yolo 学习系列(三):训练参数与网络参数
yolo 学习系列(三):训练参数与网络参数
手把手教你做目标检测(YOLO、SSD)视频链接
1 训练参数
博主在使用 yolov2-tiny-voc 训练 人 这一类目标物体时,训练过程中在终端输出的参数如图所示,了解这些参数的含义有助于了解训练过程中的训练效果。

1.1 训练参数解释
- Region Avg IOU: 0.196824:表示在当前subdivision内的图片的平均IOU,代表预测的矩形框和真实目标的交集与并集之比,这里是19.68%,这个模型需要进一步的训练
- Class: 1.000000: 标注物体分类的正确率,期望该值趋近于1
- Obj: 0.336143: 越接近1越好
- No Obj: 0.482397: 期望该值越来越小,但不为零
- Avg Recall: 0.00000: 是在recall/count中定义的,是当前模型在所有subdivision图片中检测出的正样本与实际的正样本的比值
- count: 2:count后的值是所有的当前subdivision图片(本例中为1张)中包含正样本的图片的数量
Region Avg IOU:平均的IOU,代表预测的bounding box和ground truth的交集与并集之比,期望该值趋近于1。
Class:是标注物体的概率,期望该值趋近于1.
Obj:期望该值趋近于1.
No Obj:期望该值越来越小但不为零.
Avg Recall:期望该值趋近1
avg:平均损失,期望该值趋近于0
1.2 IOU(Intersection over Union, 交并集之比)
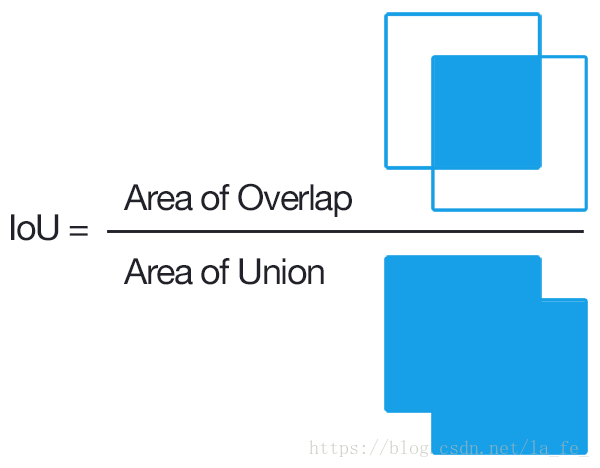
可以看到,IOU(交集比并集)是一个衡量我们的模型检测特定的目标好坏的重要指标。100%表示我们拥有了一个完美的检测,即我们的矩形框跟目标完美重合。很明显,我们需要优化这个参数。
2 cfg文件配置参数
参考这篇
还有这篇
2.1 开头部分
[net]
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=2
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
max_batches = 40200
policy=steps
steps=-1,100,20000,30000
scales=.1,10,.1,.1
- batch:每次迭代要进行训练的图片数量
- subdivision:batch中的图片再产生子集,源码中的图片数量int imgs = net.batch * net.subdivisions * ngpus
本例以上两个参数均为1,也就是说每轮迭代会从所有训练集里随机抽取 batch = 1 个样本参与训练,所有这些 batch 个样本又被均分为 subdivision =1 次送入网络参与训练,以减轻内存占用的压力
- width:输入图片宽度, height:输入图片高度,channels :输入图片通道数
对于每次迭代训练,YOLOv2会基于角度(angle),饱和度(saturation),曝光(exposure),色调(hue)产生新的训练图片
- angle:图片角度变化,单位为度,假如 angle=5,就是生成新图片的时候随机旋转-5~5度
- weight decay:权值衰减
防止过拟合,当网络逐渐过拟合时网络权值往往会变大,因此,为了避免过拟合,在每次迭代过程中以某个小因子降低每个权值,也等效于给误差函数添加一个惩罚项,常用的惩罚项是所有权重的平方乘以一个衰减常量之和。权值衰减惩罚项使得权值收敛到较小的绝对值。
- angle:图片角度变化,单位为度,假如 angle=5,就是生成新图片的时候随机旋转-5~5度
- saturation & exposure: 饱和度与曝光变化大小,tiny-yolo-voc.cfg中1到1.5倍,以及1/1.5~1倍
- hue:色调变化范围,tiny-yolo-voc.cfg中-0.1~0.1
- max_batches:最大迭代次数
- learning rate:学习率
