学习笔记——Kaggle_Digit Recognizer (朴素贝叶斯 Python实现)
本文是个人学习笔记,该篇主要学习朴素贝叶斯算法概念,并应用sklearn.naive_bayes算法包解决Kaggle入门级Digit Recognizer。
- 贝叶斯定理
- 朴素贝叶斯
- Python 代码
贝叶斯定理
对于贝叶斯定理的了解和学习大部分都是从概率论开始的,但实际贝叶斯定理应用范围极其广泛,在我们学习贝叶斯定理在算法中的应用前,在复习下其基本概念。
贝叶斯公式:
简单转换后,即可得到:
应用到分类算法中时:这里可以认为A为类别,B为特征
P(A|B)是已知B发生后A的条件概率,也称作A的后验概率(根据样本分布和未知参数的先验概率分布求得的条件概率分布)。
P(A)是A的先验概率或边缘概率(基于主观判断而非样本分布的概率分布),称作”先验”是因为它不考虑B因素。
P(B|A)是已知A发生后B的条件概率,也称作B的后验概率,这里称作似然度。
P(B)是B的先验概率或边缘概率,这里称作标准化常量。
P(B|A)/P(B)称作标准似然度。
朴素贝叶斯
当然,实际分类问题往往都是多类别多特征的判断,则贝叶斯公式将转化为如下: 类别 Ai ,特征 B1,...Bn
从公式上不难发现存在许多的似然值,相互关系复杂计算量大。为了解决该问题且简化计算,就衍生了朴素贝叶斯假设:特征之间相互独立。虽然该假设看上去与实际符合度低,但经过大量实践证明其应用效果其实相当出色。
基于朴素贝叶斯假设,公式将可以简化为:
朴素贝叶斯的分类原理就是根据新样本的特征计算分别其在各类的别概率大小,选取概率最大的类别为其最终类别。因为每个类别计算的分母都是相同的,所以实际可以省略分母的概率计算。
朴素贝叶斯的流程可以通过下图表示:
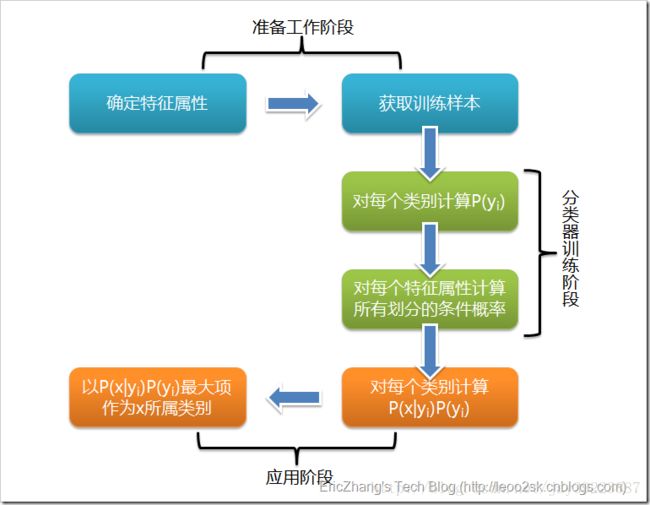
总体上,朴素贝叶斯分类实现经历三个阶段:
第一阶段——准备工作阶段,根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对部分待分类项进行分类,形成训练样本集。这一阶段的输入是待分类数据,输出是特征属性和训练样本。分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。
其中需要注意的是,计算条件概率是非常重要的阶段,当特征属性为离散值时,只要统计训练样本中各个划分在每个类别中出现的频率即可进行推算, 而当特征属性为连续值时,通常假定其值服从高斯分布。
另外,为了避免条件概率为0的情况(某个类别下某个特征项划分没有出现),在这里引入了Laplace校准,即对没类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的情况。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。
Python 代码
Python的sklearn中有已集成的朴素贝叶斯算法包naive_bayes,根据特征值的分布可以选择对应的分类计算方法(MultinomialNB,GaussianNB等)
import pandas as pd
import numpy as np
import time
from sklearn import naive_bayes
def data_load():
# 利用pandas读取csv文件内容
train_ttl=pd.read_csv('D:\Program files\JetBrains\digit recognizer\Raw data\\train.csv')
train_label=pd.DataFrame(train_ttl['label'])
train_data=pd.DataFrame(train_ttl.ix[:,1:])
test_data=pd.read_csv('D:\Program files\JetBrains\digit recognizer\Raw data\\test.csv')
# dataframe归整化
test_data[test_data!=0]=1
# train_data[train_data!=0]=1
m,n=train_data.shape#这里似乎因为dataframe太大,用bool判断更改时总会异常跳出,所以选择循环更改
for i in range(m):
for j in range(n):
if train_data.ix[i,j]!=0:
train_data.ix[i,j]=1
return train_data,train_label,test_data
#利用Python Sklearn包,进行test样本集分类判别
def bayes_classify(traindata,trainlabel,testdata):
bayes_clf = naive_bayes.MultinomialNB()#设置函数和参数
bayes_clf.fit(traindata,trainlabel.values.ravel())#训练Train样本
bayes_result=bayes_clf.predict(testdata)#预测Test样本
return bayes_result
if __name__=='__main__':
start = time.clock()
traindata,trainlabel,testdata=data_load()#加载raw data
m,n=testdata.shape
result_labels=bayes_classify(traindata,trainlabel,testdata)
#将结果转化成Dataframe结构
result={}
ImageId=np.arange(m)+1
result['Label']=result_labels
result_frame=pd.DataFrame(result,index=ImageId)
#导出结果
result_frame.to_csv('D:\Program files\JetBrains\digit recognizer\Raw data\\result_bayes.csv')
end = time.clock()
print('总耗时:', (end - start)/3600.0)#接近1.6小时,效果不理想只有0.81