windows 10 基于Tensorflow的街头行人检测实验
本实验并没有按照网上现有的千篇一律的指导书在linux上进行实验,而是尝试在Windows上进行本实验,并记录实验的详细过程。这一方面的资料在互联网上较少,也算是一个比较好的补充。
github地址:
https://github.com/jmhIcoding/pedestrain_detection.git
一、实验步骤
1、环境搭建
1.1 安装Tensorflow 1.13.0
pip3 install tensorflow --upgrade
pip3 install tensorflow-gpu --upgrade
1.2 安装slim Image Detect Library
git clone https://github.com/tensorflow/models
1.3 安装Object Dection需要的环境
安装好SLIM Image Detect Library就有ObjectDetect目录了.但是要使用Object Dection,需要后续安装。
安装protoc:
Windows 10下可以直接下载已经编译好的protoc可执行文件,一定要安装3.4.0版本的protoc才不会报错。
https://github.com/protocolbuffers/protobuf/releases/download/v3.4.0/protoc-3.4.0-win32.zip
安装python依赖库
pip3 install pillow lxml matplotlib contextlib2 jupyter cython
安装COCO API
编译COCO API,cocodataset自带的coco是不在windows支持的!!
解决方法:
git clone https://github.com/philferriere/cocoapi.git
cd PythonAPI
python3 setup.py build_ext –inplace
然后再把pycocotools文件夹拷贝到models/research目录下。如果安装不成功,参见:
https://blog.csdn.net/jmh1996/article/details/91350035 Windows 10 安装 cocoapi。
使用protoc编译接口
在models\research目录下,运行:
protoc.exe .\object_detection\protos\*.proto --python_out=.
![]()
注意!!! 一定要安装protoc 3.4.0 否则无法解析里面的通配符!
1.4 测试一波:
新建一个环境变量:PYTHONPATH,
它的值是models\research 和models\research\slim所在的目录。

运行 object_detection\builders\model_builder_test.py 试试:
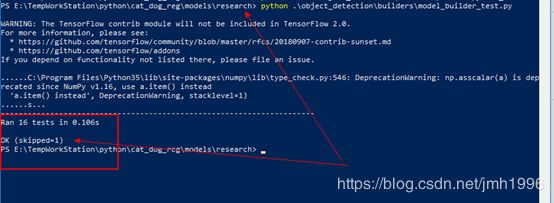
出现OK,然后就OK啦~~~~
1.5 下载数据集以及预训练模型
预训练模型:
http://download.tensorflow.org/models/object_detection/faster_rcnn_inception_v2_coco_2018_01_28.tar.gz
在~/models/research 目录下新建pedestrain_detection目录
数据主页: http://www.robots.ox.ac.uk/ActiveVision/Research/Projects/2009bbenfold_headpose/project.html#datasets
其中:
视频文件为:http://www.robots.ox.ac.uk/ActiveVision/Research/Projects/2009bbenfold_headpose/Datasets/TownCentreXVID.avi
标注数据为:http://www.robots.ox.ac.uk/ActiveVision/Research/Projects/2009bbenfold_headpose/Datasets/TownCentre-groundtruth.top
然后把数据放在这个目录下。
1.6 安装opencv解析视频

(本人数据预处理是在windows 做的)
2、数据预处理
2.1 从视频中提取图像,并按要求减半。
代码为:capture_from_stream.py
__author__ = 'jmh081701'
#将视频的每一帧提取出来,前4500做训练集
import cv2
def capture_from_video(video,train,test):
frame = 0
cap = cv2.VideoCapture(video)
length = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
factor = 2
while True:
check ,img = cap.read()
if check:
if frame < 4500:
path = train
else:
path = test
img = cv2.resize(img,(1920//factor,1080//factor))
cv2.imwrite(path+"//"+str(frame)+".jpg",img)
frame+=1
else:
break
cap.release()
if __name__ == '__main__':
capture_from_video("TownCentreXVID.avi",train='./images',test='./test_images')
跑脚本,得到每一帧的图片:

