hadoop生态圈(一):hadoop集群的搭建
目录
1 hadoop概述
1.1 hadoop是什么
1.2 hadoop的组成
1.2.1 hdfs架构概述
1.2.2 YARN概述
1.2.3 MapReduce架构概述
1.3 大数据生态体系
1.4 推荐系统架构图
2 Hadoop集群搭建
2.1 虚拟机环境准备
2.2 安装jdk和hadoop
2.3 集群配置
3 集群启动
3.1 集群单点启动
3.2 SSH无密登陆设置
3.3 集群一键启动/停止方式
4 测试
4.1启动集群
4.2 集群基本测试
4.3 集群时间同步
4.3.1 时间服务器配置(必须是root用户)
4.3.2 其他机器配置(root用户)
1 hadoop概述
1.1 hadoop是什么
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构
- 集群:多个机器共同完成一件事
- 分布式:多个机器共同完成一件事,然后不同机器作用不同,各司其职
- 集群不一定是分布式,分布式一定是集群
- 主要解决,海量数据的存储和海量数据的分析计算问题。
- 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
1.2 hadoop的组成
- Hadoop HDFS:(hadoop distribute file system )一个高可靠、高吞吐量的分布式文件系统。
- Hadoop MapReduce:一个分布式的离线并行计算框架。
- Hadoop YARN:作业调度与集群资源管理的框架。
- Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)。
1.2.1 hdfs架构概述

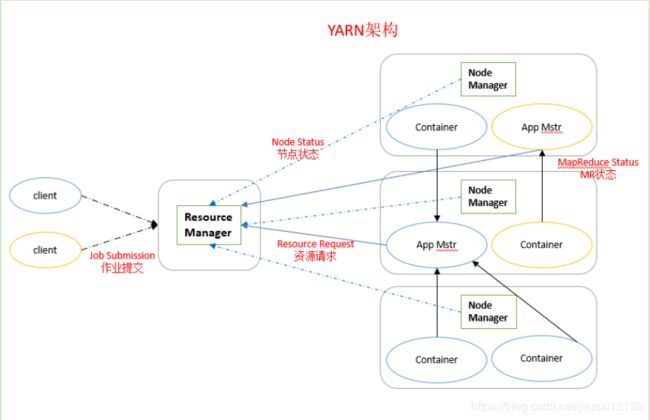
1.2.2 YARN概述
- ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
- NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
- ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
- Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
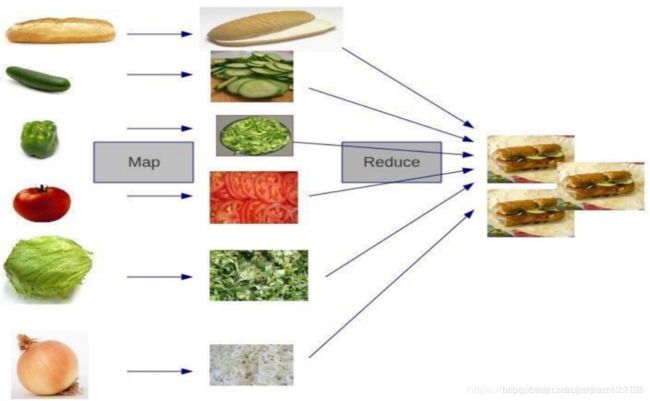
1.2.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map(映射)和Reduce(归约)
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
1.3 大数据生态体系
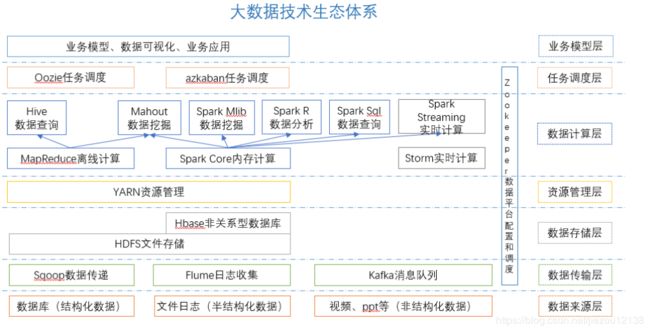
图中涉及的技术名词解释如下:
- Sqoop:sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
- Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
- Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息
- 支持通过Kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
- Storm:Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据库。这是管理队列及工作者集群的另一种方式。 Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
- Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
- Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。Oozie协调作业就是通过时间(频率)和有效数据触发当前的Oozie工作流程。
- Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
- Hive:hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
- Mahout:
- Apache Mahout是个可扩展的机器学习和数据挖掘库,当前Mahout支持主要的4个用例:
- 推荐挖掘:搜集用户动作并以此给用户推荐可能喜欢的事物。
- 聚集:收集文件并进行相关文件分组。
- 分类:从现有的分类文档中学习,寻找文档中的相似特征,并为无标签的文档进行正确的归类。
- 频繁项集挖掘:将一组项分组,并识别哪些个别项会经常一起出现。
- ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
1.4 推荐系统架构图
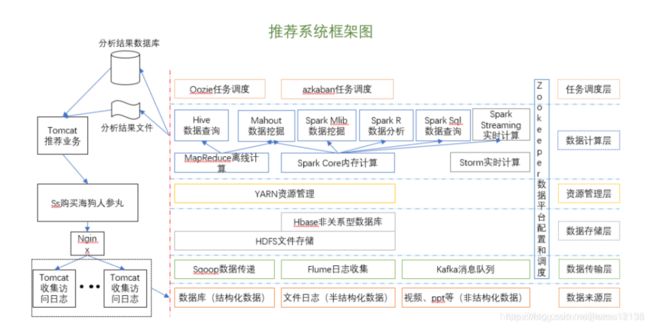
2 Hadoop集群搭建
安装所需要的软件链接:请点这里;提取码:i431
也可以去官网自行下载
2.1 虚拟机环境准备
- 三台虚拟机
- 修改主机名 /etc/sysconfig/network sync然后重启
