Hutool不糊涂(二)
目录
●最甜的几块糖(Part 2)
●缓存工具
●JSON工具
●加解密工具
●定时任务
●excel操作
●DFA查找
●糖吃多了有什么坏处?
●小结
●最甜的几块糖(Part 2)
接上一篇,我们继续来看看剩下的几个比较实用的类。
●缓存工具
之前笔者写过一篇利用static实现简易缓存的文章,比较功能有限,例如无法实现缓存的清理等。而Hutool为大家提供了常用的缓存工具,除了不常用到的高级功能以外,例如主从复制,基本够用了,不用额外去学习、集成以及维护第三方的缓存,例如Redis或者memcached。
Hutool提供了以下几种缓存——
1.FIFOCache(先进先出缓存)。元素不停的加入缓存直到缓存满为止,当缓存满时,清理过期缓存对象,清理后依旧满则删除先入的缓存。是用链表来实现的。适用于对加入先后敏感的业务场景,例如售货机商品上架,先放进去的商品先卖掉,这样可以保证生产日期靠前的产品不会积压;不适用于对频率敏感的业务场景,例如不能保证最常用的对象总是被保留。因此适用面比较窄。
2.LFUCache(最少使用率缓存)。当缓存满时清理过期对象,清理后依旧满的情况下清除最少访问(访问计数最小)的对象并将其他对象的访问数减去这个最小访问数,以便新对象进入后可以公平计数。适用于对频率敏感的业务场景,这比较好理解,大部分缓存的目的都是为了留下经常用的对象,不常用的就逐渐排除掉。
3.LRUCache(最久未使用缓存)。当缓存满了,最久未被使用的对象将被移除,是用LinkedHashMap实现的,当缓存对象被使用一次,就取出放入头部。适用于对使用先后敏感的业务场景,同样不适用于对频率敏感的业务场景,
4.TimedCache(定时缓存)。为缓存对象设置一个过期时间,到了就移出,与前面三种不同,没有容量限制。适用于对时间段敏感的业务场景,例如缓存交易记录的流水号,交易记录保存3个月;同样不适用于对频率敏感的业务场景。
缓存对象的构建采用统一的形式:
Long timeout = 60*DateUnit.MINUTE.getMillis();
int capacity = 10;
//构建一个FIFOCache
Cache fifoCache = CacheUtil.newFIFOCache(capacity,timeout);
//构建一个LFUCache
Cache lfuCache = CacheUtil.newLRUCache(capacity,timeout);
//构建一个LRUCache
Cache lruCache = CacheUtil.newLFUCache(capacity,timeout);
//构建一个TimedCache
Cache timedCache = CacheUtil.newTimedCache(timeout); 缓存对象的使用:
fifoCache.put("key","value");
String value = fifoCache.get("key");
//1秒后到期
fifoCache.put("key2","value2",6000);
String value2 = fifoCache.get("key2");
//获取命中次数与非命中次数
int hitCount = ((FIFOCache) fifoCache).getHitCount();
int missCount = ((FIFOCache) fifoCache).getMissCount(); ●JSON工具
现在第三方开源高效的JSON工具还是蛮多的,比如FastJSON、Gson、Jackson等。Hutool也集成了自己的JSON工具。与FastJSON类似,Hutool的JSONObject类实现了Map接口,JSONArray类实现了List接口,因此可以近乎0学习成本地使用类似FastJSON的API来操作JSON(假设你已经会使用FastJSON)。
下面我们结合代码来比较下FastJSON、Gson以及Hutool的JSON。首先我们看看三者将字符串解析为JsonObject的速度——
为了增加解析难度,我们特意采用一个复杂的Json字符串,通过Hutool的文件读取工具从txt中读取,涉及具体的业务数据,此处就不给大家展示了。
public class JsonTest {
/**
* 测试三者将字符串、Json对象、JavaBean之间相互转化的用法和性能
*/
@Test
public void test(){
System.out.println("--------------String转JsonObject----------------");
//读取Json字符串,Hutool提供的文件读取类
FileReader fileReader = new FileReader("复杂Json字符串-组织单元.txt");
String jsonStr = fileReader.readString();
//FastJson
Date fastJsonDateTimeStart = DateTime.now().toJdkDate();
JSONObject fastJsonObject = JSONObject.parseObject(jsonStr);
