你应该知道的缓存进化史
本文转载自:https://juejin.im/post/5b7593496fb9a009b62904fa#heading-12
1.原始社会 - 查库
在大家的一般开发过程中,会直接查库。在流量不大的时候,查数据库或者读取文件是最为方便,也能完全满足我们的业务要求。
古代社会 - HashMap
当我们应用有一定流量之后或者查询数据库特别频繁,这个时候就可以祭出我们的java中自带的HashMap或者ConcurrentHashMap。我们可以在代码中这么写:
public class CustomerService {
private HashMap<String,String> hashMap = new HashMap<>();
private CustomerMapper customerMapper;
public String getCustomer(String name){
String customer = hashMap.get(name);
if ( customer == null){
customer = customerMapper.get(name);
hashMap.put(name,customer);
}
return customer;
}
}
但是这样做就有个问题HashMap无法进行数据淘汰,内存会无限制的增长,所以hashMap很快也被淘汰了。当然并不是说他完全就没用,就像我们古代社会也不是所有的东西都是过时的,比如我们中华名族的传统美德是永不过时的,就像这个hashMap一样的可以在某些场景下作为缓存,当不需要淘汰机制的时候,比如我们利用反射,如果我们每次都通过反射去搜索Method,field,性能必定低效,这时我们用HashMap将其缓存起来,性能能提升很多。
近代社会 - LRUHashMap
在古代社会中难住我们的问题无法进行数据淘汰,这样会导致我们内存无限膨胀,显然我们是不可以接受的。有人就说我把一些数据给淘汰掉呗,这样不就对了,但是怎么淘汰呢?随机淘汰吗?当然不行,试想一下你刚把A装载进缓存,下一次要访问的时候就被淘汰了,那又会访问我们的数据库了,那我们要缓存干嘛呢?
所以聪明的人们就发明了几种淘汰算法,下面列举下常见的三种FIFO,LRU,LFU(还有一些ARC,MRU感兴趣的可以自行搜索):
- FIFO:先进先出,在这种淘汰算法中,先进入缓存的会先被淘汰。这种可谓是最简单的了,但是会导致我们命中率很低。试想一下我们如果有个访问频率很高的数据是所有数据第一个访问的,而那些不是很高的是后面再访问的,那这样就会把我们的首个数据但是他的访问频率很高给挤出。
- LRU:最近最少使用算法。在这种算法中避免了上面的问题,每次访问数据都会将其放在我们的队尾,如果需要淘汰数据,就只需要淘汰队首即可。但是这个依然有个问题,如果有个数据在1个小时的前59分钟访问了1万次(可见这是个热点数据),再后一分钟没有访问这个数据,但是有其他的数据访问,就导致了我们这个热点数据被淘汰。
- LFU:最近最少频率使用。在这种算法中又对上面进行了优化,利用额外的空间记录每个数据的使用频率,然后选出频率最低进行淘汰。这样就避免了LRU不能处理时间段的问题。
上面列举了三种淘汰策略,对于这三种,实现成本是一个比一个高,同样的命中率也是一个比一个好。而我们一般来说选择的方案居中即可,即实现成本不是太高,而命中率也还行的LRU,如何实现一个LRUMap呢?我们可以通过继承LinkedHashMap,重写removeEldestEntry方法,即可完成一个简单的LRUMap。
class LRUMap extends LinkedHashMap {
private final int max;
private Object lock;
public LRUMap(int max, Object lock) {
//无需扩容
super((int) (max * 1.4f), 0.75f, true);
this.max = max;
this.lock = lock;
}
/**
* 重写LinkedHashMap的removeEldestEntry方法即可
* 在Put的时候判断,如果为true,就会删除最老的
* @param eldest
* @return
*/
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > max;
}
public Object getValue(Object key) {
synchronized (lock) {
return get(key);
}
}
public void putValue(Object key, Object value) {
synchronized (lock) {
put(key, value);
}
}
public boolean removeValue(Object key) {
synchronized (lock) {
return remove(key) != null;
}
}
public boolean removeAll(){
clear();
return true;
}
}
在LinkedHashMap中维护了一个entry(用来放key和value的对象)链表。在每一次get或者put的时候都会把插入的新entry,或查询到的老entry放在我们链表末尾。
