知识图谱构建技术一览
知识图谱构建技术一览
- 一、什么是知识图谱
- 二、知识图谱的分层架构
- 三、知识图谱构架技术
- (一)数据获取(Data Acquisition)
- (二)信息抽取(Information Extraction)
- (1)实体抽取(Entity Extraction)/命名实体识别(Name Entity Recognition)
- (2)关系抽取(Relation Extraction)
- (3)属性抽取(Attribute Extraction)
- (三)知识融合(Knowledge Fusion)
- (1)指代消解(Coreference Resolution)
- (2)实体消歧(Entity Disambiguation)
- (3)实体链接(Entity Linking)
- (4)知识合并
- (四)知识加工(Knowledge Processing)
- (1)本体(Ontology)
- 本体的概念
- 本体 VS 知识图谱 VS 知识地图
- (2)本体构建(Ontology Extraction)
- (3)知识推理(Knowledge Inference)
- (4)质量评估(Quality Evaluation)
- 三、Reference
一、什么是知识图谱
知识图谱(Knowledge graph)首先是由Google提出来的,大家知道Google是做搜索引擎的,知识图谱出现之前,我们使用google、百度进行搜索的时候,搜索的结果是一堆网页,我们会根据搜索结果的网页题目再点击链接,才能看到具体内容,2012年google提出Google Knowldge Graph之后,利用知识图谱技术改善了搜索引擎核心,表现出来的效果就是我们现在使用搜索引擎进行搜索的时候,搜索结果会以一定的组织结构呈现。
辛格尔博士对知识图谱的介绍很简短:things,not string。这抓住了知识图谱的核心,也点出了知识图谱加入之后搜索发生的变化,以前的搜索,都是将要搜索的内容看作字符串,结果是和字符串进行匹配,将匹配程度高的排在前面,后面按照匹配度依次显示。利用知识图谱之后,将搜索的内容不再看作字符串,而是看作客观世界的事物,也就是一个个的个体。搜索比尔盖茨的时候,搜索引擎不是搜索“比尔盖茨”这个字符串,而是搜索比尔盖茨这个人,围绕比尔盖茨这个人,展示与他相关的人和事,左侧百科会把比尔盖茨的主要情况列举出来,右侧显示比尔盖茨的微软产品和与他类似的人,主要是一些IT行业的创始人。一个搜索结果页面就把和比尔盖茨的基本情况和他的主要关系都列出来了,搜索的人很容易找到自己感兴趣的结果。
查找关于知识图谱的资料,可以找到不少的相关定义:
引用维基百科的定义:
The Knowledge Graph is a knowledge base used by Google and its services to enhance its search engine’s results with information gathered from a variety of sources.
译:知识图谱是谷歌及其提供的服务所使用的知识库,目的是通过从各种来源收集信息来增强其搜索结果的展示。
引用百度百科的定义:
知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。
引用学术/学位论文的定义:
知识图谱,是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是“实体—关系—实体”三元组,以及实体及其相关属性—值对,实体间通过关系相互联结,构成网状的知识结构。(刘峤, 李杨, 段宏, 等. 知识图谱构建技术综述[J]. 计算机研究与发展, 2016, 53(3): 582-600.)