主机名分别为:hadoop101;hadoop102;hadoop103;
- 修改克隆虚拟机的静态ip,分别为:
IP分别为:192.168.1.101;192.168.1.102;192.168.1.103
- 配置主机名和IP的映射关系(便于使用主机名访问虚拟机)
[root@ hadoop101桌面]# vim /etc/hosts
添加如下内容
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
- 关闭防火墙 service iptables stop;chkconfig iptables off
- 在各个机器上使用root用户在/opt目录下创建module、software文件夹
2.2 安装jdk和hadoop
安装测略:现在一台节点上配置,然后通过命令发送到另外两台节点上
1. 卸载现有的jdk
查询是否安装jdk,如果版本低于1.7,卸载该jdk
[root@hadoop101 opt]$ rpm -qa | grep java
[root@hadoop101 opt]$ rpm -e 软件包
2. 将jdk和hadoop上传到/opt/software目录下
3.在Linux系统目录下查看是否上传成功
[root@hadoop101 opt]$ cd software/
[root@hadoop101 software]$ ls
hadoop-2.7.2.tar.gz jdk-8u144-linux-x64.tar.gz
4. 解压jdk和hadoop到/opt/module目录
[root@hadoop101 software]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
[root@hadoop101 software]# tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
5.配置jdk和hadoop的环境变量
打开/etc/profile文件,在最后添加下列内容
[root@hadoop101 software]$ vi /etc/profile
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
保存退出 :wq
让配置文件重新生效
[root@ hadoop101 software]$ source /etc/profile
6.测试是否安装成功
[root@hadoop101 ~]# java -version
java version "1.8.0_144"
[root @hadoop101 ~]$ hadoop version
Hadoop 2.7.2
7.重启(如果命令不成功再重启)
2.3 集群配置
1. 集群部署规划
|
|
hadoop101 |
hadoop102 |
hadoop103 |
| HDFS
|
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
2. 配置集群
1. 配置hadoop所使用的Java的环境变量:hadoop-env.sh
[root@hadoop101 hadoop]$ vim hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
2. 核心配置文件:core-site.xml(hdfs的核心配置文件)
[root@hadoop101 hadoop]$ vim core-site.xml
fs.defaultFS
hdfs://hadoop101:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
3. hdfs配置文件:hdfs-site.xml
[root@hadoop101 hadoop]$ vim hdfs-site.xml
dfs.replication
3
辅助namenode工作
dfs.namenode.secondary.http-address
hadoop10 3:50090
4. yarn配置文件
yarn-env.sh
[root@hadoop101 hadoop]$ vim yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
yarn-site.xml
[root@hadoop101 hadoop]$ vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop102
5. mapreduce配置文件
mapred-env.sh
[root@hadoop101 hadoop]$ vim mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
mapred-site.xml
[root@hadoop101 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[root@hadoop101 hadoop]$ vim mapred-site.xml
mapreduce.framework.name
yarn
3. 配置集群中从节点的信息
/opt/module/hadoop-2.7.2/etc/hadoop/slaves
[root@hadoop101 hadoop]$ vim slaves
