Flume+Elasticsearch搭建实时日志分析系统
最近做一个检测全球网络状况的项目,主要用于检测全球各个国家,地区的机房网络状况,服务的性能,DNS解析等等...情况的数据,通过中央服务器添加任务,下发任务到部署在全球各个国家和地区的minipc,minipc将获取到的数据反馈到监控服务,然后进行数据整合和分析提供报表,供公司更有针对性的优化网站性能。
之所以采用Flume + Elasticsearch,而没有采用ELK(elasticsearch logstash kibana),主要是因为之前的一些积累。hadoop集群的日志采集都是用Flume,而且对Flume比较熟悉,少了很多的学习成本。
总体架构:
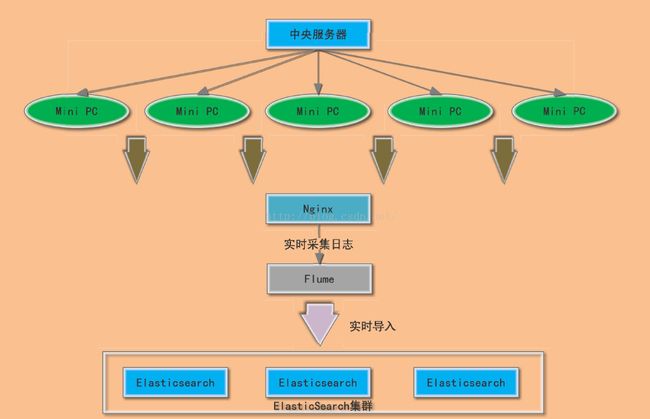
总体流程:
1,后台编辑任务,并制定任务策略
2,后台根据任务策略,分发任务到指定的Mini PC
3,Mini PC获取到任务后,执行任务,并将执行后的任务数据发送的Nginx(现网Nginx使用keepalived做了高可用)
4,Flume通过tail命令实时获取Nginx日志
5,Flume将日志实时导入到Elasticsearch集群
6,报表系统根据用户输入的查询条件以报表,列表,图表等形式展现给用户。
实际项目要比以上流程复杂很多,其中涉及到将数据导入hadoop做离线分析。本章主要讲Flume+Elasticsearch搭建实时日志分析系统,以及如何自定义处理Nginx日志数据。
| 属性名称 |
默认值
|
描述
|
|
channel |
– |
|
|
type |
– |
组件的名称:org.apache.flume.sink.elasticsearch.ElasticSearchSink |
|
hostNames |
– |
Elasticsearch集群的服务器列表(hostname:port),用逗号分隔,如果没有指定端口,默认是:9300 |
|
indexName |
flume |
索引名称会追加时间,例如:‘flume’ -> ‘flume-yyyy-MM-dd’,同时也支持任意标题替换,例如:flume-%{header},则会在Event的header中查询key为fish的值来替换作为索引名称。注:indexName必须小写
|
|
indexType |
logs |
indexType也支持任意标题替换 |
|
clusterName |
elasticsearch |
连接到Elasticsearch集群的名称 |
|
batchSize |
100 |
每个事务写入多少个Event
|
|
ttl |
– |
ttl 的时间,过期了会自动删除文档,如果没有设置则永不过期,ttl使用integer或long型,单位可以是:ms (毫秒), s (秒), m (分), h (小时), d (天) and w (周)。例如:a1.sinks.k1.ttl = 5d则表示5天后过期。
|
|
serializer |
org.apache.flume.sink.elasticsearch.ElasticSearchLogStashEventSerializer |
|
|
serializer.* |
– |
|
log_format main '["$remote_addr","$http_x_forwarded_for","$remote_user","$request","$request_body","$request_uri","$status","$body_bytes_sent","$bytes_sent","$connection","$connection_requests","$msec","$pipe","$http_referer","$http_user_agent","$request_length","$request_time","$upstream_response_time","$time_local","$gzip_ratio"]';
Flume配置
a1.sources.source1.type = exec
a1.sources.source1.command = tail -n 0 -F /home/nginx/logs/access.log
a1.sources.source1.channels = channel1
a1.sources.source1.interceptors = i1
a1.sources.source1.interceptors.i1.type = timestamp
a1.sinks.sink1.type = org.apache.flume.sink.elasticsearch.ElasticSearchSink
a1.sinks.sink1.batchSize = 50
a1.sinks.sink1.hostNames = 10.0.1.75:9300;10.0.1.76:9300;10.0.1.77:9300
a1.sinks.sink1.indexName = fish-test
a1.sinks.sink1.indexType = fish-yyyy-MM-dd
a1.sinks.sink1.clusterName = bicloud
a1.sinks.sink1.serializer=org.apache.flume.sink.elasticsearch.ElasticSearchNginxEventSerializer
a1.sinks.sink1.serializer.fields=remote_addr http_x_forwarded_for remote_user request request_body request_uri status body_bytes_sent bytes_sent connection connection_requests msec pipe http_referer http_user_agent request_length request_time upstream_response_time time_local gzip_ratio
a1.sinks.sink1.serializer.fields.status.serializer=int
a1.sinks.sink1.serializer.fields.time_local.serializer=date
a1.sinks.sink1.serializer.fields.time_local.format=dd/MMMMM/yyyy:HH:mm:ss z
a1.sinks.sink1.serializer.fields.time_local.locale=en
a1.channels.channel1.type = memory
a1.channels.channel1.capacity = 100
a1.channels.channel1.transactionCapacity = 80
a1.sources.source1.channels = channel1
a1.sinks.sink1.channel = channel1org.apache.flume.sink.elasticsearch.ElasticSearchNginxEventSerializer是自定义的Nginx解析类,将每条日志解析成Json数组,及数组每个字段在Elasticsearch中对应的字段,并且各个字段可以定义自己想要的类型。
详情查看:https://github.com/qianshangding/fish-flume
源码只实现了boolean,date,double,int,integer,long,string,实际业务我们对request_body,ip地址,经度纬度都做了处理,由于和业务相关就不上传了,可以根据自身业务的需求实现Serializer接口。