高并发下生成订单号的策略
臭味相投的朋友们,我在这里:
猿in小站:http://www.yuanin.net
csdn博客:https://blog.csdn.net/jiabeis
简书:https://www.jianshu.com/u/4cb7d664ec4b
微信免费订阅号“猿in”

互联网快速发展的今天,分布式应用系统已经见怪不怪,在分布式系统中,我们需要各种各样的ID,既然是ID那么必然是要保证全局唯一,除此之外,不同当业务还需要不同的特性,比如像并发巨大的业务要求ID生成效率高,吞吐大;比如某些银行类业务,需要按每日日期制定交易流水号;又比如我们希望用户的ID是随机的,无序的,纯数字的,且位数长度是小于10位的。等等,不同的业务场景需要的ID特性各不一样,于是,衍生了各种ID生成器。本文讲的订单号就是其中一种业务id,下面结合订单业务需求,介绍订单号的生成策略。
业务需求:
- 订单号不能重复
- 订单号没有规则,即编码规则不能加入任何和公司运营相关的数据,外部人员无法通过订单ID猜测到订单量。不能被遍历。
- 订单号长度固定,且不能太长
- 易读,易沟通,不要出现数字字母换乱现象
- 生成耗时
关于订单号的生成,一些比较简单的方案:
1、数据库自增长ID
- 优势:无需编码
- 缺陷:
- 大表不能做水平分表,否则插入删除时容易出现问题
- 高并发下插入数据需要加入事务机制
- 在业务操作父、子表(关联表)插入时,先要插入父表,再插入子表
2、时间戳+随机数
- 优势:编码简单
- 缺陷:随机数存在重复问题,即使在相同的时间戳下。每次插入数据库前需要校验下是否已经存在相同的数值。
3、时间戳+会员ID
- 优势:同一时间,一个用户不会存在两张订单
- 缺陷:会员ID也会透露运营数据,鸡生蛋,蛋生鸡的问题
- 例如:S+yyMMddHHmmss+Math.abs(memberId.hashCode());[说明memberId为uuid的,String的hashCode唯一,而hashcode可能为负数]
4、GUID/UUID
- 优势:简单
- 劣势:用户不友好,索引关联效率较低。
UUID全称:Universally Unique Identifier,即通用唯一识别码。
UUID是由一组32位数的16进制数字所构成,所以理论上UUID的总数为16^32=2^128,约等于3.4*10^38。也就是书偶偶每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。
UUID的标准形式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的32个字符,如:550e8400-e19b-41d4-a716-446655440000。
UUID的作用
UUID是让分布式系统中的所有元素都能有唯一的辨识信息,而不要要通过中央控制端来做辨识信息的指定。如此一来,每个人都可以创建不与其他人冲突的UUID。在这样的情况下,就不需考虑数据库创建时的名称重复问题。目前最广泛应用的UUID,是微软公司的全局唯一标识符(GUID),而其他重要的应用,则有Linux ext2/ext3文件系统、LULS加密分区、GNOME、KDE、Mac OS X等等。
UUID的组成
UUID是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。通常平台会提供生成的API。按照开放软件基金会(OSF)制定的标准计算,用到了以太网卡地址、纳秒级时间、芯片ID码和许多可能的数字。
UUID由以下几部分的组合
当前日期和时间,UUID的第一个部分与时间有关,如果你在生成一个UUID之后,过几秒后又生成了一个UUID,则第一个部分不同,其余相同。
时钟序列。
全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得。
UUID的唯一缺陷在于生成的结果穿会比较长。关于UUID这个标准使用最普遍的是微软的GUID(Globals Ujique Identifiers)。
5、twitter的SnowFlake [参考:https://blog.csdn.net/li396864285/article/details/54668031]
Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统中不同机器产生的id必须不同.Snowflake算法核心把时间戳,工作机器id,序列号(毫秒级时间41位+机器ID 10位+毫秒内序列12位)组合在一起。
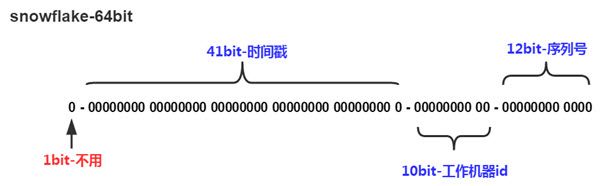
在上面的字符串中,第一位为未使用(实际上也可作为long的符号位),接下来的41位为毫秒级时间,然后5位datacenter标识位,5位机器ID(并不算标识符,实际是为线程标识),然后12位该毫秒内的当前毫秒内的计数,加起来刚好64位,为一个Long型。
除了最高位bit标记为不可用以外,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。下文会具体分析。
这里时间戳的细度是毫秒级,具体代码如下,建议使用64位linux系统机器,因为有vdso,gettimeofday()在用户态就可以完成操作,减少了进入内核态的损耗。
1.snowflake简介
snowflake算法是一款本地生成的(ID生成过程不依赖任何中间件,无网络通信),保证ID全局唯一,并且ID总体有序递增,性能每秒生成300w+。
2.snowflake算法原理
snowflake生产的ID是一个18位的long型数字,二进制结构表示如下(每部分用-分开):
0 - 00000000 00000000 00000000 00000000 00000000 0 - 00000 - 00000 - 00000000 0000