hadoop101
hadoop102
hadoop103
4. 分发文件
scp:(secure copy)安全拷贝
①定义:scp可以实现服务器到服务器之间的数据拷贝。(from server1 to server2)
安装scp命令,这个需要每个节点都安装
yum install -y openssh-server openssh-clients
②使用:将hadoop101中/opt/module/目录下的所有文件拷贝到hadoop102、hadoop103
[root@hadoop101 /]$ scp -r /opt/module/* hadoop102:/opt/module
[root@hadoop101 /]$ scp -r /opt/module/* hadoop103:/opt/module
5. 查看文件分发情况(验证一个即可)
[root@hadoop102 hadoop]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
3 集群启动
- 单点启动(不建议使用该方式启动集群,假如某个节点挂掉了,可以使用这个单独启动)
- 一键启动(建议使用,各个服务组件逐一启动,集群中某个进程挂掉使用这种方式重启)
3.1 集群单点启动
1. 如果集群是第一次启动,需要格式化NameNode(格式化只进行一次)
[root@hadoop101 hadoop-2.7.2]$ hadoop namenode -format
2. 在hadoop101上启动NameNode
[root@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
[root@hadoop101 hadoop-2.7.2]$ jps
3461 NameNode
3. 在hadoop101、hadoop102、hadoop103上分别启动DataNode
[root@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[root@hadoop101 hadoop-2.7.2]$ jps
3461 NameNode
3608 Jps
3561 DataNode
[root@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[root@hadoop102 hadoop-2.7.2]$ jps
3190 DataNode
3279 Jps
[root@hadoop103 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[root@hadoop103 hadoop-2.7.2]$ jps
3237 Jps
3163 DataNode
3.2 SSH无密登陆设置
(一键启动的必备条件)
1. 配置ssh
1. 基本语法: ssh 另一台主机的ip地址
如果提示command not found,需要安装ssh服务
yum install -y openssh-server openssh-clients
2. ssh连接时出现Host key verification failed 直接输入yes即可
[root@hadoop101 opt] $ ssh hadoop102
The authenticity of host 'hadoop102(192.168.1.102)' can't be established.
RSA key fingerprint is cf:1e:de:d7:d0:4c:2d:98:60:b4:fd:ae:b1:2d:ad:06.
Are you sure you want to continue connecting (yes/no)?
Host key verification failed.
2. 无密钥配置
1. 免密登陆原理
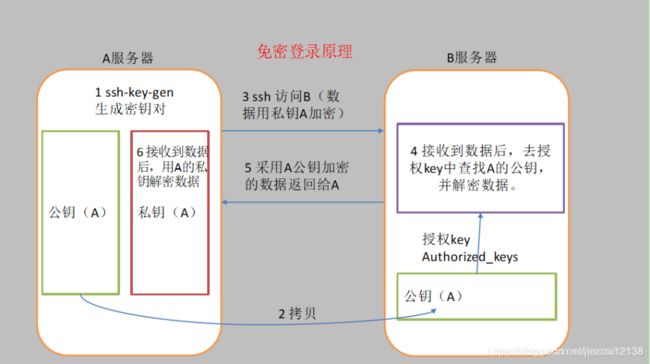
- A服务器通过ssh-key-gen生成密钥对
- 将公钥(A)拷贝到其他的服务器上
- 然后A服务器使用私钥(A)加密数据后发送到其他的服务器
- 其他的服务器接受到数据后,在本机授权key中查找A的公钥,并解密数据
- 数据处理完成后,使用公钥(A)将数据加密后返回给A服务器
2. 生成密钥对:
[root@hadoop101 .ssh]# pwd //.ssh是一个隐藏的文件夹
/root/.ssh[root@hadoop101 .ssh]$ ssh-keygen -t rsa //然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
3. 将公钥拷贝到要免密登录的目标机器上
[root@hadoop101 .ssh]$ ssh-copy-id hadoop101
[root@hadoop101 .ssh]$ ssh-copy-id hadoop102
[root@hadoop101 .ssh]$ ssh-copy-id hadoop103
4.测试
[root@hadoop101 .ssh]# ssh hadoop102
Last login: Mon Apr 8 17:00:50 2019 from 192.168.1.1
[root@hadoop102 ~]# exit
logout
Connection to hadoop102 closed.
