Python3 爬虫 相关库安装
安装包百度云分享syfe
-
- 1. 请求库
- reuqests
- selenium
- ChromeDriver
- GeckoDriver
- PhantomJS
- aiohttp
- 2.解析库
- tesserocr
- lxml
- Beautiful Soup
- pyquery
- 3.数据库
- mysql
- mongoDB
- Redis
- 4.存储库
- Pymysql
- PyMongo
- Redis-py
- RedisDump
- 5.Web库
- Flask
- Tornado
- 6.App爬取相关库
- Charles
- mitmproxy
- Appium
- 7.爬虫框架
- pyspider
- Scrapy
- 9.部署安装库
- Docker
- Scrapyd
- Scrapyd-Client
- Scrapyd API
- Scrapyrt
- Gerapy
- 1. 请求库
1. 请求库
reuqests
pip3 install requests
selenium
安装2.48.0版本可支持PantomJS pip install selenium==2.48.0
最新版本已放弃Phantomjs。
ChromeDriver
谷歌浏览器驱动安装
镜像站地址
查看Chrome浏览器版本
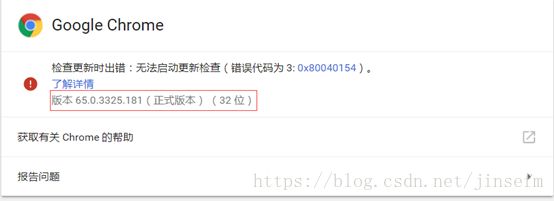
不知道拿哪个Driver版本,百度到chrome浏览器v65.0.3325.181此版本发布日期3-21左右,找到如下版本:
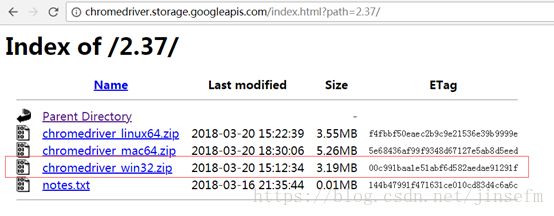
解压后放到Python安装目录下或另配环境变量到Path。
#代码测试成功
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://item.jd.com/7652139.html")
time.sleep(5)
driver.close()GeckoDriver
火狐浏览器驱动下载地址 好像没有版本之分
#代码测试成功
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://item.jd.com/7652139.html")
time.sleep(5)
driver.close()PhantomJS
实现无界浏览器 官方下载地址
下载后解压将phantomjs.exe放入python安装路径下的Scripts目录或另配环境变量指向此文件所在路径即可
PhantomJS 是一个无界面的、可脚本编程的WebKit浏览器引擎,它原生支持多种Web标准:DOM操作、CSS选择器、JSON、Canvas以及SVG。
Selenium最新版本目前已经不支持PhantomJS。但Selenium2.48.0旧版本可实现运行时不弹出浏览器。
Phantomjs运行效率很高,支持各种参数配置,使用非常方便。
#以下代码需配合selenium2.48.0 版本库
from selenium import webdriver
browser =webdriver.PhantomJS()
browser.get('https://www.baidu.com')
baidu =browser.find_element_by_id('su').get_attribute('value')
print(baidu)
browser.close()另一种实现无界浏览器为 Selenium+Headless Chrome
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options =Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver=webdriver.Chrome(executable_path=’./chromedriver.exe’,chrome_options=chrome_options)
#chromedriver没有配在环境变量path中时,第一个参数需手动指定驱动绝对路径
driver.get('https://www.baidu.com')
baidu =driver.find_element_by_id('su').get_attribute('value')
print(baidu)
driver.close()aiohttp
程序在请求等待中做一些其他的事情,Aiohttp是这样一个提供异步Web服务的库。
官方推荐两个库:字符编码检测库cchardet,加速DNS解析库 aiodns。
pip3 install cchardet aiodns
pip3 install aiodns
2.解析库
tesserocr
Python OCR 识别库
[1] tesseract 安装Windows版软件 获取tessdata目录 下载地址tesseract-ocr-setup-3.05.02-20180621.exe
[2] 安装tesserocr库 下载地址tesserocr-2.2.2-cp35-cp35m-win32.whl
pip install tesserocr-2.2.2-cp36-cp36m-win_amd64.whl
#验证tesserocr库安装是否成功代码
import tesserocr
from PIL import Image
imgg=Image.open("C:\\Users\\xxx\\Desktop\\image.png")
print(tesserocr.image_to_text(imgg))
将以上图片保存至电脑桌面并命名为image.png
运行上述代码后,输出Python3WebSpider即安装成功