Date fastJsonDateTimeEnd = DateTime.now().toJdkDate();
System.out.printf("FastJson转化JsonObject耗时:%d毫秒\n",DateUtil.between(fastJsonDateTimeStart,fastJsonDateTimeEnd,DateUnit.MS));
//Gson
Date gsonDateTimeStart = DateTime.now().toJdkDate();
JsonObject gsonObject = new JsonParser().parse(jsonStr).getAsJsonObject();
Date gsonDateTimeEnd = DateTime.now().toJdkDate();
System.out.printf("Gson转化JsonObject耗时:%d毫秒\n",DateUtil.between(gsonDateTimeStart,gsonDateTimeEnd,DateUnit.MS));
//Hutool
Date hutoolJsonDateTimeStart = DateTime.now().toJdkDate();
cn.hutool.json.JSONObject hutoolJsonObject = JSONUtil.parseObj(jsonStr);
Date hutoolJsonDateTimeEnd = DateTime.now().toJdkDate();
System.out.printf("Hutool转化JsonObject耗时:%d毫秒\n",DateUtil.between(hutoolJsonDateTimeStart,hutoolJsonDateTimeEnd,DateUnit.MS));
System.out.println("--------------JsonObject转String----------------");
//FastJson
fastJsonDateTimeStart = DateTime.now().toJdkDate();
String fastJsonStr = fastJsonObject.toJSONString();
fastJsonDateTimeEnd = DateTime.now().toJdkDate();
System.out.printf("FastJson转化String耗时:%d毫秒\n",DateUtil.between(fastJsonDateTimeStart,fastJsonDateTimeEnd,DateUnit.MS));
//Gson
gsonDateTimeStart = DateTime.now().toJdkDate();
String gsonStr = new Gson().toJson(gsonObject);
gsonDateTimeEnd = DateTime.now().toJdkDate();
System.out.printf("Gson转化String耗时:%d毫秒\n",DateUtil.between(gsonDateTimeStart,gsonDateTimeEnd,DateUnit.MS));
//Hutool
hutoolJsonDateTimeStart = DateTime.now().toJdkDate();
String hutoolStr = JSONUtil.toJsonStr(hutoolJsonObject);
hutoolJsonDateTimeEnd = DateTime.now().toJdkDate();
System.out.printf("Hutool转化String耗时:%d毫秒\n",DateUtil.between(hutoolJsonDateTimeStart,hutoolJsonDateTimeEnd,DateUnit.MS));
System.out.println("--------------JsonObject转JavaBean----------------");
//FastJson
fastJsonDateTimeStart = DateTime.now().toJdkDate();
ControlUnitTreeNode fastJsonJavaBean = fastJsonObject.toJavaObject(ControlUnitTreeNode.class);
fastJsonDateTimeEnd = DateTime.now().toJdkDate();
System.out.printf("FastJson转化JavaBean耗时:%d毫秒\n",DateUtil.between(fastJsonDateTimeStart,fastJsonDateTimeEnd,DateUnit.MS));
//Gson
gsonDateTimeStart = DateTime.now().toJdkDate();