3. .ssh文件夹下(~/.ssh)的文件功能解释
- known_hosts :记录ssh访问过计算机的公钥(public key)
- id_rsa :生成的私钥
- id_rsa.pub :生成的公钥
- authorized_keys :存放授权过得无密登录服务器公钥
3.3 集群一键启动/停止方式
1. 各个服务组件逐一启动/停止
分别启动/停止hdfs组件
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
启动/停止yarn
yarn-daemon.sh start|stop resourcemanager|nodemanager
2. 各个模块分开启动/停止(配置SSH是前提)常用
整体启动/停止hdfs(namenode节点启动,也就是hadoop101)
[root@hadoop101sbin]# ./start-dfs.sh
[root@hadoop101 sbin]# ./start-dfs.sh
整体启动/停止yarn(在resourceManager节点启动,也就是hadoop102)
[root@hadoop102 sbin]# ./start-yarn.sh
[root@hadoop102 sbin]# ./stop-yarn.sh
4 测试
4.1启动集群
1. 如果集群是第一次启动,需要格式化namenode,如果单点启动的时候已将格式化,就不需要格式化了!!
[root@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
2. 启动HDFS
[root@hadoop101 hadoop-2.7.2]$ sbin/start-dfs.sh
[root@hadoop101 hadoop-2.7.2]$ jps
4166 NameNode
4482 Jps
4263 DataNode
[root@hadoop101 hadoop-2.7.2]$ jps
3218 DataNode
3288 Jps
[root@hadoop101 hadoop-2.7.2]$ jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
启动之后查看hdfs的WEBUI界面:http://192.168.1.101:50070/
3. 启动yarn
[root@hadoop102 hadoop-2.7.2]$ sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。如果不在一台机器上,则ResourceManger所在机器也需要配置到其他机器的ssh免密登录
通过jps命令查看进程:
[root@hadoop101 .ssh]# jps
3584 NameNode
3718 DataNode
4872 NodeManager[root@hadoop102 sbin]# jps
3441 DataNode
5162 NodeManager
5053 ResourceManager[root@hadoop103 ~]# jps
3542 SecondaryNameNode
5095 NodeManager
3434 DataNode
Yarn的web页面查看地址:http://hadoop102:8088/
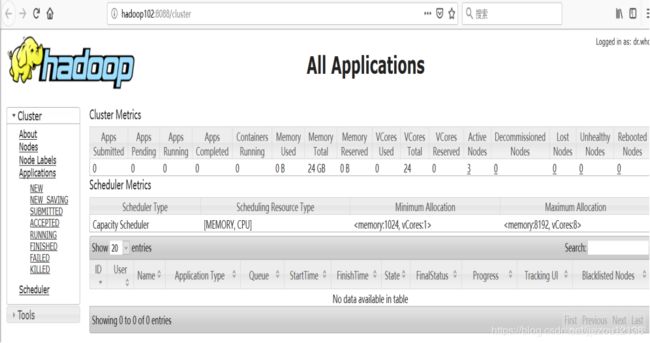
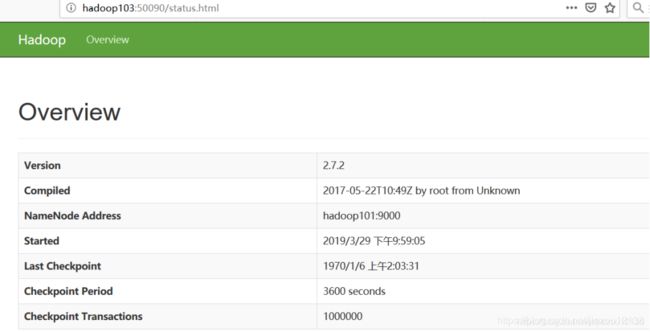
4. 查看SecondaryNameNode的WEBUI界面
4.2 集群基本测试
1. 上传文件到集群
上传小文件
[root@hadoop101 hadoop-2.7.2]# hadoop fs -mkdir /upload //在hdfs上创建一个文件夹
[root@hadoop101 hadoop-2.7.2]# hadoop fs -put bigdata.txt /upload/
上传大文件
[root@hadoop101 software]# hadoop fs -put hadoop-2.7.2.tar.gz /upload