可以注意到我们在构造方法中,设置的大小特意设置到max*1.4,在下面的removeEldestEntry方法中只需要size>max就淘汰,这样我们这个map永远也走不到扩容的逻辑了,通过重写LinkedHashMap,几个简单的方法我们实现了我们的LRUMap。
现代社会 - Guava cache
在近代社会中已经发明出来了LRUMap,用来进行缓存数据的淘汰,但是有几个问题:
- 锁竞争严重,可以看见我的代码中,Lock是全局锁,在方法级别上面的,当调用量较大时,性能必然会比较低。
- 不支持过期时间
- 不支持自动刷新
所以谷歌的大佬们对于这些问题,按捺不住了,发明了Guava cache,在Guava cache中你可以如下面的代码一样,轻松使用:
public static void main(String[] args) throws ExecutionException {
LoadingCache<String, String> cache = CacheBuilder.newBuilder()
.maximumSize(100)
//写之后30ms过期
.expireAfterWrite(30L, TimeUnit.MILLISECONDS)
//访问之后30ms过期
.expireAfterAccess(30L, TimeUnit.MILLISECONDS)
//20ms之后刷新
.refreshAfterWrite(20L, TimeUnit.MILLISECONDS)
//开启weakKey key 当启动垃圾回收时,该缓存也被回收
.weakKeys()
.build(createCacheLoader());
System.out.println(cache.get("hello"));
cache.put("hello1", "我是hello1");
System.out.println(cache.get("hello1"));
cache.put("hello1", "我是hello2");
System.out.println(cache.get("hello1"));
}
public static com.google.common.cache.CacheLoader<String, String> createCacheLoader() {
return new com.google.common.cache.CacheLoader<String, String>() {
@Override
public String load(String key) throws Exception {
return key;
}
};
}
将会从guava cache原理中,解释guava cache是如何解决LRUMap的几个问题的。
锁竞争
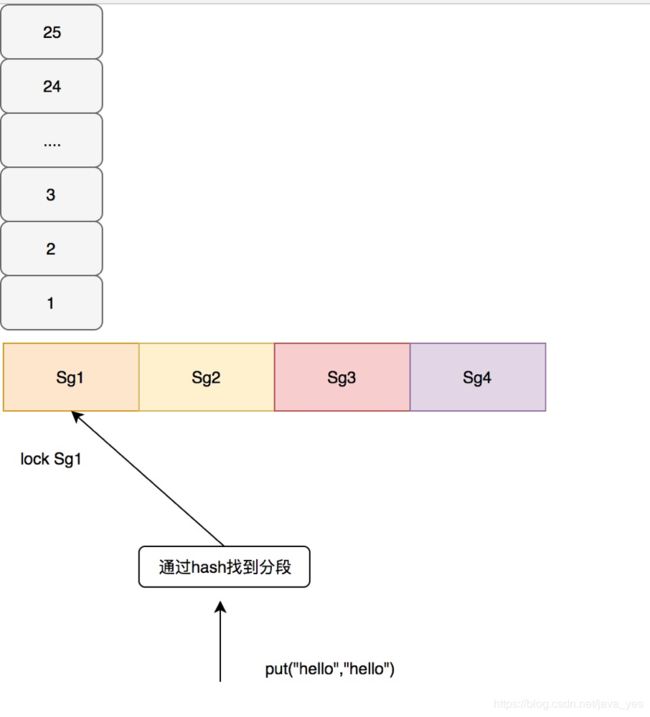
guava cache采用了类似ConcurrentHashMap的思想,分段加锁,在每个段里面各自负责自己的淘汰的事情。在Guava根据一定的算法进行分段,这里要说明的是,如果段太少那竞争依然很严重,如果段太多会容易出现随机淘汰,比如大小为100的,给他分100个段,那也就是让每个数据都独占一个段,而每个段会自己处理淘汰的过程,所以会出现随机淘汰。在guava cache中通过如下代码,计算出应该如何分段。
int segmentShift = 0;
int segmentCount = 1;
while (segmentCount < concurrencyLevel && (!evictsBySize() || segmentCount * 20 <= maxWeight)) {
++segmentShift;
segmentCount <<= 1;
}
上面segmentCount就是我们最后的分段数,其保证了每个段至少10个Entry。如果没有设置concurrencyLevel这个参数,那么默认就会是4,最后分段数也最多为4,例如我们size为100,会分为4段,每段最大的size是25。
在guava cache中对于写操作直接加锁,对于读操作,如果读取的数据没有过期,且已经加载就绪,不需要进行加锁,如果没有读到会再次加锁进行二次读,如果还没有需要进行缓存加载,也就是通过我们配置的CacheLoader,我这里配置的是直接返回Key,在业务中通常配置从数据库中查询。
如下图所示:
过期时间
相比于LRUMap多了两种过期时间,一个是写后多久过期expireAfterWrite,一个是读后多久过期expireAfterAccess。很有意思的事情是,在guava cache中对于过期的Entry并没有马上过期(也就是并没有后台线程一直在扫),而是通过进行读写操作的时候进行过期处理,这样做的好处是避免后台线程扫描的时候进行全局加锁。看下面的代码:
public static void main(String[] args) throws ExecutionException, InterruptedException {
Cache<String, String> cache = CacheBuilder.newBuilder()
.maximumSize(100)
//写之后5s过期
.expireAfterWrite(5, TimeUnit.MILLISECONDS)
.concurrencyLevel(1)
.build();
cache.put("hello1", "我是hello1");
cache.put("hello2", "我是hello2");