知识图谱就是展示知识发展过程与属性联系的一系列不同图形,再加以相应的可视化手段把这一系列图形表示的这些知识实体与知识实体或者知识实体与知识属性之间的联系展示出来。知识图谱的本质就是一种网状知识库,它是由一个个知识三元组组成。目前知识三元组的形式有两种,分别是<实体1,关系,实体2>和<实体1,属性1,属性值>。例如在本文所选的铁路领域内,这两种知识三元组分别可以是<中国铁路呼和浩特局集团公司,管辖,集宁机务段>,<东风 4B 型内燃机车,设计时速,120km/h>(客运型)和<东风 4B 型内燃机车,设计时速,100km/h>(货运型)。(学位论文:基于铁路领域的知识图谱研究与实现)
引用著作的定义:
知识图谱是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法。知识图谱由节点和边组成。节点可以是实体,如一个人、一本书等,或是抽象的概念,如人工智能、知识图谱等。边可以是实体的属性,如姓名、书名或是实体之间的关系,如朋友、配偶。知识图谱的早期理念来自Semantic Web(语义网络),其最初理想是把基于文本链接的万维网落转化为基于实体链接的语义网络。(王昊奋,知识图谱 方法、实践与应用)
引用互联网博客的解释:
知识图谱:是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系。(链接:通俗易懂解释知识图谱)
知识图谱本质上是语义网络(Semantic Network)的知识库.。(链接:这是一份通俗易懂的知识图谱技术与应用指南)
总的来说,知识图谱本质上是一种语义网络,用图的形式描述客观事物,这里的图指的是数据结构中的图,也就是由节点和边组成的,这也是知识图谱(Knowledge Graph)的真实含义。知识图谱中的节点表示概念和实体,概念是抽象出来的事物,实体是具体的事物;边表示事物的关系和属性,事物的内部特征用属性来表示,外部联系用关系来表示。很多时候,人们简化了对知识图谱的描述,将实体和概念统称为实体,将关系和属性统称为关系,这样就可以说知识图谱就是描述实体以及实体之间的关系。实体可以是人,地方,组织机构,概念等等,关系的种类更多,可以是人与人之间的关系,人与组织之间的关系,概念与某个物体之间的关系等等。
知识图谱是由实体和实体的关系组成,通过图的形式表现出来,那么实体和实体关系的这些数据在知识图谱中怎么组织呢,这就涉及到三元组的概念,在知识图谱中,节点-边-节点可以看作一条记录,第一个节点看作主语,边看作谓语,第二个节点看作宾语,主谓宾构成一条记录。比如曹操的儿子是曹丕,曹操是主语,儿子是谓语,曹丕是宾语。再比如,曹操的小名是阿瞒,主语是曹操,谓语是小名,宾语是阿瞒。知识图谱就是由这样的一条条三元组构成,围绕着一个主语,可以有很多的关系呈现,随着知识的不断积累,最终会形成一个庞大的知识图谱,知识图谱建设完成后,会包含海量的数据,内涵丰富的知识。
知识图谱构建完成之后,主要用在哪些地方,比较典型应用是语义搜索、智能问答、推荐系统等方面。知识图谱是一个具有本体特征的语义网络,可以看成是按照本体模式组织数据的知识库,以知识图谱为基础进行搜索,可以根据查询的内容进行语义搜索,查找需要找的本体或者本体的信息,这种语义搜索功能在google、百度、阿里巴巴等数据量大的公司里得到应用。智能问答,和语义搜索类似,对于提问内容,计算机首先要分析提问问题的语义,然后再将语义转换为查询语句,到知识图谱中查找,将最贴近的答案提供给提问者。推荐系统首先要采集用户的需求,分析用户的以往数据,提取共同特征,然后根据一定的规则,对用户提供推荐的产品。比如淘宝中记录用户经常购买的商品,经常浏览的商品,提取这些商品的共同特征,然后给这个用户打上标签,然后就给用户推荐具有类似特征的商品。
知识图谱主要反映的事物之间的关系,对于和关系链条有关的场景,也可以用知识图谱解决,一些应用场景包括反欺诈、不一致性验证、异常分析、客户管理等
二、知识图谱的分层架构
