Jaeger 分布式追踪系统模块分析
- 概述
APM(Application Performance Managerment)系统致力于监控和管理应用软件性能和可用性。通过检测和诊断复杂应用程序的性能问题。来保证软件应用程序的良好运行与预期的服务。
容器和Serverless编程方式的诞生极大提升了软件交付和部署的效率。APM系统为了应对这种变化趋势,诞生了一系列面向DevOps的诊断和分析系统。包括集中式日志系统(Logging),集中式度量系统(Metrics)和分布式追踪系统(Tracing)。
分布式追踪系统用于记录请求范围内的信息。例如,一次远程方法调用的执行过程和耗时。是我们排查系统问题和系统性能的利器。
分布式追踪系统种类繁多,但是核心步骤有三个:代码埋点,数据存储和查询展示。
为了解决不同的分布式追踪系统API不兼容的问题,诞生了OpenTracing规范。
OpenTracing是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。
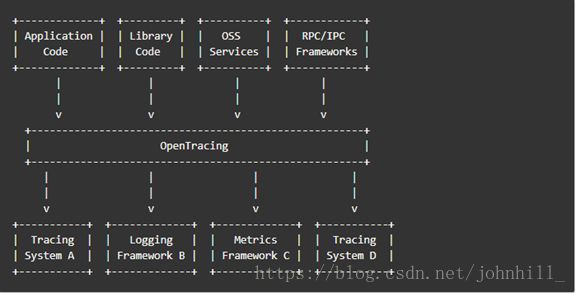
下面介绍一下OpenTracing的数据模型:
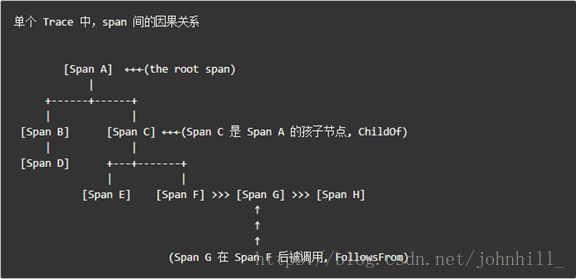
OpenTracing 中的 Trace(调用链)通过归属于此调用链的 Span 来隐性的定义。
特别说明,一条 Trace(调用链)可以被认为是一个由多个 Span 组成的有向无环图(DAG图),Span 与 Span 的关系被命名为 References。
例如:下面的示例 Trace 就是由8个 Span 组成:
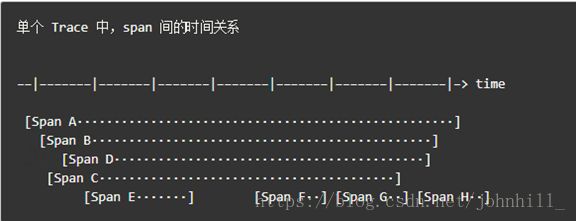
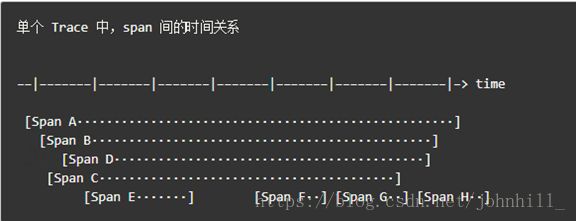
有些时候,使用下面这种,基于时间轴的时序图可以更好的展现 Trace(调用链):
每个 Span 包含以下的状态: operation name: 操作名称start timestamp: 起始时间finish timestamp: 结束时间Span Tag: 一组键值对构成的 Span 标签集合。键值对中,键必须为 string,值可以是字符串,布尔,或者数字类型。Span Log: 一组 span 的日志集合。每次 log 操作包含一个键值对,以及一个时间戳。