机器学习基础知识1

作者:谭东
遵循:BY-SA(署名-相同方式共享4.0协议)![]()
机器学习是人工智能的一个重要的分支。这篇文章将会有助于你对机器学习的理解和认识,带你熟悉其基本原理和基本概念。
先列举下本文将会给你带来的一些名词(这只是本篇博客含有的名词):
数据集(data set)、示例(instance)/样本(sample)、属性(attribute)/特征(feature)、属性值(attribute value)、属性空间(attribute space)/样本空间(sample space)/输入空间、特征向量(feature vector)、维数(dimensionality)、学习(learning)/训练(training)、训练数据(training data)、训练样本(training sample)、训练集(training set)、假设(hypothesis)、真相/真实(ground-truth)、学习器(learner)、标记(label)、样例(example)、标记空间(label space)/输出空间、分类(classification)、回归(regression)、二分类(binary classification)、正类(positive class)、反类(negative class)、多分类(multi-class classification)、测试(testing)、测试样本(testing sample)、聚类(clustering)、监督学习(supervised learning)、无监督学习(unsupervised learning)、泛化(generalization)能力、分布(distribution)、独立同分布(independent and identically distributed)、归纳(induction)、演绎(deduction)、泛化(generalization)过程、特化(specialization)过程、归纳学习(inductive learning)、版本空间(version space)、归纳偏好(inductive bias)/偏好、奥卡姆剃刀(Occam's razor)、没有免费的午餐定理(No Free Lunch Theorem)/NFL定理、深度学习(deep learning)等。
当我们去判断瓜是否成熟,很多是凭借经验。会根据色泽、根蒂、敲声等不同的角度去综合判断。但如果这些事情要用计算机去判断处理怎么办呢?这就是机器学习要研究和做的类似事情,机器学习是研究如何通过计算的手段,找出规律和经验,利用经验来改善和达到所需效果的过程。在计算机中,“经验”就是以“数据”形式存在的,对其进行计算分析来挖掘数据经验。形成的经验(模型)就可以用来预测和处理其他的类似数据和问题了,模型就是从数据分析中学习到的结果。以西瓜的选择为例,我们收集了一批西瓜的数据,从各个方面进行了标记(label),如(色泽=青绿;根蒂=蜷缩;敲声=浊响),(色泽=乌黑;根蒂=稍蜷;敲声=沉闷),(色泽=浅白;根蒂=硬挺;敲声=清脆),... ...。那么这些数据的集合就称为“数据集(data set)”,每条数据就是一个“示例(instance)/样本(sample)”。其中的色泽、根蒂、敲声叫做“属性”或“特征”。属性取值叫做属性值或特征值。属性所占有的空间叫做“属性空间”或“样本空间”/“输入空间”。如西瓜有色泽、根蒂、敲声三个属性,把它的属性看成三个坐标轴,那么每个西瓜都有其空间上的坐标位置,这个位置点对应一个坐标向量,所以一个示例或样本也叫做一个“特征向量”。
定义几个符号:D=数据样本(数据集)、x=标量、x=向量、X=变量集、χ=样本空间或状态空间
D={x1,x2,x3,...,xm}表示含有m个样本的数据集,每个样本由d个属性(特征)描述,即每个样本xi={xi1;xi2;xi3;...;xid}是d维样本空间χ的一个向量,xi∈χ。其中xij是xi在第j个属性上的取值,d称为样本xi的“维数”。