知识图谱由数据层(data layer)和模式层(schema layer)构成。
模式层是知识图谱的概念模型和逻辑基础,对数据层进行规范约束. 多采用本体作为知识图谱的模式层,借助本体定义的规则和公理约束知识图谱的数据层。也可将知识图谱视为实例化了的本体,知识图谱的数据层是本体的实例。如果不需支持推理, 则知识图谱(大多是自底向上构建的) 可以只有数据层而没有模式层。在知识图谱的模式层,节点表示本体概念,边表示概念间的关系。
在数据层, 事实以“实体-关系-实体”或“实体-属性-属性值”的三元组存储,形成一个图状知识库. 其中,实体是知识图谱的基本元素,指具体的人名、组织机构名、地名、日期、时间等。关系是两个实体之间的语义关系,是模式层所定义关系的实例。属性是对实体的说明,是实体与属性值之间的映射关系。属性可视为实体与属性值之间的 hasValue 关系,从而也转化为以“实体-关系-实体”的三元组存储。在知识图谱的数据层,节点表示实体,边表示实体间关系或实体的属性。
三、知识图谱构架技术
根据上述的知识图谱分层结构,知识图谱的构建方法主要有两种:一种是自底而上的构建方法(如下图所示);一种是自定而下的构建方法。
自底向上的构建方法流程如下图所示,从开放链接的数据源中提取实体、属性和关系,加入到知识图谱的数据层;然后将这些知识要素进行归纳组织,逐步往上抽象为概念,最后形成模式层。自顶而下的方法正好相反。
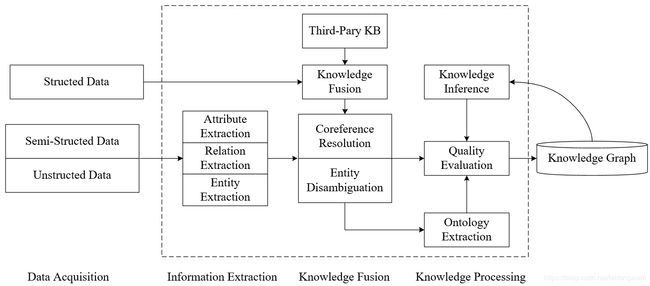
知识图谱技术架构图如上所示,其对应中文版如下:
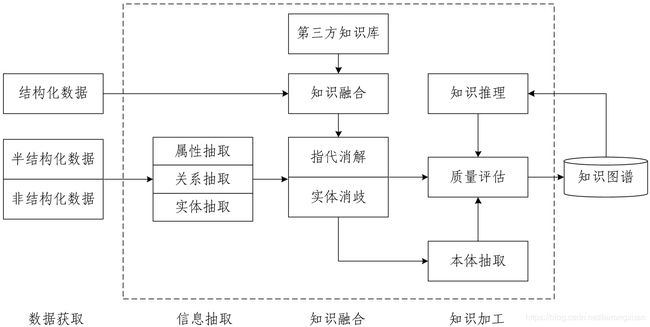
(一)数据获取(Data Acquisition)
数据获取是建立知识图谱的第一步。目前,知识图谱数据源按来源渠道的不同可分为两种:一种是业务本身的数据,这部分数据通常包含在行业内部数据库表并以结构化的方式存储,是一种非公开或半公开的数据;另一种是网络上公开、抓取的数据,这些数据通常是以网页的形式存在,是非结构化的数据。
按数据结构的不同,可分为三种:结构化数据、半结构化数据和非结构化数据,根据不同的数据类型,我们采用不同的方法进行处理。
(二)信息抽取(Information Extraction)
信息抽取的关键问题是如何从异构数据源中自动抽取信息得到候选知识单元。如前文所说,知识获取有两种渠道,前者只需要简单预处理即可以作为后续AI系统的输入,但后者一般需要借助于自然语言处理等技术来提取出结构化信息,这正是信息抽取的难点问题,涉及的关键技术包括实体抽取、关系抽取和属性抽取。
(1)实体抽取(Entity Extraction)/命名实体识别(Name Entity Recognition)
实体抽取又称为命名实体识别(NER),是指从文本数据集中自动识别出命名实体,其目的就是建立知识图谱中的“节点”。实体抽取的质量(准确率和召回率)对后续的知识获取效率和质量影响极大,因此是信息抽取中最为基础和关键的部分。
实体的类型主要包括三大类七小类:
- 实体类(包括人名,地名,机构名)
- 时间类(日期,时间)
- 数字类(货币、百分比)
最初,实体识别通常采用人工预定义实体分类体系的方式,但是随着技术的日新月异,这种老旧的方式已经很难适应时代的需求,因此面向开放领域的实体识别和分类极具研究价值。
在面向开放域的实体识别和分类研究中,不需要也不可能为每个领域或者每个实体类别建立单独的语料库作为训练集。因此,研究人员主要面临的挑战是如何从给定的少量实体实例中自动发现具有区分力的模型。
一种思路是根据已知的实体实例进行特征建模,利用该模型处理海量数据集得到新的命名实体列表,然后针对新实体建模,迭代地生成实体标注语料库。
另一种思路是利用搜索引擎的服务器日志,事先并不给出实体分类等信息,而是基于实体的语义特征从搜索日志中识别出命名实体,然后采用聚类算法对识别出的实体对象进行聚类。
(2)关系抽取(Relation Extraction)
