Dijkstra、Bellman-Ford、SPFA、ASP、Floyd-Warshall 算法分析
图论中,用来求最短路的方法有很多,适用范围和时间复杂度也各不相同。
本文主要介绍的算法的代码主要来源如下:
- Dijkstra: Algorithms(《算法概论》)Sanjoy Dasgupta, Christos Papadimitriou, Umesh Vazirani;《算法竞赛入门经典—训练指南》刘汝佳、陈峰。
- SPFA (Shortest Path Faster Algorithm): Data Structure and Algorithms Analysis in C, 2nd ed.(《数据结构与算法分析》)Mark Allen Weiss.
- Bellman-Ford: Algorithms(《算法概论》)Sanjoy Dasgupta, Christos Papadimitriou, Umesh Vazirani.
- ASP (Acyclic Shortest Paths): Introduction to Algorithms - A Creative Approach(《算法引论—一种创造性方法》)Udi Manber.
- Floyd-Warshall: Data Structure and Algorithms Analysis in C, 2nd ed.(《数据结构与算法分析》)Mark Allen Weiss.
它们的使用限制和运行时间如下:
Dijkstra: 不含负权。运行时间依赖于优先队列的实现,如 O((∣V∣+∣E∣)log∣V∣)
SPFA: 无限制。运行时间O(k⋅∣E∣) (k≪∣V∣)
Bellman-Ford:无限制。运行时间O(∣V∣⋅∣E∣)
ASP: 无圈。运行时间O(∣V∣+∣E∣)
Floyd-Warshall: 无限制。运行时间O(∣V∣^3)
其中 1~4 均为单源最短路径 (Single Source Shortest Paths) 算法;5 为全源最短路径 (All Pairs Shortest Paths) 算法。顺便说一句,为什么没有点对点的最短路径?如果我们只需要一个起点和一个终点,不是比计算一个起点任意终点更节省时间么?答案还真不是,目前还没有发现比算从源点到所有点更快的算法。
分析完时间复杂度之后,再来看平时比赛或者其他使用上的具体情况:
Dijkstra:适用于权值为非负的图的单源最短路径,用斐波那契堆的复杂度O(E+VlgV)
BellmanFord:适用于权值有负值的图的单源最短路径,并且能够检测负圈,复杂度O(VE)
SPFA:适用于权值有负值,且没有负圈的图的单源最短路径,论文中的复杂度O(kE),k为每个节点进入Queue的次数,且k一般<=2,但此处的复杂度证明是有问题的,其实SPFA的最坏情况应该是O(VE).
Floyd:每对节点之间的最短路径。
这里给出结论:
(1)当权值为非负时,用Dijkstra。
(2)当权值有负值,且没有负圈,则用SPFA,SPFA能检测负圈,但是不能输出负圈。
(3)当权值有负值,而且可能存在负圈,则用BellmanFord,能够检测并输出负圈。
(4)SPFA检测负环:当存在一个点入队大于等于V次,则有负环,后面有证明。
1)图的表示
本文中,前四个算法的图都采用邻接表表示法,如下:
struct Edge
{
int from;
int to;
int weight;
Edge(int f, int t, int w):from(f), to(t), weight(w) {}
};
int num_nodes;
int num_edges;
vector edges;
vector G[max_nodes]; // 每个节点出发的边编号
int p[max_nodes]; // 当前节点单源最短路中的上一条边
int d[max_nodes]; // 单源最短路径长 2)Dijkstra 方法
Dijkstra 方法依据其优先队列的实现不同,可以写成几种时间复杂度不同的算法。它是图论-最短路中最经典、常见的算法。关于这个方法,网上有许多分析,但是我最喜欢的还是《算法概论》中的讲解。为了理解 Dijkstra 方法,首先回顾一下无权最短路的算法。无权最短路算法基于 BFS,每次从源点向外扩展一层,并且给扩展到的顶点标明距离,这个距离就是最短路的长。我们完全可以仿照这个思路,把带权图最短路问题规约到无权图最短路问题——只要把长度大于 1 的边填充进一些「虚顶点」即可。如下图所示。