从数据中学习得到模型的过程称为“学习(learning)”/“训练(training)”,这个过程就是通过执行某个学习算法来完成的。训练过程中使用的数据称为“训练数据(training data)”,其中每个样本称为一个“训练样本(training sample)”训练样本组成的集合称为“训练集(training set)”。学习得到的模型对应了关于数据的某种潜在的规律,因此也成为“假设(hypothesis)”。这种潜在的规律自身也称为“真相”或“真实(ground-truth)”,学习的过程就是为了找出或逼近真相。当我们在预测天气好与坏的时候,把这些包含结果信息的数据,如“好天气”称为“标记(label)”;拥有了标记信息的示例/样本,则称为“样例(example)”
这里用(xi,yi)表示第i个样例,其中yi∈Y是样本xi的标记,Y是所有标记的集合,也成为“标记空间(label space)”或“输出空间”。
再看下分类,二分类,回归,多分类,聚类的简单介绍和例子。如果我们想要预测的是离散值,如“好天气”“坏天气”,“好瓜”“坏瓜”,那么此类学习任务就称为“分类(classification)”;如果想要预测的是连续值,例如西瓜成熟度0.95,0.37,那么此类学习任务称为“回归(regression)”,其中,只涉及两个类别的分类问题叫二分类任务,其中一个类叫做“正类”,另一个叫“反类”。涉及多个类别时称为“多分类”任务。一般情况,我们是通过训练集数据进行学习,找规律,形成一个从输入空间到输出空间的映射关系f:X->Y。对于二分类任务,我们把输出通常取值Y={-1,1}或{0,1};多分类任务,|Y|>2;对于回归任务,Y=R,R为实数集。
当我们得到模型后,用这个模型去进行预测的过程就叫做“测试(testing)”,被预测的样本成为“测试样本”。例如在学习得到f后,对测试样本x,可以得到预测表及y=f(x)。
对于聚类问题,还是以西瓜为例,将训练集中的西瓜分成若干组,每组称为一个“簇(cluster)”,这些自动形成的簇可能对应一些潜在的概念划分,如“浅色瓜”“深色瓜”,“本地瓜”“外地瓜”。聚类的样本信息一般都是没有标记的。
训练数据有标记称为“监督学习”,无标记称为“无监督学习”,分类和回归属于监督,聚类是无监督。
那么我们机器学习的目标就是使学习得到的模型能很好的应用于“新样本”,新数据。学习得到的模型适用于新样本的能力,称为“泛化”能力,具有强泛化能力的模型能很好的适用于整个样本空间。通常我们假设样本空间中全体样本服从一个未知“分布”(distribution)D,我们获得的每个样本都是独立的从这个分布上采样获得的,即“独立同分布”,一般来说,训练样本越多,我们得到的关于D(未知分布)的信息越多,就更有利于我们获取强泛化能力的模型。
再来看假设空间:归纳和演绎是科学推理的量大基本手段,前者是从特殊到一般的“泛化”过程,即从具体的事实归结出一般性规律,如机器学习的从一堆数据中找规律,再用这个规律推广;后者是从一般到特殊的“特化”过程,即从基础原理推演出具体情况。就像我们在学习数学时,基于一组公理和推理规则推导出与之相洽的定理,这就是演绎。“从样例中学习”是一个归纳的过程,也称为“归纳学习”。
机器学习过程可以看做是从有限的数据集(特殊)进行搜索的过程,搜索目标是找到与训练集“匹配”的假设。从特殊到一般的归纳过程。现实问题中,我们常面临很大的假设空间,但学习过程是基于有限样本训练集进行的,因此可能有多个假设与训练集一致,即存在着一个与训练集一致的“假设集合”,称作“版本空间”。例如西瓜问题的一个版本空间:
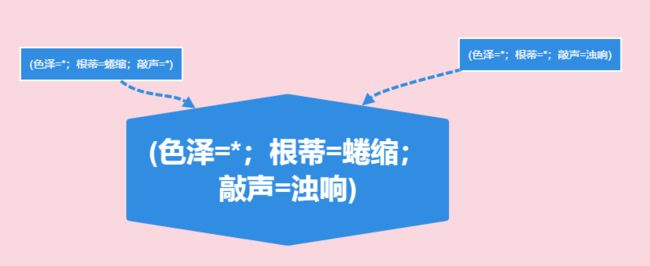
再看下归纳偏好:假设我们有三个假设模型,(色泽=*;根蒂=蜷缩;敲声=*)、(色泽=*;根蒂=*;敲声=浊响)和(色泽=*;根蒂=蜷缩;敲声=浊响),用来判断好瓜的标准。那么对于一个瓜来说,我们采用不同的假设模型可能会产生不同的结果,那么我们应该采用哪一个模型呢?机器学习算法在学习过程中对某种类型假设的偏好,称为“归纳偏好”或“偏好”。

如上图,存在A和B两条线可以连接这五个点,但是哪个线更好些呢?可能学习算法更偏好比较平滑的曲线A。归纳偏好可以看作是学习算法自身在一个可能很庞大的假设空间中对假设进行选择的启发式或“价值观”。那么有没有一般性的原则来引导算法确立“正确的”偏好呢?“奥克姆剃刀”是一种常用的、自然科学研究中最基本的原则,即“若有多个假设与观察一致,则选最简单的那个”。但是,奥卡姆剃刀并非唯一可行的原则。
