须先要指定排序(因为一定要按排序记住坐标)
-
必须从第一页开始搜起(你可以随便指定一个坐标让它返回结果,只是你不知道会在全量结果的何处)
-
从第一页开始以后每次都带上 search_after=lastEmittedDocFieldValue 从而为无状态实现一个状态,说白了就是把每次固定的from + size 偏移变成一个确定值 lastEmittedDocFieldValue,而查询则从这个偏移量开始获取 size 个 doc(每个 shard 获取size 个,coordinate node 最后汇总 shards * size 个。
最后一点非常重要,也就是说,无论去到多少页,coordinate node 向其它 node 发送的请求始终就是请求 size 个 docs,是个常量,而不再是 from + size那样,越往后,你要请求的 docs 就越多,而要丢弃的垃圾结果也就越多。也就是,如果我要做非常多页的查询时,最起码 search after 是一个常量查询延迟和开销,并无什么副作用。search after的原理就是这篇文章(业界难题-“跨库分页”的四种方案)里的业务折中法-禁止跳页查询。
search after 不用取全量数据快照,每次记录上一次的游标,然后再执行一次 from + size 的 query 阶段,但与 from + szie 不同的是,search after 会加上一个限制条件 filter_value>游标指向的value(即上文请求中的 lastEmittedDocFieldValue)。这样每次就只会请求 size * shards 条数据,保证其实一个常量查询延迟和开销。相比于 scroll 没有第一次全量的排序,而且不会存在快照过期导致的数据实时性问题。