作者:张丰哲链接:https://www.jianshu.com/p/af7043e6c8f9來源:
Redis基础类型回顾
String:string是最简单的类型,一个key对应一个value。string类型是二进制安全的,意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象。从内部实现来看其实string可以看作byte数组,最大上限是1G字节。Redis中最基本,也是最简单的数据类型。注意,VALUE既可以是简单的String,也可以是复杂的String,如JSON,在实际中常常利用fastjson将对象序列化后存储到Redis中。另外注意mget批量获取可以提高效率。
string类型的定义:struct sdshdr { long len; long free; char buf[]; };
1. len是buf数组的长度。
2. free是数组中剩余可用字节数,由此可以理解为什么string类型是二进制安全的了,因为它本质上就是个byte数组,当然可以包含任何数据了
3. buf是个char数组用于存贮实际的字符串内容,其实char和c#中的byte是等价的,都是一个字节。
另外string类型可以被部分命令按int处理。比如incr等命令,如果只用string类型,redis就可以被看作加上持久化特性的memcached。
setnx:设置key对应的值为string类型的value。如果key已经存在,返回0,nx是not exist的意思。 例如我们添加一个name= HongWan_new的键值对。
setex:设置key对应的值为string类型的value,并指定此键值对应的有效期。 例如我们添加一个haircolor= red的键值对,并指定它的有效期是10秒,可以这样做:setex haircolor 10 red
setrange:设置指定key的value值的子字符串。 例如我们希望将HongWan的126邮箱替换为gmail邮箱,那么我们可以这样做:
redis 127.0.0.1:6379> get name "[email protected]"
redis 127.0.0.1:6379> setrange name 8 gmail.com (integer) 17
redis 127.0.0.1:6379> get name "[email protected]" redis 127.0.0.1:6379>
其中的8是指从下标为8(包含8)的字符开始替换
msetnx: 一次设置多个key的值,成功返回ok表示所有的值都设置了,失败返回0表示没有任何值被设置,但是不会覆盖已经存在的key。
getset:设置key的值,并返回key的旧值。
getrange:获取指定key的value值的子字符串。
Hash:Redis hash是一个string类型的field和value的映射表。它的添加、删除操作都是O(1)(平均)。hash特别适合用于存储对象。相较于将对象的每个字段存成单个string类型。将一个对象存储在hash类型中会占用更少的内存,并且可以更方便的存取整个对象。省内存的原因是新建一个hash对象时开始是用zipmap(又称为small hash)来存储的。这个zipmap其实并不是hash table,但是zipmap相比正常的hash实现可以节省不少hash本身需要的一些元数据存储开销。尽管zipmap的添加,删除,查找都是O(n),但是由于一般对象的field数量都不太多。所以使用zipmap也是很快的,也就是说添加删除平均还是O(1)。