学习率决定了参数移动到最优值的速度快慢,如果学习率过大,很可能会越过最优值导致函数无法收敛,甚至发散;反之,如果学习率过小,优化的效率可能过低,算法长时间无法收敛,也易使算法陷入局部最优(非凸函数不能保证达到全局最优)。合适的学习率应该是在保证收敛的前提下,能尽快收敛。
设置较好的learning rate,需要不断尝试。在一开始的时候,可以将其设大一点,这样可以使weights快一点发生改变,在迭代一定的epochs之后人工减小学习率。
- policy:调整学习率的策略
调整学习率的policy,有如下policy:CONSTANT, STEP, EXP, POLY,STEPS, SIG, RANDOM
- steps:学习率变化时的迭代次数
根据batch_num调整学习率,若steps=100,20000,30000,则在迭代100次,20000次,30000次时学习率发生变化,该参数与policy中的steps对应
- scales:学习率变化的比率
相对于当前学习率的变化比率,累计相乘,与steps中的参数个数保持一致
#####2.2 中间部分
[convolutional] # 卷积层
batch_normalize=1 # 是否做BN
filters=16 # 输出特征图的数量
size=3 # 卷积核的尺寸
stride=1 # 做卷积运算的步长
pad=1 # 如果pad为0,padding由 padding参数指定。
如果pad为1,padding大小为size/2,padding应该是对输入图像左边缘拓展的像素数量
activation=leaky # 激活函数的类型
[maxpool] # 池化层
size=2
stride=2
2.3 结束部分
[convolutional]
size=1
stride=1
pad=1
# filters=125
filters=30 # 计算公式 = 5 × ( 类别数 + 5 )
activation=linear
[region]
anchors = 1.08,1.19, 3.42,4.41, 6.63,11.38, 9.42,5.11, 16.62,10.52
bias_match=1 # 计算best IOU时,预测宽高强制与anchors一致
# classes=20
classes=1 # 类别数量
coords=4
num=5 # 每个grid预测的BoundingBox个数
softmax=1 # 使用softmax
jitter=.2 # 通过抖动增加噪声来抑制过拟合
rescore=1
object_scale=5
noobject_scale=1
class_scale=1
coord_scale=1
absolute=1
thresh = .6
random=1
- anchors
预测框的初始宽高,第一个是w,第二个是h,总数量是num*2,YOLOv2作者说anchors是使用K-MEANS获得,其实就是计算出哪种类型的框比较多,可以增加收敛速度,如果不设置anchors,默认是0.5,还有就是anchors读入参数中名字是biases
- bias_match
如果为1,计算best iou时,预测宽高强制与anchors一致
- coords:BoundingBox的tx,ty,tw,th
tx与ty是相对于左上角的gird,同时是当前grid的比例,tw与th是宽度与高度取对数
- jitter:通过抖动增加噪声来抑制过拟合
YOLOv2中使用的是crop,filp,以及net层的angle,flip是随机的,crop就是jitter的参数,tiny-yolo-voc.cfg中jitter=.2,就是在0~0.2中进行crop
- rescore:决定使用哪种方式计算IOU的误差
为1时,使用当前best iou计算,为0时,使用1计算
- object_scale & noobject_scale & class_scale & coord_scale
YOLOv1论文中cost function的权重,哪一个更大,每一次更新权重的时候,对应方面的权重更新相对比重更大
- thresh:决定是否需要计算IOU误差的参数
大于thresh,IOU误差不会夹在cost function中
- random
random为1时会启用Multi-Scale Training,随机使用不同尺寸的图片进行训练,如果为0,每次训练大小与输入大小一致;