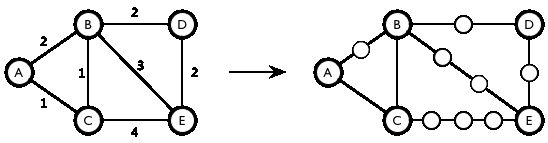
这个办法虽然可行,但是显然效率很低。不过,Dijkstra 方法EC,EB,ED分别出发,经过一系列「虚节点」,依次到达D,B,C 。为了不在虚节点处浪费时间,出发之前,我们设定三个闹钟,时间分别为4,3,2提醒我们预计在这些时刻会有重要的事情发生(经过实际节点)。更一般地说,假设现在我们处理到了某个顶点u,和u相邻接的顶点为v1,v2,…,vn,它们和u的距离为d1,d2,…,dn。我们为v1,v2,…,vn各设定一个闹钟。如果还没有设定闹钟,那么设定为d ;如果设定的时间比d晚,那么重新设定为d(此时我们沿着这条路比之前的某一条路会提前赶到)。每次闹钟响起,都说明可能经过了实际节点,我们都会更新这些信息,直到不存在任何闹钟。综上所述,也就是随着 BFS 的进行,我们一旦发现更近的路径,就立即更新路径长,直到处理完最后(最远)的一个顶点。由此可见,由于上述「虚顶点」并非我们关心的实际顶点,因此 Dijkstra 方法的处理方式为:直接跳过了它们。
还需要解决的一个问题,就是闹钟的管理。闹钟一定是从早到晚按顺序响起的,然而我们设闹钟的顺序却不一定按照时间升序,因此需要一个优先队列来管理。Dijkstra 方法实现的效率严重依赖于优先队列的实现。一个使用标准库容器适配器 priority_queue 的算法版本如下:
typedef pair HeapNode;
void Dijkstra(int s)
{
priority_queue< HeapNode, vector, greater > Q;
for (int i=0; i N = Q.top();
Q.pop();
int u = N.second;
if (N.first != d[u]) continue;
for (int i=0; i d[u] + e.weight) {
d[e.to] = d[u] + e.weight;
p[e.to] = G[u][i];
Q.push(make_pair(d[e.to], e.to));
}
}
}
} 3)Bellman-Ford:一个简单的想法
Dijkstra 方法的本质是进行一系列如下的更新操作:
d(v)=min{d(v), d(u)+l(u,v)}
然而,如果边权含有负值,那么 Dijkstra 方法将不再适用。原因解释如下。
假设最终的最短路径为:
s→u1→u2→u3→…→uk→t
不难看出,如果按照 (s, u1), (u1, u2), …,(uk, t) 的顺序执行上述更新操作,最终的最短路径一定是正确的。而且,只要保证上述更新操作全部按顺序执行即可,并不要求上述更新操作是连续进行的。Dijkstra 算法所运行的更新序列是经过选择的,而选择基于这一假设:s→t的最短路一定不会经过和距离大于l(s, t)的点。对于正权图这一假设是显然的,对于负权图这一假设是错误的。
因此,为了求出负权图的最短路径,我们需要保证一个合理的更新序列。但是,我们并不知道最终的最短路径!因此一个简单的想法就是:更新所有的边,每条边都更新∣V∣−1次。由于多余的更新操作总是无害的,因此算法(几乎)可以正确运行。等等,为什么是∣V∣−1次?这是由于,任何含有∣V∣个顶点的图两个点之间的最短路径最多含有∣V∣−1条边。这意味着最短路不会包含环。理由是,如果是负环,最短路不存在;如果是正环,去掉后变短;如果是零环,去掉后不变。
算法实现中唯一一个需要注意的问题就是负值圈 (negative-cost cycle)。负值圈指的是,权值总和为负的圈。如果存在这种圈,我们可以在里面滞留任意长而不断减小最短路径长,因此这种情况下最短路径可能是不存在的,可能使程序陷入无限循环。好在,本文介绍的几种算法都可以判断负值圈是否存在。对于 Bellman-Ford 算法来说,判断负值圈存在的方法是:在次循环之后再执行一次循环,如果还有更新操作发生,则说明存在负值圈。
Bellman-Ford 算法的代码如下:
bool Bellman_Ford(int s)
{
for (int i=0; i d[edges[e].from] + edges[e].weight
&& d[edges[e].from] != __inf) {
d[edges[e].to] = d[edges[e].from] + edges[e].weight;
p[edges[e].to] = e;
