keras实现文本分类
数据来源自kaggle的一个比赛:data
本文从简单的文本处理模型到深度学习的LSTM模型,逐步的进行讲解。将数据下载下来后,进行数据的导入和预览。
data = pd.read_csv('data/train.csv')
data = data.loc[:1000, :]
data['target'].value_counts()
data['len'] = data['question_text'].apply(lambda x: (len(x)))
# data['len'].sort_values()读取数据后使用少量的数据,为了运行时间的原因,这里我们首先使用原始的线性回归模型进行预测。
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
train_x, val_x, train_y, val_y = train_test_split(data['question_text'], data['target'], test_size=0.2, random_state=2019)
vectorizer = CountVectorizer()
vectorizer.fit(train_x)
train_x = vectorizer.transform(train_x)
val_x = vectorizer.transform(val_x)
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(train_x, train_y)
score = classifier.score(val_x, val_y)
print('Accuracuy:', score)使用简单神经网络模型测试,模型使用全连接层,进行简单的模型分类
from keras.models import Sequential
from keras import layers
# 神经网络模型不能使用稀疏矩阵,需要转成正常的矩阵
train_x = train_x.toarray()
val_x = val_x.toarray()
input_dim = train_x.shape[1]
model = Sequential()
model.add(layers.Dense(10, input_dim=input_dim, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
history = model.fit(train_x, train_y,
epochs=100, verbose=False,
validation_data=(val_x, val_y),
batch_size=10)
loss, accuracy = model.evaluate(val_x, val_y, verbose=False)
print("Test accuracy: {:.4f}".format(accuracy))由于全连接网络不能输入稀疏矩阵,所以需要转换,模型只有第一层需要输入数据,input_dim是特征的数量即列的数量,使用model.summary函数可以输出网络的模型结构。
添加embeddings层模型测试,使用word2vec词向量,进行模型训练。
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer()
tokenizer.fit_on_texts(train_x)
train_x = tokenizer.texts_to_sequences(train_x)
val_x = tokenizer.texts_to_sequences(val_x)
vocab_size = len(tokenizer.word_index) +1
maxlen = 30
train_x = pad_sequences(train_x, padding='post', maxlen=maxlen)
val_x = pad_sequences(val_x, padding='post', maxlen=maxlen)
embedding_dim = 50
model = Sequential()
model.add(layers.Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
input_length=maxlen))
model.add(layers.Flatten())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
history = model.fit(train_x, train_y,
epochs=20,
verbose=False,
validation_data=(val_x, val_y),
batch_size=10)
loss, accuracy = model.evaluate(val_x, val_y, verbose=False)
print('Test accuracy: {:.4f}'.format(accuracy))使用layers.Flatten将Embedding的模型结构拍扁,然后再经过全连接层进行分类。
使用池化模型进行进行测试。将不使用layers.Flatten进行拍扁,使用全局的最大池化可以得倒和拍扁后的结果相同。
model = Sequential()
model.add(layers.Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
input_length=maxlen))
model.add(layers.GlobalMaxPool1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
history = model.fit(train_x, train_y,
epochs=50,
verbose=False,
validation_data=(val_x, val_y),
batch_size=10)
loss, accuracy = model.evaluate(val_x, val_y, verbose=False)
print("Test accuracy {:.4f}".format(accuracy))
我们还可以使用网上经过大量数据已经训练好的,词向量进行训练。
# 从训练好的模型中取出我们tokenizer中使用的词向量
import numpy as np
def get_coefs(word, *arr):
return word, np.asarray(arr, dtype='float32')
def load_embeddings(path):
with open(path) as f:
return dict(get_coefs(*line.strip().split(' ')) for line in f)
def build_matrix(word_index, path):
embedding_index = load_embeddings(path)
embedding_matrix = np.zeros((len(word_index) + 1, 300))
for word, i in word_index.items():
try:
embedding_matrix[i] = embedding_index[word]
except KeyError:
pass
return embedding_matrix
embedding_matrix = build_matrix(tokenizer.word_index, 'data/glove.840B.300d.txt')
# 使用已经训练好的模型权重,迭代进行训练
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim,
weights=[embedding_matrix],
input_length=maxlen,
trainable=False))
model.add(layers.GlobalMaxPool1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
history = model.fit(train_x, train_y,
epochs=50,
verbose=False,
validation_data=(val_x, val_y),
batch_size=10)
loss, accuracy = model.evaluate(val_x, val_y, verbose=False)
print("Test accuracy {:.4f}".format(accuracy))第一个注释中,我们将tokenizer中使用的词向量从glove.840B.300d.txt找出来,训练好的词向量的下载地址:地址,放到文件夹data下面。其中300d表示一个词使用300维度的向量表示。
第二个注释, vocab_size表示词向量的长度加上1, embedding_dim特征的维度,就是我们使用网上训练好的词向量,这里是300的维度,maxlen是我们填充后sequences的长度。
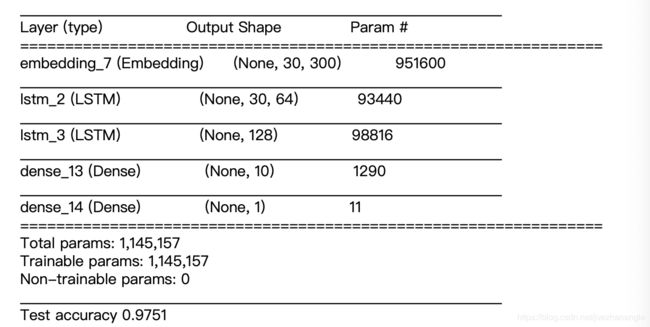
此图为summary画出来的模型结构图。