键值对中,键必须为 string,值可以是任意类型。但是需要注意,不是所有的支持 OpenTracing 的 Tracer,都需要支持所有的值类型。SpanContext: Span 上下文对象 (下面会详细说明)。References(Span间关系): 相关的零个或者多个 Span(Span 间通过 SpanContext 建立这种关系)
每一个 SpanContext 包含以下状态:- 任何一个 OpenTracing 的实现,都需要将当前调用链的状态(例如:trace 和 span 的 id),依赖一个独特的 Span 去跨进程边界传输。
- Baggage Items: Trace 的随行数据,是一个键值对集合,它存在于 trace 中,也需要跨进程边界传输
- Jaeger简介
Jaeger 是Uber推出的一款开源分布式追踪系统,兼容OpenTracing API。
其大致架构如下:
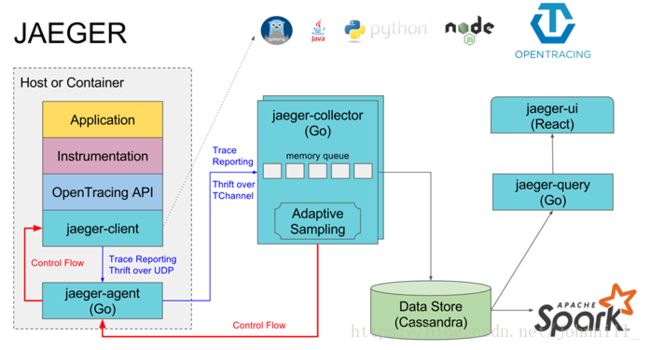
如上图所示, Jaeger主要由以下几部分组成:
- Jaeger Client: 为了不同语言实现了符合OpenTracing标准的SDK。应用程序通过API写入数据, client library把trace信息按照应用程序制定的采样策略传递给jaeger-agent。
- Agent: 他是一个监听在UDP端口上接收span数据的网络守护进程,它会将数据批量发送给collector。他被设计成一个基础组件,部署到所有的宿主机上。Agent将client library和collector解耦,为client library屏蔽了路由和发现collector的细节。
- Collector:接收jaeger-agent发送来的数据,然后将数据写入后端存储。Collector被设计成无状态的组件,因此用户可以运行任意数量的Collector。
- Data Store:后端存储被设计成一个可插拔的组件,支持数据写入cassandra, elastic search。
- Query:接收查询请求,然后从后端存储系统中检索tarce并通过UI进行展示。Query是无状态的,可以启动多个实例。把他们部署在nginx这样的负载均衡器后面。
- Agent模块
Agent初始化类图:
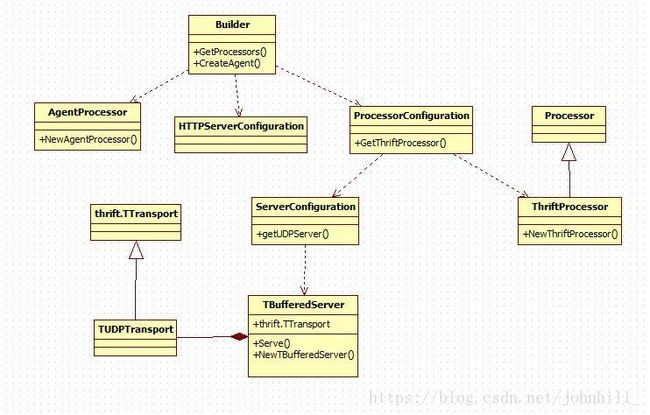
