【工作】日志检索结果的排序改进分析
下图是现在生产环境的部署图,索引文件分布在70-73服务器上,这4台服务器在一个集群里,每个节点的
search service会查询该节点上的索引文件(阶段1),然后在71或者72服务器的query client service里获得汇合后的数据(阶段2)。
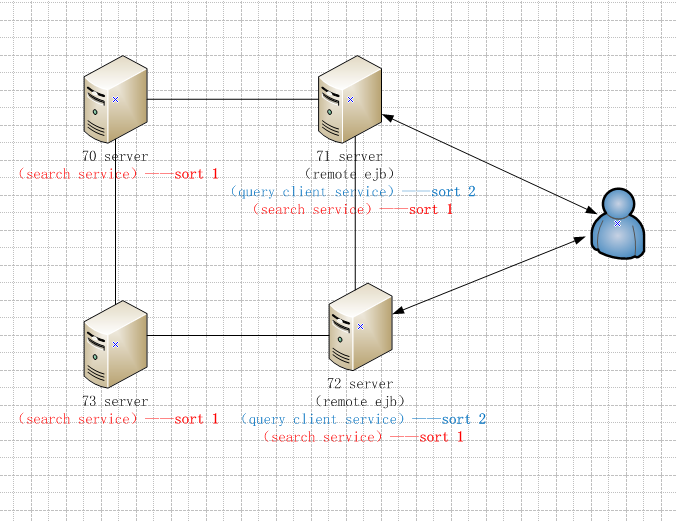
阶段1和阶段2都有排序,其中阶段1的排序可以基于Lucene的排序机制来完成,阶段2的排序可以通过相关排序算法完成(比如Arrays.sort(hitdoc[]))。
当前,阶段1的排序是根据相关性打分来排序,阶段2的排序是根据将阶段1的产生的结果的打分(对原始相关性打分做了改造:(int)score * 100)排序,并且阶段2待排序的是各个节点汇总后的数据,阶段2的排序结果将最终展示给用户。
如果,想要对结果根据时间, 分数+时间, 分数 来排序,该如何实现?
按照 分数 排序
Arrays.sort(hits, new Comparator() {
@Override
public int compare(SearchHit o1, SearchHit o2) {
return o1.getScore() - o2.getScore();
}
}); 按照 时间 排序
Arrays.sort(hits, new Comparator() {
@Override
public int compare(SearchHit doc1, SearchHit doc2) {
return (int) (doc1.getTime() - doc2.getTime());
}
}); 按照 分数+时间(先按分数排序,分数相同的结果按照时间排序)
Arrays.sort(hits, new Comparator() {
@Override
public int compare(SearchHit doc1, SearchHit doc2) {
return (doc1.getScore() != doc2.getScore()) ? -(doc1.getScore() - doc2.getScore()) : (int) (doc1.getTime() - doc2.getTime());
}
});
按照 时间+分数 排序(先按时间排序,时间相同的结果按照分数排序)
Arrays.sort(hits, new Comparator() {
@Override
public int compare(SearchHit doc1, SearchHit doc2) {
return (doc1.getTime() != doc2.getTime()) ? (int) (doc1.getTime() - doc2.getTime()): -(doc1.getScore() - doc2.getScore());
}
});
尽管对单个节点上的结果进行排序不影响最终给用户的显示(反而会影响性能),如果想要对单节点上数据排序,可以通过如下方式
按时间降序排序
//If true, then scores are returned for every matching document in //TopFieldDocs.
boolean doTrackScores = true;
boolean doMaxScore = false;
indexSearch.setDefaultFieldSortScoring(doTrackScores , doMaxScore);
Sort sort = new Sort(new SortField("time", SortField.STRING, true));
TopDocs docs = searcher.search(request.getQuery(), null, maxResultSize, sort);
附
Sort/SortField/FieldCache