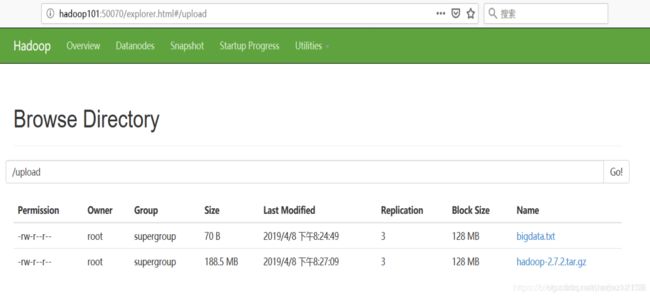
2. 上传文件后查看文件存放的位置
查看HDFS文件存储位置
[root@hadoop101 subdir0]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-327200681-192.168.1.101-1551800072963/current/finalized/subdir0/subdir0
查看HDFS在磁盘存储的文件内容
[root@hadoop101 subdir0]$ cat blk_1073741825
hadoop yarn
hadoop mapreduce
拼接
-rw-rw-r--. 1 hadoop hadoop 134217728 4月 8 20:01 blk_1073741836
-rw-rw-r--. 1 hadoop hadoop 1048583 4月 8 20:01 blk_1073741836_1012.meta
-rw-rw-r--. 1 hadoop hadoop 63439959 4月 8 20:01 blk_1073741837
-rw-rw-r--. 1 hadoop hadoop 495635 4月 8 20:01 blk_1073741837_1013.meta
[root@hadoop101 subdir0]$ cat blk_1073741836>>tmp.file
[root@hadoop101 subdir0]$ cat blk_1073741837>>tmp.file
[root@hadoop101 subdir0]$ tar -zxvf tmp.file
下载
[root@hadoop101 hadoop-2.7.2]$ hadoop fs -get /upload/hadoop-2.7.2.tar.gz ./
4.3 集群时间同步
时间同步的方式:在集群中找一台机器,作为时间服务器,集群中其他机器与这台机器定时的同步时间,比如,每隔十分钟,同步一次时间。
4.3.1 时间服务器配置(必须是root用户)
1. 检查ntp是否安装,没有安装则使用 yum install ntp -y 进行安装
[root@hadoop101 桌面]# rpm -qa|grep ntp
ntp-4.2.6p5-10.el6.centos.x86_64
fontpackages-filesystem-1.41-1.1.el6.noarch
ntpdate-4.2.6p5-10.el6.centos.x86_64
2. 修改net配置文件
[root@hadoop101 桌面]# vim /etc/ntp.conf
修改内容如下
a)修改1(授权192.168.1.0网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他的网络时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
3. 修改/etc/sysconfig/ntpd 文件
[root@hadoop101 桌面]# vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
4. 重新启动ntpd
[root@hadoop101 桌面]# service ntpd status
ntpd 已停
[root@hadoop101 桌面]# service ntpd start
正在启动 ntpd: [确定]
5. 执行:
[root@hadoop101 桌面]# chkconfig ntpd on
4.3.2 其他机器配置(root用户)
1. 在其他机器配置10分钟与时间服务器同步一次
[root@hadoop102 hadoop-2.7.2]# crontab -e
编写脚本
*/10 * * * * /usr/sbin/ntpdate hadoop101
2. 修改任意机器时间
[root@hadoop102 root]# date -s "2017-9-11 11:11:11"
3. 十分钟后查看机器是否与时间服务器同步
[root@hadoop102 root]# date