TUDPTransport:基于Thrift框架的UDP传输类。
TBufferedServer:基于TUDPTransport的UDP服务器类。
Processor:消息处理类,提供Serve和Stop两个接口。
ThriftProcessor:消息传递类,用于异步的将从UDPServer这边接收到的span消息,送至AgentProcessor处理。
AgentProcessor:根据协议区分jaeger和zipkin消息,接收并处理method为emitBatch的消息,发送至Reporter。
HTTPServerConfiguration:用于配置HTTPServer。HTTPServer用于接收Collector的HTTP配置消息,配置采样率等信息。
Agent初始化序列图:
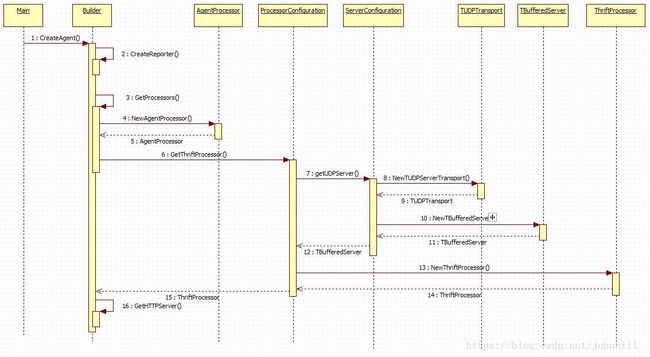
重点流程说明:
2 CreateReporter:app/builder.go 中提供createMainReporter接口,在接口中调用Builder.CreateReporter接口。CreateReporter接口在app/report/tchannel/builder.go中实现。CreateReporter接口中创建了一个tchannel类型的Reporter。
4 NewAgentProcessor:根据zipkin和jaeger两种协议类型,agent会创建各自的AgentProcessor。Jaeger类型的AgentProcessor实现在thrift-gen/agent/agent.go。得到传回的对象后作为handler传入ThriftProcessor。
7 getUDPServer:创建基于thrift的UDP服务器,并作为入参传入ThriftProcessor。
16 GetHTTPServer:创建基于HTTP的服务器,用于处理Collector下发的配置,设置采样率等信息。
Agent数据流序列图:
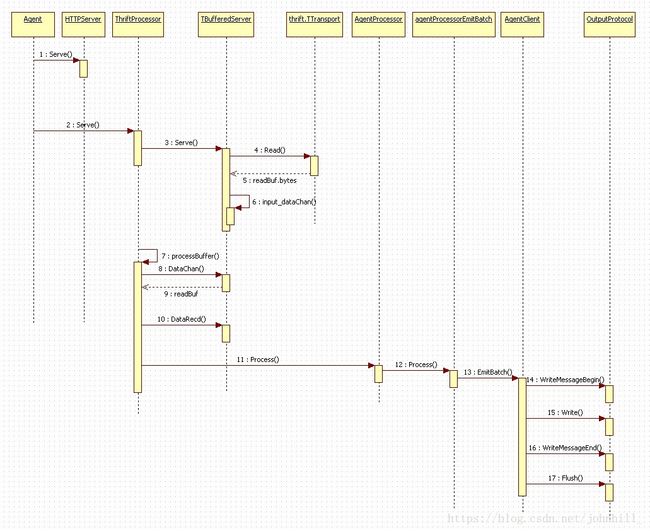
重点流程说明:
2 Serve:Agent为不同协议的ThriftProcessor创建多个协程,并调用其Serve接口。
7 processBuffer:在ThriftProcessor的Serve接口中根据配置创建多个协程用于并发处理span消息。