ControlUnitTreeNode gsonJavaBean = new Gson().fromJson(gsonObject,ControlUnitTreeNode.class);
gsonDateTimeEnd = DateTime.now().toJdkDate();
System.out.printf("Gson转化JavaBean耗时:%d毫秒\n",DateUtil.between(gsonDateTimeStart,gsonDateTimeEnd,DateUnit.MS));
//Hutool
hutoolJsonDateTimeStart = DateTime.now().toJdkDate();
ControlUnitTreeNode hutoolJavaBean = hutoolJsonObject.toBean(ControlUnitTreeNode.class);
hutoolJsonDateTimeEnd = DateTime.now().toJdkDate();
System.out.printf("Hutool转化JavaBean耗时:%d毫秒\n",DateUtil.between(hutoolJsonDateTimeStart,hutoolJsonDateTimeEnd,DateUnit.MS));
System.out.println("--------------JavaBean转String----------------");
//FastJson
fastJsonDateTimeStart = DateTime.now().toJdkDate();
String fastJsonString = JSONObject.toJSONString(fastJsonJavaBean);
fastJsonDateTimeEnd = DateTime.now().toJdkDate();
System.out.printf("FastJson转化String耗时:%d毫秒\n",DateUtil.between(fastJsonDateTimeStart,fastJsonDateTimeEnd,DateUnit.MS));
//Gson
gsonDateTimeStart = DateTime.now().toJdkDate();
String gsonString = new Gson().toJson(gsonJavaBean);
gsonDateTimeEnd = DateTime.now().toJdkDate();
System.out.printf("Gson转化String耗时:%d毫秒\n",DateUtil.between(gsonDateTimeStart,gsonDateTimeEnd,DateUnit.MS));
//Hutool
hutoolJsonDateTimeStart = DateTime.now().toJdkDate();
String hutoolString = JSONUtil.toJsonStr(hutoolJavaBean);
hutoolJsonDateTimeEnd = DateTime.now().toJdkDate();
System.out.printf("Hutool转化String耗时:%d毫秒\n",DateUtil.between(hutoolJsonDateTimeStart,hutoolJsonDateTimeEnd,DateUnit.MS));
}
}结果如图:
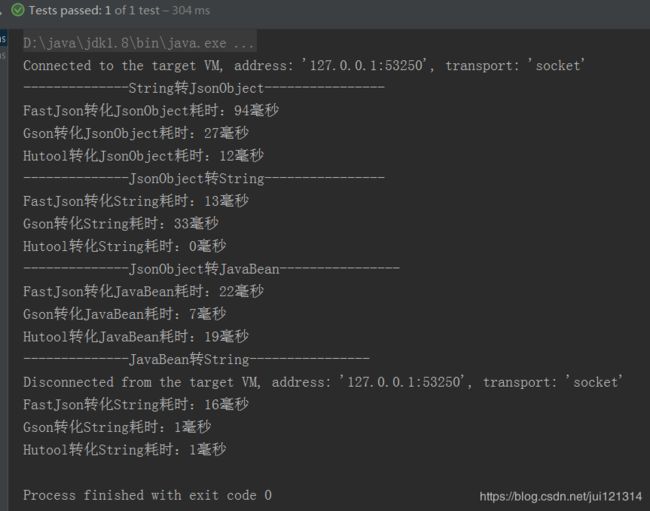
可以看出,Json字符串与JsonObeject之间的转换,Hutool提供的工具效率最高;JsonObeject与JavaBean之间的转化,Gson效率最高;JavaBean与Json字符串之间的转化Gson和Hutool效率接近。当然,这只是单条数据的比较,实验还不够严谨,但也可以反映出Hutool基于json.org官方API进行改造的JSON工具表现还是不错的。
●加解密工具
Hutool提供了常用的对称加密(例如:AES、DES等)、非对称加密(例如:RSA、DSA等)、摘要加密(例如:MD5、SHA-1、SHA-256、HMAC等)的加解密工具。
使用示例如下:
String beforeStr = "123456";
//md5加密(摘要加密)
Assert.assertEquals("e10adc3949ba59abbe56e057f20f883e",SecureUtil.md5(beforeStr));
//AES加密(对称加密)
byte[] key = SecureUtil.generateKey(SymmetricAlgorithm.AES.getValue()).getEncoded();
AES aes = SecureUtil.aes(key);
String encryptStr = aes.encryptHex(beforeStr);
String decryptStr = aes.decryptStr(encryptStr, CharsetUtil.CHARSET_UTF_8);
Assert.assertEquals(beforeStr,decryptStr);