若报错 Failed to init API, possibly an invalid tessdata path: C:\mysoft\Python36
则:将D:\Program Files (x86)\Tesseract-OCR (tesseract的安装文件夹)下的tessdata目录复制到Python安装目录中即可。
lxml
Beautiful Soup
pyquery
默认安装即可
pip3 install lxml
pip3 install beautifulsoup
pip3 install pyquery
3.数据库
mysql
https://blog.csdn.net/since_1904/article/details/70233403
mongoDB
mongoDB 是一个基于分布式文件存储的开源数据库系统,其内容存储形式类似JSON对象,它的字段值可以包含其他文档、数组以及文档数组,相当灵活。
https://www.cnblogs.com/tim100/p/6721415.html
可视化工具Robo3T
https://fastdl.mongodb.org/win32/mongodb-win32-x86_64-2008plus-ssl-4.0.1-signed.msi
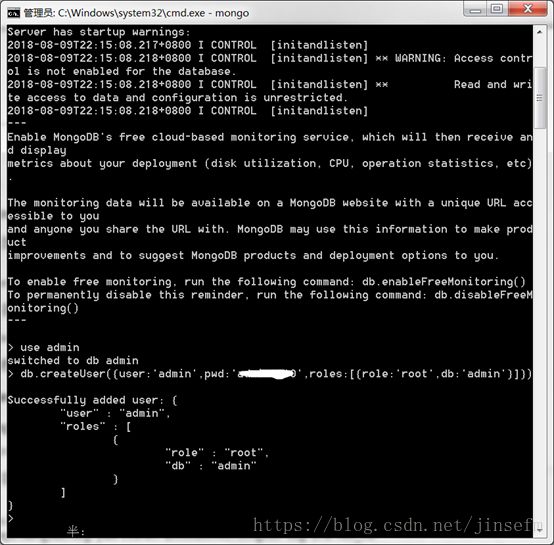
创建最高权限用户
Redis
Redis是一个基于内存的高效的非关系型数据库。
https://github.com/MSOpenTech/redis/releases
可视化工具 RedisDesktop Manager
https://redisdesktop.com/download
https://github.com/uglide/RedisDesktopManager/releases
4.存储库
Pymysql
pip install pymysql
PyMongo
pip install pymongo
Redis-py
pip install redis
RedisDump
RedisDump 是一个用于Redis数据导入/导出的工具,要安装RedisDump前先安装Rudy。
在Ruby装完后 命令行 gem install redis-dump
Ruby下载地址
安装windows版的Ruby最好默认安装不要更换安装目录以防
gem install redis-dump 安装RedisDump时报错
5.Web库
Flask
pip3 install flask
安装Flask后用以下测试是否可正常运行Flask
from flask import Flask
app=Flask(__name__)
@app.route("/")
def hell0():
return "Hello World!"
if __name__ =="__main__":
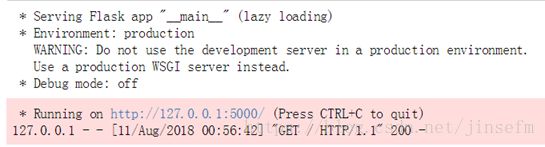
app.run()报错如下:
UnsupportedOperation Traceback (most recent call last)
<ipython-input-1-d8132276117c> in <module>()
6 return "Hello World!"
7 if __name__ =="__main__":
----> 8 app.run()
c:\mysoft\python36\lib\site-packages\flask\app.py in run(self, host, port, debug, load_dotenv, **options)
936 options.setdefault('threaded', True)
937
--> 938 cli.show_server_banner(self.env, self.debug, self.name, False)
939
940 from werkzeug.serving import run_simple
c:\mysoft\python36\lib\site-packages\flask\cli.py in show_server_banner(env, debug, app_import_path, eager_loading)
627 message += ' (lazy loading)'
628
--> 629 click.echo(message)
630
631 click.echo(' * Environment: {0}'.format(env))
c:\mysoft\python36\lib\site-packages\click\utils.py in echo(message, file, nl, err, color)
257
258 if message:
--> 259 file.write(message)
260 file.flush()
261
UnsupportedOperation: not writable解决办法:
You need to edit the echo function definition at ../site-packages/click/utils.py the default value for the file parameter must be sys.stdout instead of None.
Do the same for the secho function definition at ../site-packages/click/termui.py
即[Python安装目录\Lib\site-packages\click]目录下有两份文件需要修改:
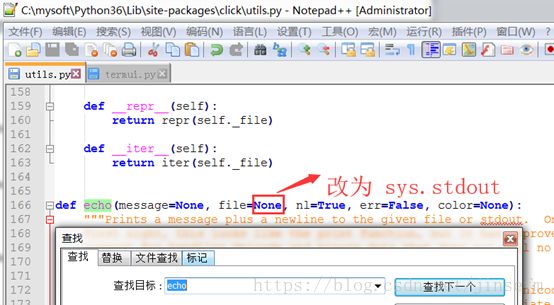

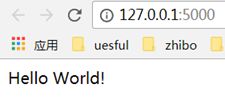
改完后测试如下,正常显示Hello World!