10 DataRecd:TBufferedServer在Buffer池的机制,避免了空间反复的new和delete。此处将用完的数据包返回TBufferedServer,以便下次接收数据时再次使用。
11 Process:ThriftProcessor将接收到的数据转换成对应的协议格式后,传递到AgentProcessor中。
12 Process:AgentProcessor解析消息Method头,如果为EmitBatch则调用对应回调进行处理。当前只支持EmitBatch消息。
综上所述,可以看出来Agent模块主要通过tchannel接收本机的UDP消息(实为span消息),再传递至thrift框架的Reporter,发送至Collector。在Agent消息处理过程中,都为二进制协议消息,非明文。Agent不对消息内容做任何修改。
- Collector模块
Collector模块初始化类图:
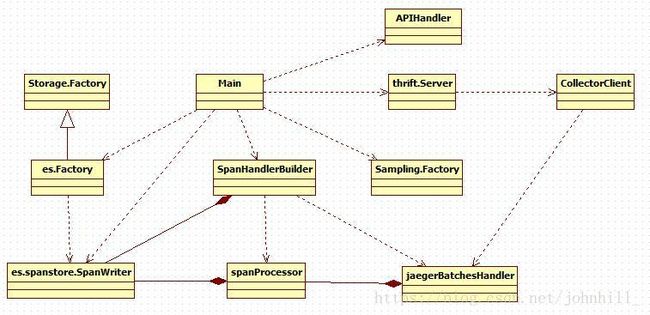
Collector模块是Jaeger分布式系统中最复杂的一个模块。
Storage.Factory:实现在plugin/storage/factory.go。基类。根据具体storage方案根提供了对应的SpanReader、SpanWriter、DependencyReader等对象的创建接口。
es.Factory:实现在plugin/storage/es/factory.go。es方案的factory实现类。
es.spanstore.SpanWriter:用于向es写入span结构化数据。
SpanHandlerBuilder:用于创建SpanHandler。默认创建zipkin和Jaeger两种协议的SpanHandler。
SpanProcessor:Span消息处理类。用于异步处理接收到的span消息。
JaegerBatchesHandler:用于从thrift服务端接收消息并转换为本地数据类型后,调用spanProcessor进行消息处理。
Sampling.Factory:用于处理采样率等配置API,并保存至本地存储。
Thrift.Server:thrift框架服务器,用于接收来自Agent的span消息。
CollectorClient:用于处理来自Agent的submitBatches消息。