第一位未使用,接下来的41位为毫秒级时间(41位的长度可以使用69年,从1970-01-01 08:00:00),然后是5位datacenterId(最大支持2^5=32个,二进制表示从00000-11111,也即是十进制0-31),和5位workerId(最大支持2^5=32个,原理同datacenterId),所以datacenterId*workerId最多支持部署1024个节点,最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生2^12=4096个ID序号).
所有位数加起来共64位,恰好是一个Long型(转换为字符串长度为18).
单台机器实例,通过时间戳保证前41位是唯一的,分布式系统多台机器实例下,通过对每个机器实例分配不同的datacenterId和workerId避免中间的10位碰撞。最后12位每毫秒从0递增生产ID,再提一次:每毫秒最多生成4096个ID,每秒可达4096000个。理论上,只要CPU计算能力足够,单机每秒可生产400多万个,实测300w+,效率之高由此可见。
(该节改编自:http://www.cnblogs.com/relucent/p/4955340.html)
3.snowflake算法源码(java版)
-
@ToString
-
@Slf4j
-
public class SnowflakeIdFactory {
-
private final long twepoch = 1288834974657L;
-
private final long workerIdBits = 5L;
-
private final long datacenterIdBits = 5L;
-
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
-
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
-
private final long sequenceBits = 12L;
-
private final long workerIdShift = sequenceBits;
-
private final long datacenterIdShift = sequenceBits + workerIdBits;
-
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
-
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
-
private long workerId;
-
private long datacenterId;
-
private long sequence = 0L;
-
private long lastTimestamp = -1L;
-
public SnowflakeIdFactory(long workerId, long datacenterId) {
-
if (workerId > maxWorkerId || workerId < 0) {
-
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
-
}
-
if (datacenterId > maxDatacenterId || datacenterId < 0) {
-
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
-
}
-
this.workerId = workerId;
-
this.datacenterId = datacenterId;
-
}
-
public synchronized long nextId() {
-
long timestamp = timeGen();
-
if (timestamp < lastTimestamp) {
-
//服务器时钟被调整了,ID生成器停止服务.
-
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
-
}
-
if (lastTimestamp == timestamp) {
-
sequence = (sequence + 1) & sequenceMask;
-
if (sequence == 0) {
-
timestamp = tilNextMillis(lastTimestamp);
-
}
-
} else {
-
sequence = 0L;
-
}
-
lastTimestamp = timestamp;
-
return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence;
-
}
-
protected long tilNextMillis(long lastTimestamp) {
-
long timestamp = timeGen();
-
while (timestamp <= lastTimestamp) {
-
timestamp = timeGen();
-
}
-
return timestamp;
-
}
-
protected long timeGen() {
-
return System.currentTimeMillis();
-
}
-
public static void testProductIdByMoreThread(int dataCenterId, int workerId, int n) throws InterruptedException {
-
List
tlist = new ArrayList<>(); -
Set
setAll = new HashSet<>(); -
CountDownLatch cdLatch = new CountDownLatch(10);
-
long start = System.currentTimeMillis();
-
int threadNo = dataCenterId;
-
Map
-
for(int i=0;i<10;i++){
-
//用线程名称做map key.