changed = true;
}
}
if (!changed) return true;
if (i == num_nodes && changed) return false;
}
return false; // 程序应该永远不会执行到这里
} 注记:
- 如果某次循环没有更新操作发生,以后也不会有了。我们可以就此结束程序,避免无效的计算。
- 上述程序中第 11 行的判断:如果去掉这个判断,只要图中存在负值圈函数就会返回
false。否则,仅在给定源点可以达到负值圈时才返回false。
4)SPFA:一个改进的想法
看来,Bellman-Ford 算法多少有些浪费。这里介绍的 SPFA 可以算作是 Bellman-Ford 的队列改进版。在 Dijkstra 方法中,随着 BFS 的进行,最短路一点一点地「生长」。然而如果存在负权,我们的算法必须允许「绕回去」的情况发生。换句话说,我们需要在某些时候撤销已经形成的最短路。同时,我们还要改变 Bellman-Ford 算法盲目更新的特点,只更新有用的节点。SPFA 中,一开始,我们把源点 s放入队列中,然后每次循环让一个顶点u出队,找出所有与u邻接的顶点v,更新最短路,并当v不在队列里时将它入队。循环直到队列为空(没有需要更新的顶点)。
可以显示出 SPFA 和 Bellman-Ford 算法相比的一个重大改进的最经典的一个例子,就是图为一条链的情形。
容易看出,如果存在负值圈,这个算法将无限循环下去。因此需要一个机制来确保算法得以中止。由于最短路最长只含有∣V∣−1条边,因此如果任何一个顶点已经出队∣V∣+1次,算法停止运行。
证明如果有负环当且仅当存在一个点入队列次数大于等于V次:
对于某个点v,我们已知s到v的松弛路径的边的数量最多为V-1。
我这里说的松弛路径指的是:比如s直接松弛v,这样就有一条松弛路径:s->v 。s松弛a,a松弛v,则s->a->v就是一条松弛路径。
对于所有s到v的松弛路径来说,当松弛路径边的数量相等时,v只入队一次。
比如有松弛路径:
s->a->x->v
s->b->x->v
s->c->z->v,可以看出v只入队一次。
因为s到v的松弛路径的长度最多可以有V-1种变化,所以v最多入队V-1次。
举个例子:
假设有一个图,点集为{s,a,b,c,v},则最多可能的松弛路径有:
s->v
s->a->v
s->b->v
s->c->v
s->a->b->v
s->a->c->v
s->b->c->v
s->a->b->c->v
则松弛路径的边数变化有1,2,3,4,所以v入队为4次,即V-1次。
所以我们可以说每个点最多入队V-1次,因此我们求最坏情况为每个点都入队V-1次,所以此时:
![]()
这里举个最坏情况的例子。
当然我们可能考虑,当给定一个V的值,E的值,比如E=2V,怎么给出一个图,使得对此图运行SPFA算法的复杂度为O(VE).
我们这里假定图是连通的,所以E>=V-1。
方法如下:
(1)我们首先将图组成一个链,即如下图所示:
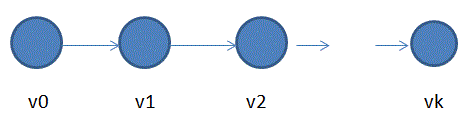
这样就用去了V-1条边。
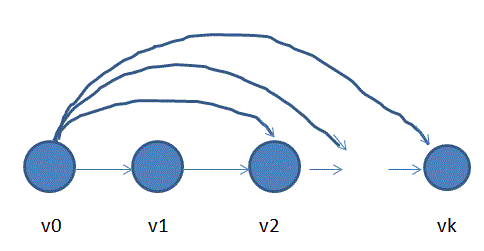
(2)分别添加v0连向v2,v3,….vk的边,我们要添加的这些边的权值要满足v0先更新vk,v0更新vk-1后vk-1还能更新vk,以此类推,如下图所示:
(3)以vk,vk-1,…..v1的顺序添加权值为正无穷的自环,且不断循环,这个步骤是为了保持v1到vk点的出度保持一致,所以这样做,如下图:
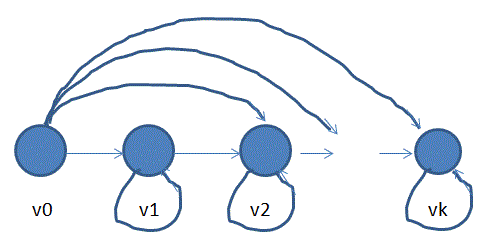
这样我们就构造了一个能够让SPFA跑出O(VE)的图了,原因如下:
因为我们E的值和V的值是不确定的,所以很有可能不能够完成上述的这些构造,我们会分析当没有剩余的边构造上面的步骤(2)时的复杂度(也就是说E<=2V-3,因为第一步连成一个链需要V-1条边,而第二步v0连出去的边需要V-2),和有足够的边能构造上面的图这两种情况。
(1)如果E<=2V-3
因为E<=2V-3,所以E=O(V),所以只要能够求出复杂度是O(V^2),即可说为O(VE).
我们要计算所有点的入队次数和访问的边数。
V0出度为 E-V+2,V0入队1次。
V1出度为1,V1入队为1次。
V2出度为1,V2入队为2次(分别为v0松弛v2,v1松弛v2)。
V3出度为1,V3入队为3次。
….