如果field或者value的大小超出一定限制后,Redis会在内部自动将zipmap替换成正常的hash实现。这个限制可以在配置文件中指定。
hash-max-zipmap-entries 64 #配置字段最多64个
hash-max-zipmap-value 512 #配置value最大为512字节
Hash结构可以使你像在数据库中Update一个属性一样只修改某一项属性值,而且还可以快速定位数据。比如,如果我们把表User中的数据可以这样放置到Redis中:Hash存储,KEY:User,Field:USERID,VALUE:user序列化后的string。
实际上,可以利用List的先进先出或者先进后出的特性维护一段列表,比如排行榜、实时列表等,甚至还可以简单的当做消息队列来使用。
hset:设置hash field为指定值,如果key不存在,则先创建。
List:Redis的list类型其实就是一个每个子元素都是string类型的双向链表。链表的最大长度是(2的32次方)。我们可以通过push,pop操作从链表的头部或者尾部添加删除元素。这使得list既可以用作栈,也可以用作队列。
有意思的是list的pop操作还有阻塞版本的,当我们[lr]pop一个list对象时,如果list是空,或者不存在,会立即返回nil。但是阻塞版本的b[lr]pop则可以阻塞,当然可以加超时时间,超时后也会返回nil。为什么要阻塞版本的pop呢,主要是为了避免轮询。举个简单的例子如果我们用list来实现一个工作队列。执行任务的thread可以调用阻塞版本的pop去获取任务这样就可以避免轮询去检查是否有任务存在。当任务来时候工作线程可以立即返回,也可以避免轮询带来的延迟。
实际操作的方法吧:
linsert:在key对应list的特定位置之前或之后添加字符串元素
redis 127.0.0.1:6379> linsert mylist3 before "world" "there"
lset:设置list中指定下标的元素值(下标从0开始)
lrem:从key对应list中删除count个和value相同的元素。 count>0时,按从头到尾的顺序删除,count<0时,按从尾到头的顺序删除。count=0时,删除全部。
ltrim:保留指定key 的值范围内的数据
rpoplpush:从第一个list的尾部移除元素并添加到第二个list的头部,最后返回被移除的元素值,整个操作是原子的。如果第一个list是空或者不存在返回nil。
Set:set的是通过hash table实现的,所以添加、删除和查找的复杂度都是O(1)。hash table会随着添加或者删除自动的调整大小。需要注意的是调整hash table大小时候需要同步(获取写锁)会阻塞其他读写操作,可能不久后就会改用跳表(skip list)来实现,跳表已经在sorted set中使用了。关于set集合类型除了基本的添加删除操作,其他有用的操作还包含集合的取并集(union),交集(intersection),差集(difference)。通过这些操作可以很容易的实现sns中的好友推荐和blog的tag功能。
Set是String类型的不重复无序集合。Set的特点在于,它提供了集合的一些运算,比如交集、并集、差集等。这些运算特性,非常方便的解决实际场景中的一些问题,如共同关注、共同粉丝等。
sadd:向名称为key的set中添加元素
spop:随机返回并删除名称为key的set中一个元素
sdiffstore:返回所有给定key与第一个key的差集,并将结果存为另一个key
smove:从第一个key对应的set中移除member并添加到第二个对应set中