-
idFactories.put("snowflake"+i,new SnowflakeIdFactory(workerId, threadNo++));
-
}
-
for(int i=0;i<10;i++){
-
Thread temp =new Thread(new Runnable() {
-
@Override
-
public void run() {
-
Set
setId = new HashSet<>(); -
SnowflakeIdFactory idWorker = idFactories.get(Thread.currentThread().getName());
-
for(int j=0;j
-
setId.add(idWorker.nextId());
-
}
-
synchronized (setAll){
-
setAll.addAll(setId);
-
log.info("{}生产了{}个id,并成功加入到setAll中.",Thread.currentThread().getName(),n);
-
}
-
cdLatch.countDown();
-
}
-
},"snowflake"+i);
-
tlist.add(temp);
-
}
-
for(int j=0;j<10;j++){
-
tlist.get(j).start();
-
}
-
cdLatch.await();
-
long end1 = System.currentTimeMillis() - start;
-
log.info("共耗时:{}毫秒,预期应该生产{}个id, 实际合并总计生成ID个数:{}",end1,10*n,setAll.size());
-
}
-
public static void testProductId(int dataCenterId, int workerId, int n){
-
SnowflakeIdFactory idWorker = new SnowflakeIdFactory(workerId, dataCenterId);
-
SnowflakeIdFactory idWorker2 = new SnowflakeIdFactory(workerId+1, dataCenterId);
-
Set
setOne = new HashSet<>(); -
Set
setTow = new HashSet<>(); -
long start = System.currentTimeMillis();
-
for (int i = 0; i < n; i++) {
-
setOne.add(idWorker.nextId());//加入set
-
}
-
long end1 = System.currentTimeMillis() - start;
-
log.info("第一批ID预计生成{}个,实际生成{}个<<<<*>>>>共耗时:{}",n,setOne.size(),end1);
-
for (int i = 0; i < n; i++) {
-
setTow.add(idWorker2.nextId());//加入set
-
}
-
long end2 = System.currentTimeMillis() - start;
-
log.info("第二批ID预计生成{}个,实际生成{}个<<<<*>>>>共耗时:{}",n,setTow.size(),end2);
-
setOne.addAll(setTow);
-
log.info("合并总计生成ID个数:{}",setOne.size());
-
}
-
public static void testPerSecondProductIdNums(){
-
SnowflakeIdFactory idWorker = new SnowflakeIdFactory(1, 2);
-
long start = System.currentTimeMillis();
-
int count = 0;
-
for (int i = 0; System.currentTimeMillis()-start<1000; i++,count=i) {
-
/** 测试方法一: 此用法纯粹的生产ID,每秒生产ID个数为300w+ */
-
idWorker.nextId();
-
/** 测试方法二: 在log中打印,同时获取ID,此用法生产ID的能力受限于log.error()的吞吐能力.
-
* 每秒徘徊在10万左右. */
-
//log.error("{}",idWorker.nextId());
-
}
-
long end = System.currentTimeMillis()-start;
-
System.out.println(end);
-
System.out.println(count);
-
}
-
public static void main(String[] args) {
-
/** case1: 测试每秒生产id个数?
-
* 结论: 每秒生产id个数300w+ */
-
//testPerSecondProductIdNums();
-
/** case2: 单线程-测试多个生产者同时生产N个id,验证id是否有重复?
-
* 结论: 验证通过,没有重复. */
-
//testProductId(1,2,10000);//验证通过!
-
//testProductId(1,2,20000);//验证通过!
-
/** case3: 多线程-测试多个生产者同时生产N个id, 全部id在全局范围内是否会重复?
-
* 结论: 验证通过,没有重复. */
-
try {
-
testProductIdByMoreThread(1,2,100000);//单机测试此场景,性能损失至少折半!
-
} catch (InterruptedException e) {
-
e.printStackTrace();
-
}
-
}
-
}
测试用例:
/** case1: 测试每秒生产id个数?
* 结论: 每秒生产id个数300w+ */
//testPerSecondProductIdNums();
/** case2: 单线程-测试多个生产者同时生产N个id,验证id是否有重复?
* 结论: 验证通过,没有重复. */
//testProductId(1,2,10000);//验证通过!
//testProductId(1,2,20000);//验证通过!
/** case3: 多线程-测试多个生产者同时生产N个id, 全部id在全局范围内是否会重复?
* 结论: 验证通过,没有重复. */
try {
testProductIdByMoreThread(1,2,100000);//单机测试此场景,性能损失至少折半!
} catch (InterruptedException e) {
e.printStackTrace();
}