APIHandler:用于处理HTTP消息。目前只支持HTTP方式的span消息。
Collector初始化序列图:
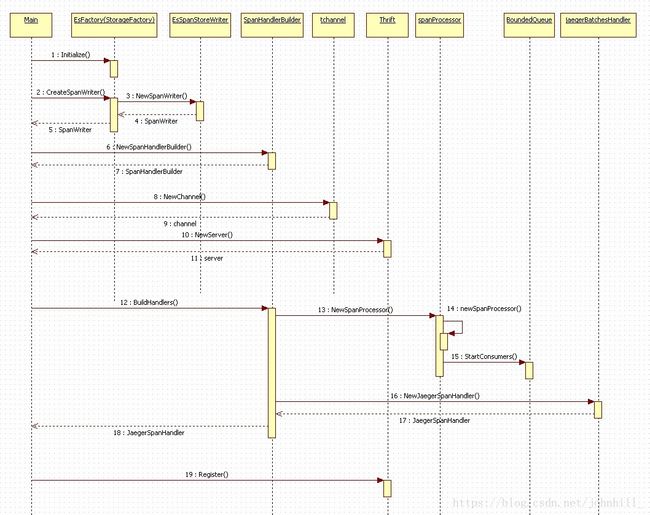
重点流程说明:
无
Collector模块数据流序列图:
由于Collector数据流处理采取异步方式,因此分两张图描述:
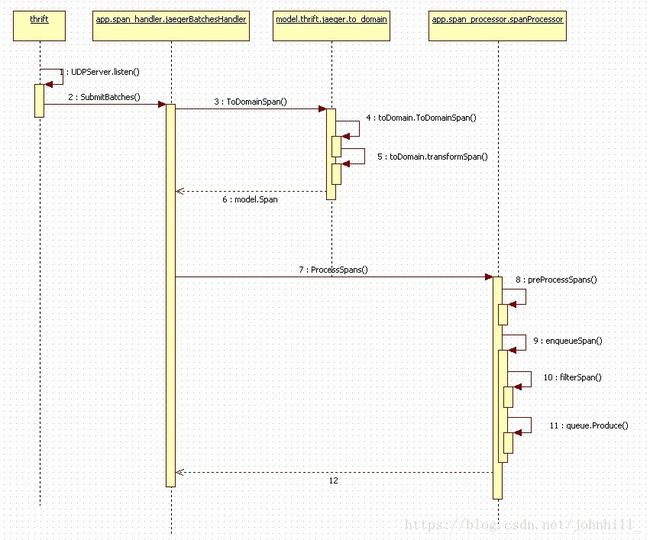
重点流程说明:
2 SubmitBatches:基于thrift的服务端接收到Batches消息后,传递至jaegerBatchesHandler处理。
3 ToDomainSpan:Handler首先将二进制数据转为本地结构化数据。
8 preProcessSpans:预处理span。可以设置对应处理函数。当前没有使用。
10 filterSpan:过滤span。可以设置对应处理函数。根据返回值判断是否需要丢弃该span消息。可以在该处理函数中进行span消息内容的修改。
11 queue.Produce:消息入队列。
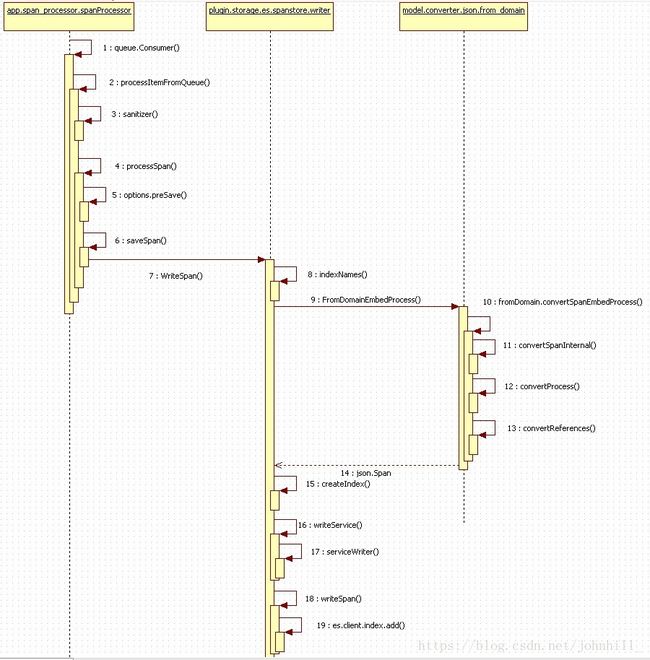
重点流程说明:
1 queue.Consumer:将队列中的span消息取出。
3 sanitizer:消息序列化,在process之前调用。Jaeger协议消息无需调用。
7 WriteSpan:根据存储方案的不同,调用对应写入接口。
14 json.Span:由于es中span的结构以json数据写入,因此将span结构转换为json。
Collector模块类似一个中转处理模块,首先将agent过来的span数据接收,并转换为本地对象。通过异步模式进行消息处理。最后将处理完毕的消息存储至对应存储模块。
- Query模块
Query模块初始化类图:
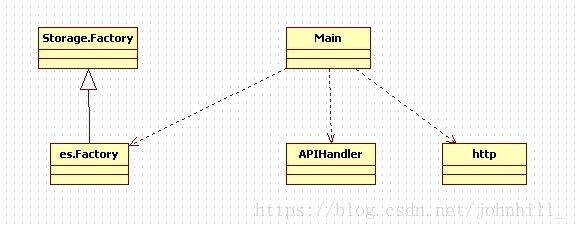
Query模块相对比较简单:
Storage.Factory:如Collector模块,Query需要初始化Storage相关模块,用于数据的读取。
APIHandler:用于消息回调。
http:处理HTTP网络请求。
Query模块初始化序列图:
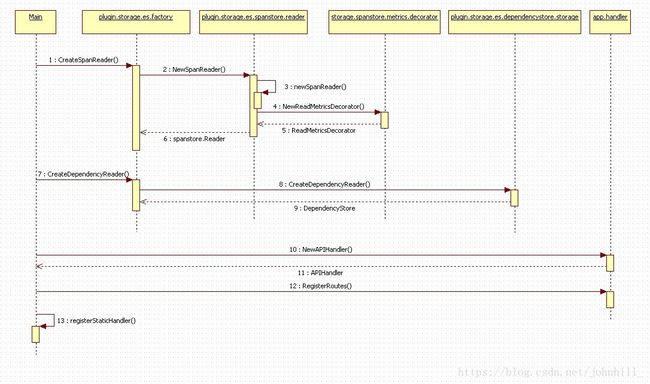
重点流程说明:
4 NewReadMetricsDecorator:此处使用了Decorator设计模式,在spanReader上封装了一层。用于调用Metric相关业务。
Query模块数据流序列图:
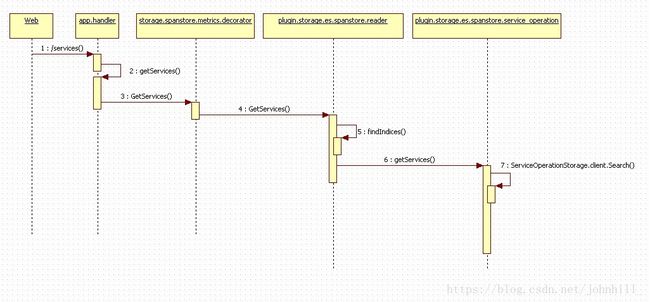
重点流程说明:
6 getService:jaeger为了更好的支持service以及对应operation的查询。在存储时,增加了一张service表。Service_operation对象就是为了专门处理该表而存在。
Query模块实现了存储的查询以及外部API调用的支持。对于API接口的定制化开发主要在该模块中实现。而在数据流程上,Query模块接收到外部api请求后,通过es api进行数据查询,并通过from_domain.go将es存储的数据结构,转化为本地数据结构。在对数据完成处理后,再通过to_domain.go完成本地数据结构到json的转化,并返回给前端。
- Dependencies模块
Dependencies模块是一个Spark任务模块,与其他几个模块不同,该模块是Java语言开发的。
该模块编译命令如下:
rm -f ./jaeger-spark-dependencies/target/*.jar;./mvnw package -Dlicense.skip=true –DskipTests
运行命令如下:
STORAGE=elasticsearch ES_NODES=http://xxx.xxx.xxx.xxx:9200 java -jar ./jaeger-spark-dependencies/target/jaeger-spark-dependencies-0.0.1-SNAPSHOT.jar
Dpendencies模块调用序列图如下:
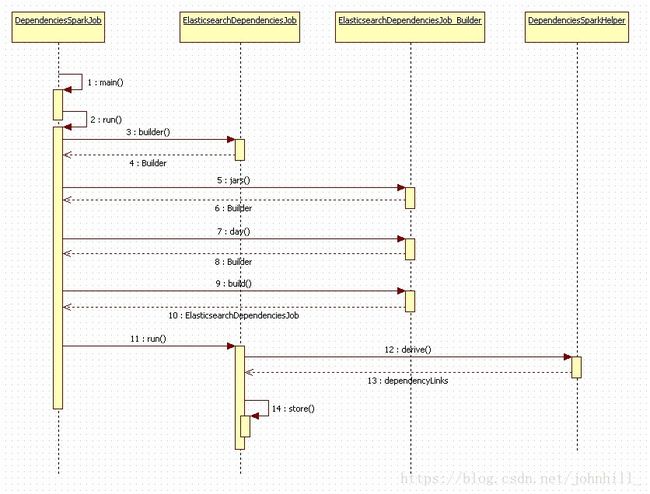
重点流程说明:
5-9:主要是初始化Spark环境变量等配置。
12:derive用于将es中span的数据结构转化为dependency数据结构。并在后续通过spark的api进行归整计算。
14:将计算后的数据结构,转换为对应的es存储的数据结构。写回es。
Dependency模块用于将固定时间段的调用依赖进行计算,以供API访问。但是方案并不太灵活。无法用于前端获取某个时间段内的调用次数。
介绍部分转载自:https://linux.cn/thread-17484-1-1.html