hadoop 2.5.2 完全分布式集群环境搭建 (1)
经过一番艰辛的过程,搭建好hadoop2.5.2的完全分布式集群环境,本文描述环境的搭建,后续文章将描述开发环境及HDFS API 及MapReduce例程编写及运行过程,转载请注明出处(http://blog.csdn.net/kylindai/article/details/46584637)
1. 环境及软件包
(1) 操作系统 Centos-7-x86_64
(2) hadoop-2.5.2.tar.gz
(3) zookeeper-3.4.6.tar.gz
(4) jdk-7u80-linux-x64.gz
安装包的获取请自行百度google
如果是用虚拟机安装,网络设置如下,这样设置的目的是虚拟机的IP可以不变:
第一块网卡:仅主机(host-only)网络
第二块网卡:网络地址转换(NAT)
2. 集群规划
2.1 hosts
192.168.184.201 hadoop01
192.168.184.202 hadoop02
192.168.184.203 hadoop03 zookeeper01
192.168.184.204 hadoop04 zookeeper02
192.168.184.205 hadoop05 zookeeper03
192.168.184.206 hadoop06
2.2 节点及进程
| host | server | process | |
|---|---|---|---|
| hadoop01 | hadoop | NameNode, DFSZKFailoverController | |
| hadoop02 | hadoop | NameNode, DFSZKFailoverController | |
| hadoop03 | hadoop | zookeeper | ResourceManager, QuorumPeerMain |
| hadoop04 | hadoop | zookeeper | DataNode, NodeManager, JournalNode, QuorumPeerMain |
| hadoop05 | hadoop | zookeeper | DataNode, NodeManager, JournalNode, QuorumPeerMain |
| hadoop06 | hadoop | DataNode, NodeManager, JournalNode |
说明:
(1) NameNode 为hadoop名称节点进程
(2) DataNode 为hadoop数据节点进程
(3) JournalNode 为hadoop名称节点数据同步进程
(4) QuorumPeerMain 为zookeeper进程
(5) ResourceManager 为yarn master节点进程
(6) NodeManager 为yarn slave节点进程
3. 服务器安装
3.1 安装CentOS 7
最小化安装即可,安装好6台服务器后,每台都需要进行下面的操作,以节点1为例:
3.1.1 设置主机名
CentOS7 采用第 2 种方法即可
(1) 修改文件:/etc/sysconfig/network,添加内容
NETWORKING=yes
HOSTNAME=hadoop01(2) 修改文件:/etc/hostname,添加内容
hadoop013.1.2 设置IP地址:
(1) 修改文件:/etc/sysconfig/network-scripts/ifcfg-enp03
HWADDR=08:00:27:A8:18:60
TYPE=Ethernet
#BOOTPROTO=dhcp
#DEFROUTE=yes
#PEERDNS=yes
#PEERROUTES=yes
#IPV4_FAILURE_FATAL=no
#IPV6INIT=yes
#IPV6_AUTOCONF=yes
#IPV6_DEFROUTE=yes
#IPV6_PEERDNS=yes
#IPV6_PEERROUTES=yes
#IPV6_FAILURE_FATAL=no
NAME=enp0s3
UUID=9ec34c3e-d064-484a-9de0-1b3843565d23
ONBOOT=yes
IPADDR=192.168.184.201
NETMASK=255.255.255.0
BROADCAST=192.168.184.255
GATEWAY=192.168.184.1(2) 启动网络服务:
# service network restart(3) 检查服务状态
# chkconfig --list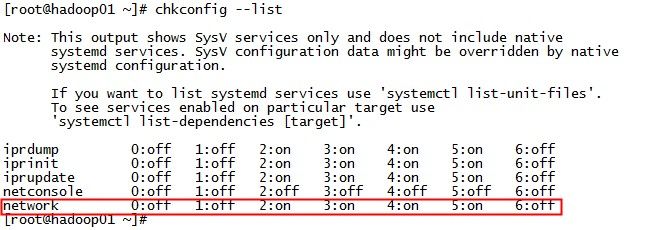
红框内容说明服务正常启动
3.1.3 关闭防火墙
这一步很重要,注意CentOS 7 默认不使用iptables作为防火墙,而是使用新的 firewalld 服务,上图中也看不到 iptables 服务
# systemctl stop firewalld.service
# systemctl disable firewalld.service3.1.4 设置ssh免登陆
(1) 在各节点上生成 ssh key 文件