//RSA加密(非对称加密)
RSA rsa = SecureUtil.rsa();
//签名,私钥加密,公钥解密
byte[] encrypt = rsa.encrypt(StrUtil.bytes(beforeStr, CharsetUtil.CHARSET_UTF_8), KeyType.PublicKey);
byte[] decrypt = rsa.decrypt(encrypt, KeyType.PrivateKey);
Assert.assertEquals(beforeStr, StrUtil.str(decrypt, CharsetUtil.CHARSET_UTF_8));
//加密私钥加密,公钥解密
byte[] encrypt2 = rsa.encrypt(StrUtil.bytes(beforeStr, CharsetUtil.CHARSET_UTF_8), KeyType.PrivateKey);
byte[] decrypt2 = rsa.decrypt(encrypt2, KeyType.PublicKey);
Assert.assertEquals(beforeStr, StrUtil.str(decrypt2, CharsetUtil.CHARSET_UTF_8));●定时任务
大家如果使用过定时任务的话,绝大可能用的都是quartz,但相比之下,Hutool封装的定时任务更轻量,并且也具备了常用功能,加之有Cron表达式加持,生产开发绝对没有问题。这里,给大家推荐一个Cron表达式在线生成网站http://cron.qqe2.com/,降低了学习成本。
首先,我们写一个定时任务的方法,类名方法名随意:
public class MyTask1 {
public static int count = 0;
public void start(){
System.out.printf("第%d次执行定时任务,当前时间:%s\n",++count,DateTime.now().toString());
}
}然后,需要在resources目录下config目录下(如果没有的话可自己建立)新建一个setting文件(参见Hutool的上一篇文字)cron.setting。里面配置好需要定时执行的方法以及规则,例如我们每10秒执行一次,每周一到周五执行:
# 中括号写到类所在的包,配置项写到类名和方法名
[task]
MyTask1.start = 0/10 0 0 0 0 1/5 最后,就可以启动定时任务了。这里使用了CountDownLatch阻塞观察定时任务运行结果。
public class TimerTest {
@Test
public void test() throws InterruptedException {
//设置Cron表达式匹配到秒,不然使用的是Linux的crontab表达式,最小单位是分钟
CronUtil.setMatchSecond(true);
CronUtil.start();
//可以手动停止定时任务
//CronUtil.stop();
CountDownLatch countDownLatch = new CountDownLatch(1);
countDownLatch.await();
}
}运行结果如下:
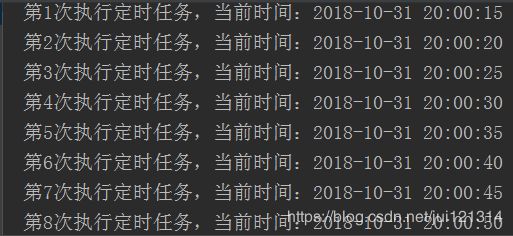
●excel操作
笔者接触的项目不少用到了Excel导入导出的功能,Hutool基于Apache的POI库进行封装,提供了简洁操作方法。值得注意的是,此处需要在pom文件中引入Apache POI的依赖,这也是Hutool少数需要引入第三方依赖的地方,这是考虑并非所有Java项目都会用到Excel操作,只有特定统计业务会用到,为了轻量,不主动引入的。
引入的内容如下:
org.apache.poi
poi-ooxml
3.17
pom
我们通过代码来看看具体怎么使用。首先准备一个JavaBean,字段对应excel中的每条记录:
public class CarInfo {
private String plateNo;
private String laneName;
private String driveway;
private String direction;
private String plateType;
private String uploadTime;
private int speed;
private double carLength;
private String plateColor;
private String carColor;
private String carType;
private String carColorDeepth;
private String brand;
private String subBrand;
private String productYear;
/* 篇幅原因,省略掉构造函数和get、set函数 */
}excel读取和写入支持xls和xlsx两种格式,看看待读取的文件:

使用Hutool封装好的API进行读写操作:
public class ExcelTest {
@Test
public void test(){
//默认读全部行列,还可以通过重载函数,第二个参数指定读取的Sheet
ExcelReader reader1 = ExcelUtil.getReader("车辆信息xlsx.xlsx");
//设置标题别名的目的在于读取的excel标题是中文,一一对应上javabean中的字段。如果excel标题就是字段名,则无需设置别名
reader1.addHeaderAlias("车牌号码","plateNo")
.addHeaderAlias("路口名称","laneName")
.addHeaderAlias("车道","driveway")
.addHeaderAlias("方向","direction")
.addHeaderAlias("车牌类型","plateType")
.addHeaderAlias("过车时间","uploadTime")
.addHeaderAlias("车速(km/h)","speed")
.addHeaderAlias("车长(m)","carLength")
.addHeaderAlias("车牌颜色","plateColor")
.addHeaderAlias("车身颜色","carColor")
.addHeaderAlias("车辆类型","carType")
.addHeaderAlias("车辆颜色深浅","carColorDeepth")
.addHeaderAlias("车辆品牌","brand")
.addHeaderAlias("车辆子品牌","subBrand")
.addHeaderAlias("车辆年款","productYear");
List carInfosByXlsx = reader1.readAll(CarInfo.class);
reader1.close();
//也兼容xls格式
ExcelReader reader2 = ExcelUtil.getReader("车辆信息xls.xls");
reader2.addHeaderAlias("车牌号码","plateNo")
.addHeaderAlias("路口名称","laneName")
.addHeaderAlias("车道","driveway")
.addHeaderAlias("方向","direction")
.addHeaderAlias("车牌类型","plateType")
.addHeaderAlias("过车时间","uploadTime")
.addHeaderAlias("车速(km/h)","speed")
.addHeaderAlias("车长(m)","carLength")
.addHeaderAlias("车牌颜色","plateColor")
.addHeaderAlias("车身颜色","carColor")
.addHeaderAlias("车辆类型","carType")
.addHeaderAlias("车辆颜色深浅","carColorDeepth")
.addHeaderAlias("车辆品牌","brand")
.addHeaderAlias("车辆子品牌","subBrand")
.addHeaderAlias("车辆年款","productYear");
List carInfosByXls = reader2.readAll(CarInfo.class);
reader2.close();
//excel的写出
List row0 = CollUtil.newArrayList("车牌", "颜色", "速度", "车长");
List row1 = CollUtil.newArrayList("浙A54122", "红色", "52", "3.1");
List row2 = CollUtil.newArrayList("浙A10122", "黑色", "60", "3.4");
List row3 = CollUtil.newArrayList("浙A12574", "黑色", "50", "3.35");
List row4 = CollUtil.newArrayList("浙A24762", "蓝色", "55", "3.2");
List row5 = CollUtil.newArrayList("浙A99884", "白色", "58", "3.1");
List> rows = CollUtil.newArrayList(row0,row1, row2, row3, row4, row5);
ExcelWriter writer = ExcelUtil.getWriter("toXls.xls");
//设置sheet名
writer.renameSheet("车辆信息摘要表");
writer.write(rows);
writer.close();
}
} ●DFA查找
最后给大家介绍一个关键词/敏感词查找的方案,DFA(Deterministic Finite Automaton,确定有穷自动机)算法,用所有关键字构造一棵树,然后用正文遍历这棵树,遍历到叶子节点即表示文章中存在这个关键字。相比使用集合的遍历,速度会快很多。