redis 127.0.0.1:6379> smove myset2 myset7 three
scard:返回名称为key的set的元素个数
srandmember:随机返回名称为key的set的一个元素,但是不删除元素
ZSet:是set的一个升级版本,它在set的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会自动重新按新的值调整顺序。可以理解为有两列的mysql表,一列存value,一列存顺序。操作中key理解为zset的名字。和set一样sorted set也是string类型元素的集合,不同的是每个元素都会关联一个double类型的score。sorted set的实现是skip list和hash table的混合体。
当元素被添加到集合中时,一个元素到score的映射被添加到hash table中,所以给定一个元素获取score的开销是O(1),另一个score到元素的映射被添加到skip list,并按照score排序,所以就可以有序的获取集合中的元素。添加,删除操作开销都是O(log(N))和skip list的开销一致,redis的skip list实现用的是双向链表,这样就可以逆序从尾部取元素。sorted set最经常的使用方式应该是作为索引来使用.我们可以把要排序的字段作为score存储,对象的id当元素存储。
zadd:向名称为key的zset中添加元素member,score用于排序。如果该元素已经存在,则根据score更新该元素的顺序
redis 127.0.0.1:6379> zadd myzset 1 "one"
zincrby:如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为increment。
作者:OzanShareing
链接:https://www.jianshu.com/p/d6b176370efd
來源:
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
ZSet就是SortedSet。实际中,很多排序场景都可以考虑ZSet来做。
Redis发展过程中的三种模式:主从、哨兵、集群
Redis的发展可以从版本的变化看出来,从1.X的主从模式,到2.X的哨兵模式,再到今天3.X的集群模式,可以说这些都是Redis保证数据可靠性、高可用的思路。下面我们来简单实践下。环境说明:这里准备了4台Centos Linux,装有redis的3.0版本。
主从模式
Redis早期用于保证数据可靠性的一种简单方式。具体来说,Master(主)可用于写、读,而Slave(从)一般只用于读。通过主从复制可以允许多个slave server 拥有和master server 相同的数据库副本。
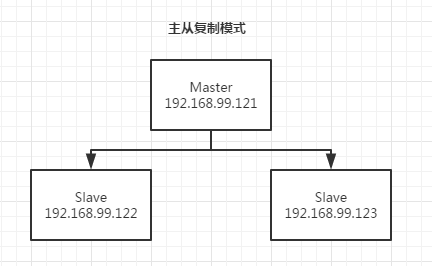
redis 主从复制特点:
master 可以拥有多个slave
多个slave 可以连接同一个master 外,还可以连接到其他slave
主从复制不会阻塞master,在同步数据时,master 可以继续处理client 请求
提高系统的伸缩性
redis 主从复制过程:
当配置好slave 后,slave 与master 建立连接,然后发送sync 命令。无论是第一次连接还是重新连接,master 都会启动一个后台进程,将数据库快照保存到文件中,同时master主进程会开始收集新的写命令并缓存。后台进程完成写文件后,master 就发送文件给slave,slave将文件保存到硬盘上,再加载到内存中,接着master 就会把缓存的命令转发给slave,后续master 将收到的写命令发送给slave。如果master 同时收到多个slave 发来的同步连接命令,master 只会启动一个进程来写数据库镜像,然后发送给所有的slave。
其实在配置上相当简单,只需要在Slave节点配置下Master的IP、PORT、密码即可。
Master info
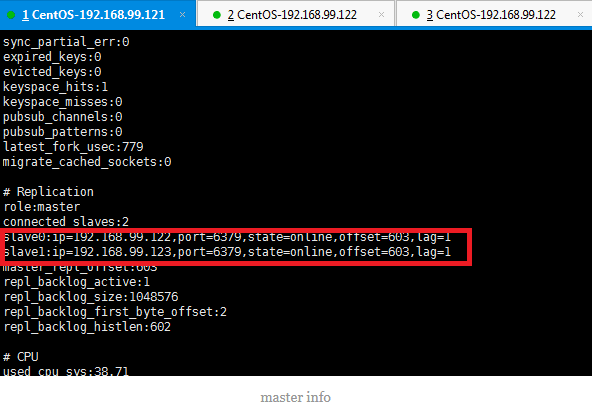
Slave info
一个Master可以拥有多个Slave,主从复制不会阻塞住Master,在同步数据时Master可以继续处理client端请求。
哨兵模式
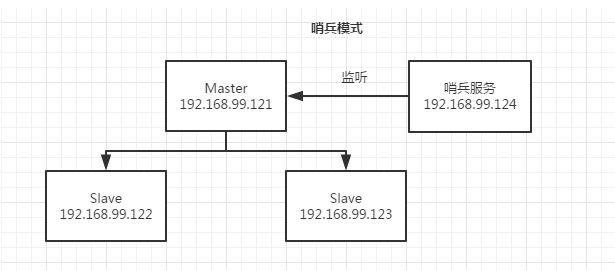
对于主从复制模式而言,有个明显的缺点:一旦主节点挂了,那么redis服务将不可用。在2.X中,为了确保可高用,所以发展出来哨兵模式。顾名思义,就是哨兵站岗,去监听master心跳,如果master挂了,那么将从slave中选举出一个master来,从而实现了故障自动切换。
实质上,在Master-Slave模式基础上,只需要在启动一个哨兵服务进行监听就可以,这个哨兵服务可以部署在Master/Slave上,也可以部署到其他机器上。当然,在实际中为了避免哨兵节点的单点性,也会配置多个哨兵服务。
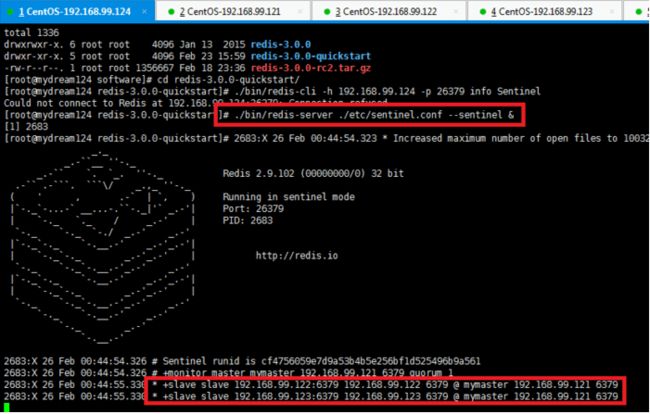
哨兵节点192.168.99.124 sentinel.conf:
sentinel monitor mymaster 192.168.99.121 6379 1
sentinel down-after-milliseconds mymaster 5000
sentinel parallel-syncs mymaster 2
我们需要告诉哨兵服务:
监控的主节点的IP,PORT
如果master挂了,那么选举的时候,slave达到多少票就可以成为主节点
监控主节点的心跳频率
主节点下有多少slave
集群模式
Redis集群模式是目前应用非常广泛的,Redis集群模式的出现,也使得以前的一些Redis技术,比如分片、都不在适用了,同时数据的高可靠、数据分布性、服务的高可用性进一步加强。关于Redis集群将在下一篇博客中详细介绍。
Redis的简单事务
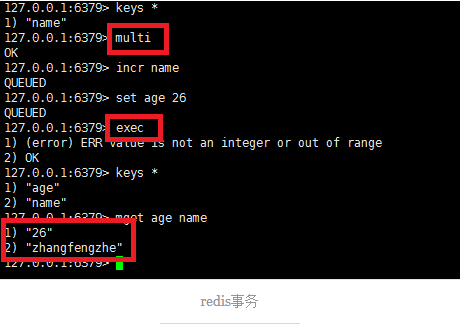
目前来看,Redis对事务的支持是比较简单的,在实际应用中,我们基本上是不会使用的。看一个实例,你就会明白。通过multi开启事务,通过exec来提交事务。可以看到,redis的事务目前是不支持一起成功,一起失败这种基本要求的,即便在事务中有错误,亦不会回退,和MySQL的事务功能相距甚远吧。
redis 只能保证一个client 发起的事务中的命令可以连续的执行,而中间不会插入其他client 的命令。由于redis 是单线程来处理所有client 的请求的所以做到这点是很容易的。一般情况下redis 在接受到一个client 发来的命令后会立即处理并返回处理结果,但是当一个client 在一个连接中发出multi 命令,这个连接会进入一个事务上下文,该连接后续的命令并不是立即执行,而是先放到一个队列中。当从此连接受到exec 命令后,redis 会顺序的执行队列中的所有命令。并将所有命令的运行结果打包到一起返回给client。然后此连接就结束事务上下文。
multi