# ssh-keygen -t rsa一路回车,在/root/.ssh 下可看到生成了私钥和公钥 id_rsa 和 id_rsa.pub 2个文件
(2) 设置本地免登陆,使用命令:
# ssh-copy-id -i hadoop01
# ssh-copy-id -i hadoop02
# ssh-copy-id -i hadoop03
# ssh-copy-id -i hadoop04
# ssh-copy-id -i hadoop05
# ssh-copy-id -i hadoop06也可以将各节点的公钥文件 id_rsa.pub 复制到一个文件 authorized_keys,然后将这个文件拷贝到各节点上
# scp authorized_keys hadoop02:/root/.ssh
# scp authorized_keys hadoop03:/root/.ssh
# scp authorized_keys hadoop04:/root/.ssh
# scp authorized_keys hadoop05:/root/.ssh
# scp authorized_keys hadoop05:/root/.ssh并将known_hosts 文件也复制到各节点上
# scp known_hosts hadoop02:/root/.ssh
# scp known_hosts hadoop03:/root/.ssh
# scp known_hosts hadoop04:/root/.ssh
# scp known_hosts hadoop05:/root/.ssh
# scp known_hosts hadoop06:/root/.ssh3.1.5 设置时间同步
安装 ntpd & ntpdate
# yum install ntp
# yum install nptdate安装好后,将ntpdate复制到其他节点上
# scp /usr/sbin/ntpdate hadoop02:/usr/sbin
# scp /usr/sbin/ntpdate hadoop03:/usr/sbin
# scp /usr/sbin/ntpdate hadoop04:/usr/sbin
# scp /usr/sbin/ntpdate hadoop05:/usr/sbin
# scp /usr/sbin/ntpdate hadoop06:/usr/sbin在 hadoop01上与time.nist.gov同步时间,并将时钟写入硬件,再启动时间同步服务 ntpd
# ntpdate time.nist.gov
# hwclock -w
# systemct start ntpd接下来在其他各节点上同步 hadoop01的时间
# ntpdate hadoop014. 安装JDK 7
4.1 安装JDK
解压 jdk 到 /opt 下,并做 /usr/local/java 链接,以后环境变量 JAVA_HOME 指向 /usr/local/java 方便以后 jdk 升级
# tar xvfz jdk-7u80-linux-x64.gz -C /opt
# ln -s /opt/jdk1.7.0_80 /usr/local/java如图:
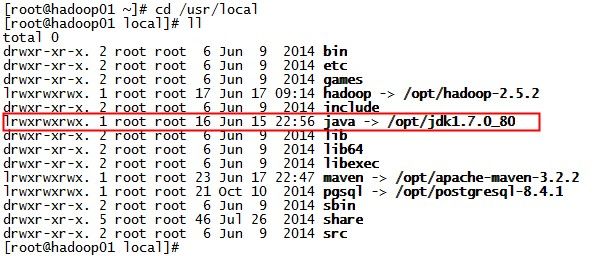
4.2 复制JDK到其他节点
# scp -r /opt/jdk1.7.0_80 hadoop02:/opt
# scp -r /opt/jdk1.7.0_80 hadoop03:/opt
# scp -r /opt/jdk1.7.0_80 hadoop04:/opt
# scp -r /opt/jdk1.7.0_80 hadoop05:/opt
# scp -r /opt/jdk1.7.0_80 hadoop06:/opt并分别做好各节点的软连接
4.3 配置环境变量
修改 /etc/profile 文件,添加如下内容:
JAVA_HOME = /usr/local/java
CLASSPATH = $JAVA_HOME/lib:.
ZOOKEEPER_HOME = /usr/local/zookeeper
HADOOP_HOME = /usr/local/hadoop
PATH = $JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH这里我们也添加了zookeeper和hadoop相关的环境变量,后面会用到,修改完后执行如下命令使之生效
# source /etc/profile4.4 复制环境变量文件到其他节点
# scp /etc/profile hadoop02:/etc
# scp /etc/profile hadoop03:/etc
# scp /etc/profile hadoop04:/etc
# scp /etc/profile hadoop05:/etc
# scp /etc/profile hadoop06:/etc复制完后,分别在各节点上使之生效,方法是
# source /etc/profile好,至此基础环境就安装好了,下篇文章描述,安装 zookeep 和 hadoop