其实经过各种数学推证,不管选择哪种假设模型偏好,总误差是一样的!即总误差与学习算法无关!无论算法A多聪明,算法B多笨拙,他们的期望性能是相同的!这就是“没有免费的午餐”定理,简称NFL定理。
那么很多人到这里可能会问了,既然所有学习算法的期望性能都跟随机胡猜差不多,那么还用它干嘛?但是要注意:NFL定理有一个重要的前提,所有“问题”出现的机会相同、或所有问题同等重要。但实际情形并不是这样,很多时候,我们只关注自己正在试图解决的问题,希望为它找到一个解决方案,至于这个解决方案在别的问题、甚至在相似的问题上是否为好方案,我们并不关心。所以NFL定理最重要的寓意,是让我们清楚地认识到,脱离具体问题,空泛的谈论“什么学习算法更好”毫无意义。学习算法自身的归纳偏好与问题是否匹配,往往会起到决定性的作用。
学习机器学习,人工智能了解历史也是有必要的。
机器学习是人工智能研究发展到一定阶段的必然产物。广义的归纳学习(从样例中学习)涵盖了监督学习、无监督学习,是被研究最多、应用最广的。
二十世纪八十年代,“从样例中学习”的一大主流是符号主义学习,其代表包括决策树(decision tree)和基于逻辑的学习。
二十世纪九十年代中期之前,“从样例中学习”的另一主流技术是基于神经网络的连接主义学习。1986年,D.E.Rumelhart等人重新发明了著名的BP算法,产生了深远影响。
二十世纪九十年代中期,“统计学习(statistical learning)”闪亮登场并迅速占据主流舞台,代表性技术是支持向量机(Support Vector Machine)以及更一般的“核方法(kernel methods)”。
二十一世纪初,连接主义学习又卷土重来,掀起了以“深度学习”为名的热潮。所谓深度学习,狭义的说就是“很多层”的神经网络。在很多测试和竞赛上,特别是涉及到语音、图像等复杂对象的应用中,深度学习技术取得了优越性能。
那么,为什么它这个时候才热起来?有两个基本原因:数据大了、计算能力强了。深度学习技术涉及的模型复杂度非常高,以至于要下功夫“调参”,把参数调节好,性能往往就好。因此深度学习虽然缺乏严格的理论基础,但它显著降低了机器学习应用者的门槛,为机器学习技术走向工程实践带来了便利。深度学习模型拥有大量的参数,若数据样本少,则很容易“过拟合”。机器学习现在已经发展成为一个相当大的学科领域。
今天,在计算机科学的很多分支学科领域中,无论是多媒体、图形学,还是网络通信、软件工程,乃至体系结构、芯片设计,都能找到机器学习技术的身影,尤其是在计算机视觉、自然语言处理等“计算机应用技术”领域,机器学习已经成为最重要的技术进步源泉之一。“数据分析”恰是机器学习技术的舞台。
科学研究的基本手段已经从传统的“理论+实验”变成现在的“理论+实验+计算”,也出现了“数据科学”的提法。“计算”的目的往往是数据分析,而数据科学的核心也恰恰是通过分析数据来获得价值。
2006年,卡耐基梅隆大学宣告成立世界上第一个“机器学习系”。说到数据分析,很多人会想到“数据挖掘(data mining)”,而机器学习和统计学的研究为数据挖掘提供数据分析技术。美国《新闻周刊》曾对谷歌搜索有一句话评论:“它使任何人离任何问题的答案间的距离变得只有点击一下鼠标这么远”。除了深度学习,还可以了解下“迁移学习”、“类比学习”、“集成学习”等。
机器学习领域最重要的国际会议是国际机器学习会议(ICML)、国际神经信息处理系统会议(NIPS)和国际学习理论会议(COLT),重要的区域性会议主要有欧洲机器学习会议(ECML)和亚洲机器学习会议(ACML),最重要的国际学术期刊是Journal of Machine Learning Research和Machine Learing。人工智能领域的重要会议如IJCAI、AAAI以及重要期刊如Artificial Intelligence、Journal of Artificial Intelligence Research等。国内机器学习领域最主要的活动是两年一次的中国机器学习大会(CCML)以及每年句型的“机器学习以及应用”研讨会(MLA),很多学术刊物都经常刊登有关机器学习的论文。
参考文献:
[1]周志华.机器学习[M].北京:清华大学出版社,2016.
[2]陆汝钤.人工智能(下册).北京:科学出版社,1996.
[3]Alpaydin,E.Introduction to Machine Learning.MA:MIT Press,Cambridge,2004.