Tornado
一个支持异步的Web框架,通过使用非阻塞I/O流,它可以支撑成千上万的开放连接,效率非常高。
pip3 install tornado
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello,world")
def make_app():
return tornado.web.Application([(r"/",MainHandler),])
if __name__ =="__main__":
tornado.ioloop.IOLoop.current().stop()
app=make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()6.App爬取相关库
Charles
网络抓包工具,相比Fiddler功能更强大,跨平台。
mitmproxy
pip3 install mitmproxy
https://github.com/mitmproxy/mitmproxy/releases
Appium
移动端自动化测试工具,模拟点击、滑动、输入等操作
appium-desktop-setup-1.6.2.exe
使用Appium还需下载Android SDK,配置SDK环境变量
ANDROID_HOME:sdk路径
Path:增加sdk路径下tools和platform-tools文件夹
7.爬虫框架
pyspider
先下载安装PyCurl库pycurl-7.43.1-cp36-cp36m-win_amd64.whl
之后安装pyspider
pip3 install pyspider
可能报错:
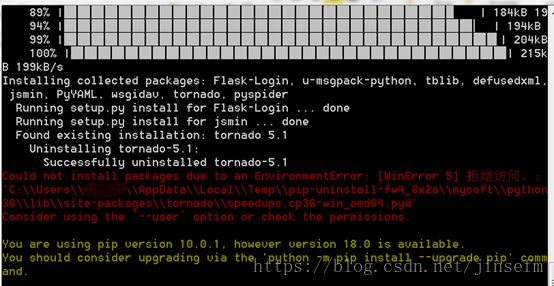
不知咋地,再输一次pip3 install pyspider 安装成功
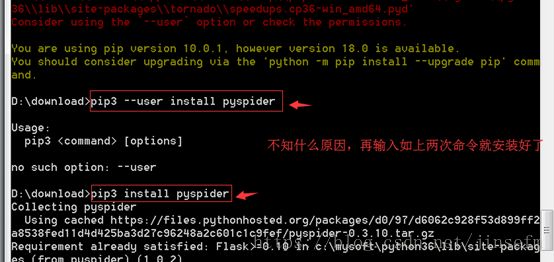
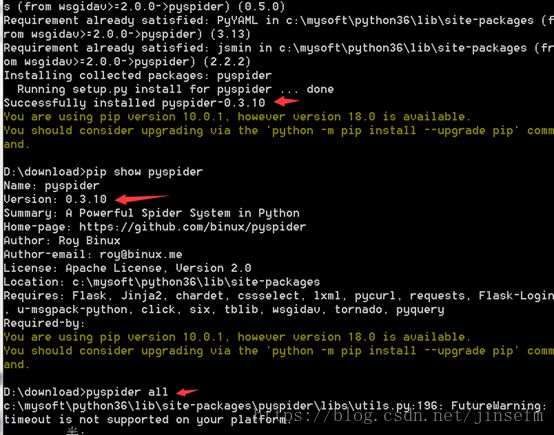
验证安装成功 pyspider all
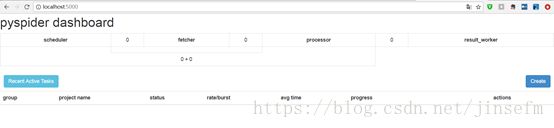
Scrapy
一个十分强大的爬虫框架,依赖的基本库有Twisted 14.0、lxml3.4 和pyOpenSSL 0.14.不同平台所依赖的库各不相同。使用Anaconda安装简单粗暴。
先安装Anaconda
之后打开 Anaconda Prompt
输入conda install Scrapy即可
Scrapy-Redis
Scrapy的分布式扩展块,可以方便地实现Scrapy分布式爬虫的搭建。
Scrapy-Redis
依赖于Twisted库
pip3 install twisted
pip3 install scrapy-redis
Scrapy-Splash
pip3 install scrapy-splash
9.部署安装库
Docker
Docker 是一种容器技术,可以将应用和环境等进行打包,形成一个独立的、类似于IOS的App形式的应用。这个应用可以直接被分发到任意一个支持Docker的环境中,通过简单的命令即可启动运行。
Window10 64位版本的安装地址
其他Windows版本安装Docker Toolbox
Scrapyd
Scrapyd是一个用于部署和运行Scrapy项目的工具,可将写好的Scrapy项目上传至云主机并通过API来控制其运行。
pip3 install scrapyd
Scrapyd-Client
pip3 install scrapyd-client
Scrapyd API
获取当前主机的Scrapy任务运行状况
pip install python-scrapyd-api
Scrapyrt
为Scrapy提供一个调度的HTTP接口,这样可以请求一个HTTP接口来调度Scrapy任务。Scrapyrt比Scrapyd更轻量,但不支持分布式多任务。
pip3 install scrapyrt
Gerapy
一个Scrapy分布式管理模块
pip3 install gerapy