2.2 从标注数据中提取所需数据
代码见parse_top.py,导出csv格式的文件,方便后续处理。
在导出的时候,根据指导书的要求把4500张图片中的95%划分为训练集,5%的划分为验证集。
__author__ = 'jmh081701'
#将top文件中的核心数据提取出来
import json
import random
import copy
json_template={
'size':{'width':"960",'depth':"3","height":"540"},
'filename':'0.jpg',
"object":[]
}
object_template={
"bndbox":
{
"xmin":"",#左上角
"ymin":"",#左上角
"xmax":"",#右下角
"ymax":""
},
"name":"pedestrain",
"id" :"1"
}
#name : 表示需要检测的目标的名字
#id : 给这个目标编号一个id
#name 和 id 后面需要和 label_map.pbtxt保持一致
def read_top(file):
with open(file,'r') as fp:
infos=[]
info = copy.deepcopy(json_template)
lines = fp.readlines()
lastframe=0
for line in lines:
line = line.strip().split(",")
frameNumber = int(line[1])
xmin=abs(float(line[-4])-2)/2
ymin=abs(float(line[-3])-2)/2
xmax=abs(float(line[-2])-2)/2
ymax=abs(float(line[-1])-2)/2
if lastframe!=frameNumber:
#新的帧
if len(info['object']) > 0:
infos.append(copy.deepcopy(info))
print(info['filename'])
#保存每一帧的文件名
info = copy.deepcopy(json_template)
lastframe = frameNumber
info['filename']="%s.jpg"% frameNumber
object_ = copy.deepcopy(object_template)
object_['bndbox']['xmin']=copy.deepcopy(xmin)
object_['bndbox']['xmax']=copy.deepcopy(xmax)
object_['bndbox']['ymin']=copy.deepcopy(ymin)
object_['bndbox']['ymax']=copy.deepcopy(ymax)
info['object'].append(copy.deepcopy(object_))
#parse over.
#with open('json','w') as fp2:
# #保存为json为文件
# json.dump(infos,fp2)
return infos
if __name__ == '__main__':
infos=read_top(r"TownCentre-groundtruth.top")
train_fp=open('pedestrain_train.csv','w')
valid_fp=open('pedestrain_valid.csv','w')
train_fp.writelines("class,filename,height,width,xmax,xmin,ymax,ymin\n")
valid_fp.writelines("class,filename,height,width,xmax,xmin,ymax,ymin\n")
for info in infos:
filename = info['filename']
height = int(info['size']['height'])
width = int(info['size']['width'])
print(filename)
if random.random()<0.05:
#划分数据集
fp = valid_fp
else:
fp = train_fp
for object_ in info['object']:
xmin=object_['bndbox']['xmin']
xmax=object_['bndbox']['xmax']
ymin=object_['bndbox']['ymin']
ymax=object_['bndbox']['ymax']
name=object_['name']
fp.writelines("%s,%s,%d,%d,%s,%s,%s,%s\n"%(name,filename,height,width,xmax,xmin,ymax,ymin))
train_fp.close()
valid_fp.close()
2.3 将图片转换为TF_RECORD格式
代码参见:generate_tfrecord.py
训练集保存为train.record
![]()
验证集保存为valid.record
![]()
最后得到两个record文件:
![]()
有一点需要注意的是,提供的数据集有的边框会超出实际的图片大小。
2.4 编写label_map.pbtxt文件
item {
id :1
name : ‘pedestrain’
}
2.5 编写config文件
见pipeline.config文件
manual_step_learning_rate {
initial_learning_rate: 0.000199999994948
schedule {
step: 900000
learning_rate: 1.99999994948e-05
}
schedule {
step: 1200000
learning_rate: 1.99999999495e-06
}
}
}
momentum_optimizer_value: 0.899999976158
}
use_moving_average: false
}
gradient_clipping_by_norm: 10.0
fine_tune_checkpoint: "E:\TempWorkStation\python\pedestrain_detect\pretrained\model.ckpt"
from_detection_checkpoint: true
num_steps: 10000
}
train_input_reader {
label_map_path: "E:\TempWorkStation\python\pedestrain_detect\anotation\label_map.pbtxt"
tf_record_input_reader {
input_path: "E:\TempWorkStation\python\pedestrain_detect\train.record"
}
}
eval_config {
num_examples: 250
max_evals: 10
use_moving_averages: false
}
eval_input_reader {
label_map_path: "E:\TempWorkStation\python\pedestrain_detect\anotation\label_map.pbtxt"
shuffle: false
num_readers: 1
tf_record_input_reader {
input_path: "E:\TempWorkStation\python\pedestrain_detect\valid.record"
}
}
注意 加粗部分需要改成自己需要的格式!!!
三、模型训练
3.1 模型训练
见main.py
__author__ = 'jmh081701'
import os
import sys
if __name__ == '__main__':
cmd="& 'E:\Program Files (x86)\Python36\python.exe' " \
".\object_detection\model_main.py " \
"--pipeline_config_path=E:\TempWorkStation\python\pedestrain_detect\pretrained\pipeline.config " \
"--model_dir=E:\TempWorkStation\python\pedestrain_detect\train " \
"--num_train_steps=20000 " \
"--sample_1_of_n_eval_eval_examples=1 " \
"--alsologtostderr"
export_graph_cmd=" & 'E:\Program Files (x86)\Python36\python.exe' " \
".\object_detection\export_inference_graph.py " \
"--pipeline_config_path=E:\TempWorkStation\python\pedestrain_detect\pretrained\pipeline.config " \
"--input_type=image_tensor " \
"--trained_checkpoint_prefix=E:\TempWorkStation\python\pedestrain_detect\train\model.ckpt-2393 " \
"--output_directory=E:\TempWorkStation\python\pedestrain_detect\train\save_model\\"
os.system(cmd)
根据自己的python路径和代码的路径做修改。
3.2 训练过程
mAP的变化趋势:

在训练3000多个step后,mAP有达到51%左右
召回率的变化:
 。
。
模型的召回率特别低,这是不足的地方。
LOSS的变化:

RPN的边框回归的损失越来越小。

验证集的行人检测结果

可以看到,验证集上的预测结果还是可以的,上图除了左下角那个人没有检测出来以外,其他人都检测出来了。
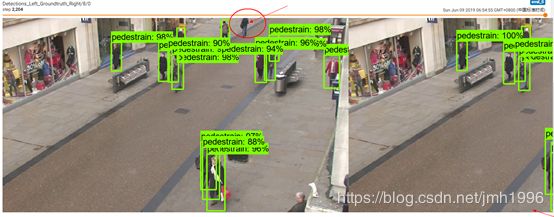
上图除了正中上方那个人没有检测出来以外,其他都检测出来。
3.2 模型预测
因为设备使用的是GTX 1600,训练了一晚上10个小时左右才训练了2000多步。以下就基于这2000多步来了。
- 导出计算图:
参见main.py的export_graph_cmd
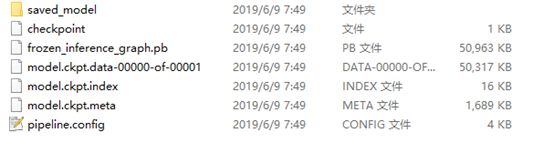
- 编写测试脚本
见inference_object_detect.py 可以直接在视频上实时地把行人标注出来。
测试结果:

测试结果已经录制为gif文件,直接打开test.gif 就可以观察效果!
[外链图片转存失败(img-8rYQj3T7-1562933620648)(https://github.com/jmhIcoding/pedestrain_detection/blob/master/test.gif)]
四、实验总结
本实验通过使用object_detection开源代码以及预训练模型,实现了街头行人检测的功能。实验结果符合预期目标,实验进行的相对顺利。
本实验的主要工作有三个,一个是搭建目标检测的实验环境,另外一个是将给定的视频数据转换为tfrecord格式的数据集文件,最后一个是编写测试脚本。因此本实验更多的是训练如何使用预训练模型。
本小组并没有按照实验指导书在linux上进行实验,而是尝试在Windows上进行本实验,并记录实验的详细过程。这一方面的资料在互联网上较少,也算是一个比较好的补充。
但是,训练了过程中我们发现目标检测模型似乎只使用了CPU,并没有使用GPU,这是比较奇怪的地方。后面核实发现,本机安装的cuda版本就9.1,而tensorflow 13.0需要更高版本的cuda.
五、文件目录:
.\src\save_model 模型训练结果
.\src\capture_from_stream.py 打开视频文件,并把视频文件的图片提取出来,然后大小变为原来的一半
.\src\generate_tfrecord.py 根据数据集,生成tfrecord文件
.\src\inference_object_detection.py 模型预测文件
.\src\main.py 模型训练和图数据导出脚本
.\src\parse_top.py 解析top文件,提取目标的边框
.\src\pipeline.config 训练的配置文件
.\src\test.git 预测结果形成的gif动态图