我们假设有这么一个业务场景,需要去查询用户发帖是否含有关键词,如果有,则不让其发帖。我们通过读取一个txt文件来模拟用户发的帖子,主要针对关键词查找做一个演示:
public class DFATest {
@Test
public void dfaTest(){
//构造关键词树
WordTree tree = new WordTree();
tree.addWord("阿里");
tree.addWord("腾讯");
tree.addWord("百度");
tree.addWord("苹果");
//读取txt,模拟发帖
FileReader fileReader = new FileReader("hutoolAPI.txt");
String text1 = fileReader.readString();
fileReader = new FileReader("智能化软件开发:程序员与 AI 机器人一起结对编程.txt");
String text2 = fileReader.readString();
fileReader = new FileReader("自动驾驶,或许是秋天,还没到冬天.txt");
String text3 = fileReader.readString();
//DFA关键词匹配
boolean isMatch1 = tree.isMatch(text1);
boolean isMatch2 = tree.isMatch(text2);
boolean isMatch3 = tree.isMatch(text3);
//DFA关键词查找
List matchAll1 = tree.matchAll(text1, -1, true, true);
System.out.printf("匹配到%d个关键词\n",matchAll1.size());
List matchAll2 = tree.matchAll(text2, -1, true, true);
System.out.printf("匹配到%d个关键词\n",matchAll2.size());
List matchAll3 = tree.matchAll(text3, -1, true, true);
System.out.printf("匹配到%d个关键词\n",matchAll3.size());
//与正则表达式匹配过程耗时对比
DateTime start1 = DateTime.now();
List matchByDFA = tree.matchAll(text1, -1, true, true);
DateTime end1 = DateTime.now();
System.out.printf("DFA匹配到%d个关键词,耗时:%d毫秒\n",matchByDFA.size(), DateUtil.between(start1.toJdkDate(),end1.toJdkDate(),DateUnit.MS));
Pattern pattern=Pattern.compile("(.*阿里.*)|(.*腾讯.*)|(.*百度.*)|(.*苹果.*)");
DateTime start2 = DateTime.now();
Matcher matcher= pattern.matcher(text1);
List matchByReg = new ArrayList<>();
while(matcher.find()){
matchByReg.add(matcher.group());
}
DateTime end2 = DateTime.now();
System.out.printf("正则表达式匹配到%d个关键词,耗时:%d毫秒", matchByReg.size(),DateUtil.between(start2.toJdkDate(),end2.toJdkDate(),DateUnit.MS));
}
} 结果如下:
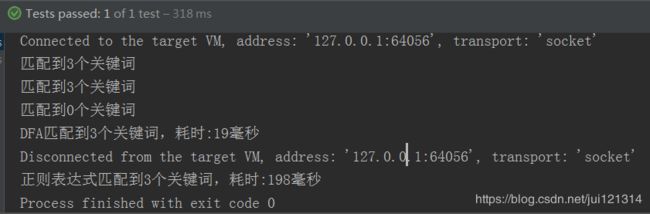
可以看到,使用DFA比使用正则表达式去做匹配效率更高,特别适用于匹配的原文很大,关键词很多的情况。当然了,可以结合业务需要,匹配出关键词后,将其替换为*,再发帖。
●糖吃多了有什么坏处?
之前一直在说Hutool提供的语法糖的好处——极大提高编程效率,但是回过头来说,如果一直吃糖,很可能导致离开了它就无法编码了,例如前面大量举例使用的传统写法,很可能就会变得手生了。这种情况不只是语法糖的问题,许多框架也存在。随着技术的发展,封装越来越好,程序员已经不需要太了解底层实现就可以直接调用API实现功能,就像springboot,通过官方网站生成工程项目,下载拿来直接就可以用,用惯了可能就不会以前SSH、SSM框架的配置了。希望大家能辩证地看待问题,在合理的范围最大程度去利用好手边的工具。
●小结
以上,对于Hutool的介绍基本就到一段落了,还是很推荐大家使用这个Apache2.0开源协议的工具的,商业许可安全。今后,笔者将继续为大家推荐一些高效有趣的开发工具。今天,你学会了吗?