摘自命名实体识别类论文
一、简介
1995年命名实体识别由第六届消息理解会议第一次引入,主要任务是自动识别出文本中出现的命名性指称和有意义的数量短语并加以归类,包括三大类(实体类、时间类、数字类)、七小类(人名、地名、机构名、时间、日期、货币、和百分比),其中时间、日期、货币和百分比的构成有明显的规律,相对容易识别和分类,因此主要针对人名、地名、机构名这三类命名实体开展研究工作。
1、命名实体识别在信息抽取中的作用
命名实体是文本中信息的主要载体,是构建信息抽取系统的重要组成部分。关系抽取的任务是抽取实体之间的语义关系,因此首先需要识别文本中的命名实体,然后才可以抽取他们之间的关系。事件抽取中的时间元素抽取同样需要命名实体识别。
2、命名实体识别在开放域问答中的作用
在开放域问答系统中,常常会遇到需要回答某个人名、地点、日期、机构以及其他实体的事实型问题,而通常分词结果并不能满足需要,因此答案只能返回段落或篇章。将命名实体识别技术应用在其上,可以对文本中的上述信息做出更准确的分析。
3、命名实体识别在信息检索中的作用
例如搜索“北京”,google会返回“知识图谱”中北京的相关信息,包括地图信息、简介、人口、人口、面积、海拔、天气、当地时间等基本信息以及一些著名的旅游景点。
4、命名实体识别在机器翻译中的作用
由于实体的命名有其特殊性,常有习惯用法在其中,所以给机器翻译带来了困难,比如“中国银行”的英文是“Bank of China”,而译为“China Bank”就错了,而“澳洲国民银行”则译为“National Australia Bank”,而不是“NAtional Bank of Australia”。
二命名实体方法
1、基于规则和词典的命名实体识别方法
早期的命名实体识别工作都采用基于手写规则和词典的方法。这类方法大多数依赖于语言学专家构建的规则知识库和词典等资源,包括关键字、指示词、中心词、前后缀子串等,主要一模式匹配或字符串匹配的方法识别命名实体。
但是,该方法会遇到知识瓶颈问题。具体来讲,第一个缺点是由于人类语言的复杂性和灵活性,规则的编制过程费时费力且难以涵盖所有的语言现象,而且不同的规则之间易出现冲突,需要反复验证,建设成本高;另一方面,依赖于具体语言、领域、文本风格,可移植性不好。
2、基于有指导机器学习的命名实体识别方法
通常的机器学习是所谓的有指导机器学习,它需要足够多的人工标注的语料,作为学习的对象,普通人略加培训即可完成任务,相对与构建规则来说,难度大大降低。其主要思想是从训练语料中学习出一个模型,当心的数据到来时,可以根据这个模型预测结果。主要的机器学习方法包括:隐马尔可夫模型、最大熵模型、条件随机场、决策树、支持向量机
但是,机器学习方法主要的不足是数据稀疏问题,即训练数据不足。常见现象出现频率高、统计方法有效,而对不常见的长尾现象,在有限的标注语料中不足以显现其规律性。
3、基于半指导机器学习的命名实体抽取方法
基于半指导(弱指导)的机器学习的提出就是为了解决有指导方法的只是瓶颈问题。这类方法把未标注的海量自然文本作为学习对象,通常才用自举法(Bootstrapping),辅以“种子(seed)”或“样榜(sample)”为目标,引导过程。例如想要识别“药品”这一类命名实体,首先需要人工给定少量的药品名作为种子,如“阿司匹林”、“青霉素”等;然后检索包含这些种子的句子,抽取公共的上下文模式;接着出现在相似的上下文模式中的更多的药品实例可以被抽取出来,这些实例又可以作为种子开始新一轮的循环,如此反复迭代,获取大量药品名。
需要说明的是,抽取和识别虽然看似相同,但事实上是有本质区别的。抽取任务指从大规模的语料中抽取特定类型的信息,通常将这些信息组织成列别哦或知识库等;而识别任务则要找出语聊中特定类型信息在预料中出现的所有位置,前者只需找到部分即可。
4、基于无指导机器学习的命名实体抽取方法
聚类是典型的无指导机器学习算法。比如根据上下文的相似性推测出实体的相似性,从未通过聚类扩展已知的实体集合。
5、领域自适应的命名实体识别方法
思路是将源领域效果较好的命名实体识别器迁移到目标领域,可以利用目标领域大规模未标注的数据以及少量的标注数据等,尽可能减少人工标注。
6、开放域命名实体的类别获取
6、1基于词典资源的命名实体类别获取
一些研究者利用前任构建的词典知识库资源作为类别的来源,向WordNet、Linked Open Data(LOD)、Freebase、DBpedia、YAGO等知识库中已经包含了一些实体及上下位关系,但其规模还没有涵盖世界上所有的实体。
6、2基于模式匹配的命名实体类别获取
例如
NP such as NP,NP...(and | or) NP
NP ,NP*,or otherNP
NP,including NP,* or | and NP
其中加上下划线的NP为上位词,其余NP为对应的下位词。然后迭代地抽取实例、扩展抽取模式,最终获得大量下位词对。
6、3基于词语分布相似度的命名实体类别获取
另外一条获取上位词的思路是基于词语分布相似度的方法。这类方法基于一个假设:语义范畴广的词,其所在上下文也广;语义范畴窄的词,其所在上下文也窄。也就是说一个词所在上下文是其上位词所在上下文的一个真子集。
其中,Fx表示x的特征向量,Wu(f)表示特征值,上述公式实际上表示词u的上下文包含在v的上下文中的比例,比例越高,v作为u的上位词的可能性越大。
改进:
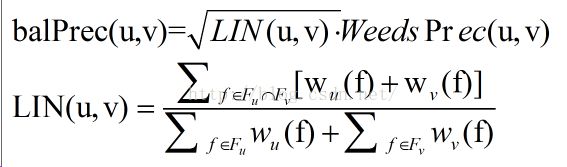
若WeedsPrec(u,v)=1,判断结果u语义蕴含v,这显然不合理,因此szpektor和Dangan做了上面的改进,还有一种改进是将分母中的Wu(f)改为min(Wu(f),Wv(f))。
二、哈工大:开放域命名实体识别及其层次化类别获取
1、基于双语平行语料的命名实体语料自动标注方法,自动生成大规模的命名实体训练语料,节省人工标注成本。
2、利用标注专有名词的语料,以及依存树库生成名词复合短语语料,然后基于自学习方法的边界识别模型训练方法将两部分融合,同时迭代训练命名实体边界识别模型