V(e-v+2)出度为1,入队次数为(E-V+2)次。
后面V(e-v+3),V(e-v+4),…..V(k-1)的出度为1,入队次数为E-V+2次。 这些点的个数为V-(E-V+3)-1 = 2V-E-4。
vk出度为0,vk入队为E-V+2次。
所以总共的访问的边数为:
![]()
(2)如果E>2V-3
此时构造图的第二步已经完毕,所以后面剩余的边只需要不断添加自环保持出度平衡即可。
V0出度为V-1,入队1次。
V1到Vk出度为(E-V+2)/(V-1) 或(E-V+2)/(V-1)+1。
v1到vk的入队次数分别为1,2,3,…..V-1。
所以总共访问边数为:
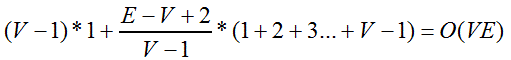
SPFA 的代码如下:
bool in_queue[max_nodes];
int cnt[max_nodes];
bool SPFA(int s)
{
int u;
queue Q;
memset(in_queue, 0, sizeof(in_queue));
memset(cnt, 0, sizeof(cnt));
for (int i=0; i d[u] + e.weight) {
d[e.to] = d[u] + e.weight;
p[e.to] = G[u][i];
if (!in_queue[e.to]) {
Q.push(e.to);
in_queue[e.to] = true;
if (++cnt[e.to] > num_nodes)
return false;
}
}
}
}
return true;
} 我们已经给出 SPFA 的运行时间为O(k⋅∣E∣) (k≪∣V∣)。实际上,可以期望k<2。但是可以构造出使 SPFA 算法变得很慢的针对性数据。
5)Acyclic Shortest Path
如果图是无圈的(acyclic)(或称为有向无环图,DAG),那么情况就变的容易了。我们可以构造一个拓扑升序序列,由拓扑排序的性质,无圈图的任意路径中,顶点都是沿着「拓扑升序序列」排列的,因此我们只需要按照这个序列执行更新操作即可。显然,这样可以在线性时间内解决问题。
实现上,拓扑排序和更新可以一趟完成。这种算法的代码如下:
int indegree[max_nodes];
void asp(int s)
{
queue Q;
for (int i=0; i d[w] + edges[G[w][i]].weight && d[w] != __inf) {
d[edges[G[w][i]].to] = d[w] + edges[G[w][i]].weight;
p[edges[G[w][i]].to] = G[w][i];
}
if (–indegree[edges[G[w][i]].to] == 0)
Q.push(edges[G[w][i]].to);
}
}
} 6)Floyd-Warshall
与前面四种不同,Floyd-Warshall 算法是所谓的「全源最短路径」,也就是任意两点间的最短路径。它并不是对单源最短路径
∣V∣次迭代的一种渐进改进,但是对非常稠密的图却可能更快,因为它的循环更加紧凑。而且,这个算法支持负的权值。
Floyd-Warshall 算法如下:
int dist[max_nodes][max_nodes]; // 记录路径长
int path[max_nodes][max_nodes]; // 记录实际路径
bool Floyd_Warshall()
{
for (int i=0; i dist[i][k] + dist[k][j]
&& dist[i][k] != __inf && dist[k][j] != __inf) {
dist[i][j] = dist[i][k] + dist[k][j];
path[i][j] = path[i][k];
if (i == j && dist[i][j] < 0)
return false;
}
}
}
}
return true;
} 其中 dist 数组应初始化为邻接矩阵。需要提醒的是, dist[i][i] 实际上表示「从顶点 i 绕一圈再回来的最短路径」,因此图存在负环当且仅当 dist[i][i]<0。初始化时, dist[i][i]可以初始化为0,也可以初始化为∞。
7)显示实际路径
显示实际路径实际上非常简单。利用前四个算法提供的 int *p,还原实际路径的一个方法如下:
void printpath(int from, int to, bool firstcall = true)
{
if (from == to) {
printf(”%d”, from);
return;
}
if (p[to] == -1) return;
if (firstcall) printf(“%d ->”, from);
int v = edges[p[to]].from;
if (v == from) {
if (firstcall) printf(“ %d”, to);
return;
}
printpath(from, v, false);
printf(” %d ->”, v+1);
if (firstcall) printf(“ %d”, to); 利用 Floyd-Warshall 算法提供的 int **path,还原实际路径的一个方法如下:
void showpath(int from, int to)
{
int c = from;
printf(”%d -> %d:(%2d) %d”, from, to, dist[from][to], from);
while (c != to) {
printf(” -> %d”, path[c][to]);
c = path[c][to];
}
printf(”\n”);
}