一般情况下redis在接受到一个client发来的命令后会立即处理并返回处理结果,但是当一个client在一个连接中发出multi命令,这个连接会进入一个事务上下文,该连接后续的命令并不是立即执行,而是先放到一个队列中。当从此连接受到exec命令后,redis会顺序的执行队列中的所有命令。并将所有命令的运行结果打包到一起返回给client。然后此连接就结束事务上下文。
watch
Watch监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。
缺点
1. redis的事务实现是如此简单,当然会存在一些问题。第一个问题是redis只能保证事务的每个命令连续执行,但是如果事务中的一个命令失败了,并不回滚其他命令,比如使用的命令类型不匹配。
2. 当事务的执行过程中,如果redis意外的挂了。很遗憾只有部分命令执行了,后面的也就被丢弃了。当然如果我们使用的append-only file方式持久化,redis会用单个write操作写入整个事务内容。即是是这种方式还是有可能只部分写入了事务到磁盘。发生部分写入事务的情况下,redis重启时会检测到这种情况,然后失败退出。可以使用redis-check-aof工具进行修复,修复会删除部分写入的事务内容。修复完后就能够重新启动了。
Redis持久化机制
Redis是一个支持持久化的内存数据库,也就是说Redis需要经常将内存中的数据同步到硬盘来保证持久化,有2种方式实现。
RDB
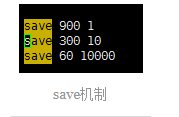
RDB方式,也称作快照snapshotting,将内存中的数据以快照的方式写入到二进制文件dump.rdb中,这种方式也是redis的默认方式。可以在redis.conf中设置保存的策略。一句话:redis在N秒内如果超过M个KEY发生修改则自动做快照保存。
AOF
AOF,即Append-Only File。要知道RDB的方式,是在一定的时间间隔做一次,如果redis意外down掉,这将意味着会丢失最后一次快照后的所有修改数据,这在生产环境将不太可能接受。AOF比RDB有着更好的持久化方式,通过AOF,redis会将每一个收到的写命令都通过write函数追加到命令中,当redis重新启动时,会重新执行文件中保存的写命令来重建数据内容。
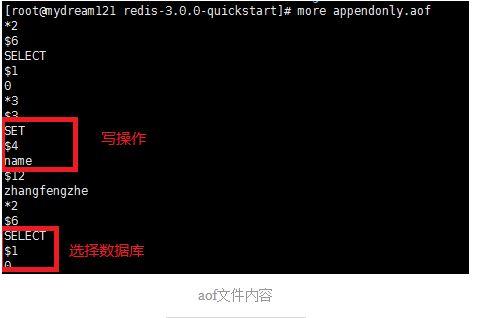
redis.conf:

在实际应用中,为了确保数据高可靠性,应该使用always策略。
Redis案例设计分析
假设一个类似的场景,有几百万,甚至几千万的商品数据,考虑下如何快速实现搜索查询呢?当然,我们不可能直接查询MySQL,应该需要在MySQL上加一层,可以考虑加一层Redis。
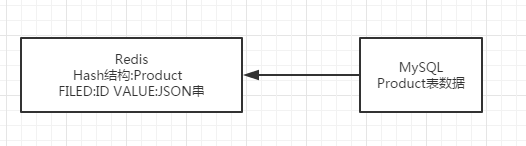
将MySQL中的数据加载至Redis中,给定条件,直接遍历Hash数据进行查询。如果就这样简单的设计的话,对于京东这样的大流量平台,每天有非常多的人进行商品搜索,而且每个人搜索的条件还不一样,根本无法快速响应。
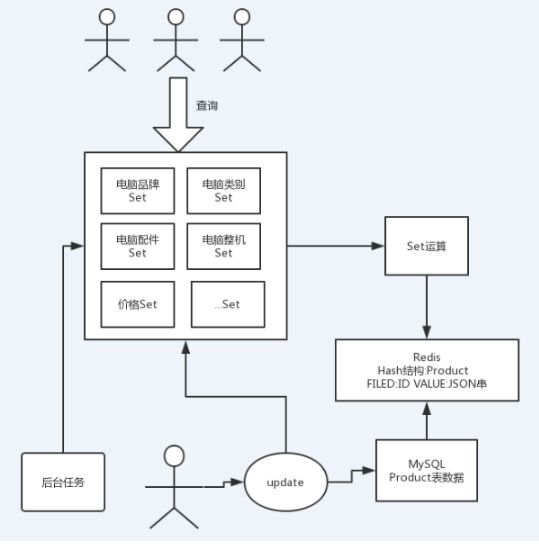
如上图所示,我们可以这样设计:
(1) 我们事先建立好一系列的SET,实际上这些Set都是各种分类的ProductID集合
(2) 用户的搜索条件,实际上就是各种SET进行交、并、补的运算而已
(3) 要知道SET进行运算后的结果,就是ProductID集合,此时范围已经有所缩小,比起直接遍历全部商品数据要小不少。从这里也可以看出,Redis虽然用起来简单,但是要综合运用,并根据业务场景进行设计,还是挺有意思的。