cache.put("hello3", "我是hello3");
cache.put("hello4", "我是hello4");
//至少睡眠5ms
Thread.sleep(5);
System.out.println(cache.size());
cache.put("hello5", "我是hello5");
System.out.println(cache.size());
}
输出:
4
1
从这个结果中我们知道,在put的时候才进行的过期处理。特别注意的是我上面concurrencyLevel(1)我这里将分段最大设置为1,不然不会出现这个实验效果的,在上面一节中已经说过,我们是以段位单位进行过期处理。在每个Segment中维护了两个队列:
final Queue<ReferenceEntry<K, V>> writeQueue;
final Queue<ReferenceEntry<K, V>> accessQueue;
writeQueue维护了写队列,队头代表着写得早的数据,队尾代表写得晚的数据。
accessQueue维护了访问队列,和LRU一样,用来我们进行访问时间的淘汰,如果当这个Segment超过最大容量,比如我们上面所说的25,超过之后,就会把accessQueue这个队列的第一个元素进行淘汰。
void expireEntries(long now) {
drainRecencyQueue();
ReferenceEntry<K, V> e;
while ((e = writeQueue.peek()) != null && map.isExpired(e, now)) {
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
while ((e = accessQueue.peek()) != null && map.isExpired(e, now)) {
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
}
上面就是guava cache处理过期Entries的过程,会对两个队列一次进行peek操作,如果过期就进行删除。一般处理过期Entries可以在我们的put操作的前后,或者读取数据时发现过期了,然后进行整个Segment的过期处理,又或者进行二次读lockedGetOrLoad操作的时候调用。
void evictEntries(ReferenceEntry<K, V> newest) {
///... 省略无用代码
while (totalWeight > maxSegmentWeight) {
ReferenceEntry<K, V> e = getNextEvictable();
if (!removeEntry(e, e.getHash(), RemovalCause.SIZE)) {
throw new AssertionError();
}
}
}
/**
**返回accessQueue的entry
**/
ReferenceEntry<K, V> getNextEvictable() {
for (ReferenceEntry<K, V> e : accessQueue) {
int weight = e.getValueReference().getWeight();
if (weight > 0) {
return e;
}
}
throw new AssertionError();
}
上面是我们驱逐Entry的时候的代码,可以看见访问的是accessQueue对其队头进行驱逐。而驱逐策略一般是在对segment中的元素发生变化时进行调用,比如插入操作,更新操作,加载数据操作。
自动刷新
自动刷新操作,在guava cache中实现相对比较简单,直接通过查询,判断其是否满足刷新条件,进行刷新。
其他特性
在Guava cache中还有一些其他特性:
虚引用
在Guava cache中,key和value都能进行虚引用的设定,在Segment中的有两个引用队列:
final @Nullable ReferenceQueue<K> keyReferenceQueue;
final @Nullable ReferenceQueue<V> valueReferenceQueue;
这两个队列用来记录被回收的引用,其中每个队列记录了每个被回收的Entry的hash,这样回收了之后通过这个队列中的hash值就能把以前的Entry进行删除。
删除监听器
在guava cache中,当有数据被淘汰时,但是你不知道他到底是过期,还是被驱逐,还是因为虚引用的对象被回收?这个时候你可以调用这个方法removalListener(RemovalListener listener)添加监听器进行数据淘汰的监听,可以打日志或者一些其他处理,可以用来进行数据淘汰分析。
在RemovalCause记录了所有被淘汰的原因:被用户删除,被用户替代,过期,驱逐收集,由于大小淘汰。
guava cache的总结
细细品读guava cache的源码总结下来,其实就是一个性能不错的,api丰富的LRU Map。爱奇艺的缓存的发展也是基于此之上,通过对guava cache的二次开发,让其可以进行java应用服务之间的缓存更新。
走向未来-caffeine
本文转载自:https://juejin.im/post/5b7593496fb9a009b62904fa#heading-12