文本语料经过实体抽取之后得到的是一系列离散的命名实体(节点),为了得到语义信息,还需要从相关的语料中提取出实体之间的关联关系(边),才能将多个实体或概念联系起来,形成网状的知识结构。研究关系抽取技术,就是研究如何解决从文本语料中抽取实体间的关系。
(3)属性抽取(Attribute Extraction)
属性抽取的目标是从不同信息源中采集特定实体的属性信息,从而完成对实体属性的完整勾画,如针对某款手机,可以从互联网中获取多源(异构)的数据,从中得到其品牌、配置等信息。
如果把实体的属性值看作是一种特殊的实体,那么属性抽取实际上也是一种关系抽取。 百科类网站提供的半结构化数据是通用领域属性抽取研究的主要数据来源,但具体到特定的应用领域,涉及大量的非结构化数据,属性抽取仍然是一个巨大的挑战。
(三)知识融合(Knowledge Fusion)
经由信息抽取之后的信息单元间的关系是扁平化的,缺乏层次性和逻辑性,同时存在大量冗余甚至错误的信息碎片。知识融合,简单理解,就是将多个知识库中的知识进行整合,形成一个知识库的过程,在这个过程中,主要关键技术包含指代消解、实体消歧、实体链接。不同的知识库,收集知识的侧重点不同,对于同一个实体,有知识库的可能侧重于其本身某个方面的描述,有的知识库可能侧重于描述实体与其它实体的关系,知识融合的目的就是将不同知识库对实体的描述进行整合,从而获得实体的完整描述。
知识融合旨在解决如何将关于同一个实体或概念的多源描述信息融合起来。
(1)指代消解(Coreference Resolution)
Coreference Resolution,字面上翻译应该是“共指消解”,但在大部分博客或者论坛中通常被称呼为“指代消解”。一般情况下,指代分为三种(NLP领域一般只关注前两种指代类型):
- 一是回指(也称指示性指代),对应单词为“anaphora”,指的是当前的指代词与上文出现的词、短语或句子(句群)存在密切的语义关联性,它指向另一个词(称为先行词),该指代词的解释依赖于先行词的解释,具有非对称性和非传递性;
- 二是共指(也称同指),对应单词为“coreference”,指的是两个名词(包括代名词、名词短语)指向真实世界中的同一参照体,这种指代脱离上下文仍然成立。共指消解技术主要用于解决多个指称对应同一实体对象的问题。
- 三是“下指”,对应单词为“cataphora”,和回指刚好相反,指的是指代词的解释取决于指代词之后的某些词、短语或句子(句群)的解释。如下图中的he和his都指代后面的Lord:

所以,根据上面描述,个人认为将“Coreference Resolution”翻译为“指代消解”更为恰当。
(2)实体消歧(Entity Disambiguation)
有些实体写法不一样,但指向同一个实体,比如“New York”表示纽约,而“NYC”同样也可以表示纽约。这种情况下,实体消歧可以减少实体的种类,降低图谱的稀疏性。
实体消歧是专门用于解决同名实体产生歧义问题的技术,通过实体消歧,就可以根据当前的语境,准确建立实体链接,实体消歧主要采用聚类法。其实也可以看做基于上下文的分类问题,类似于词性消歧和词义消歧。
(3)实体链接(Entity Linking)
实体链接(entity linking)是指对于从非结构化数据(如文本)或半结构化数据(如表格)中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。其基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,然后通过相似度计算将指称项链接到正确的实体对象。
(4)知识合并
实体链接链接的是从半结构化数据和非结构化数据那里通过信息抽取提取出来的数据。那么除了半结构化数据和非结构化数据以外,还有个更方便的数据来源——结构化数据,如外部知识库和关系数据库。对于这部分结构化数据的处理,就是知识合并的内容啦。一般来说知识合并主要分为两种:
- 合并外部知识库,主要处理数据层和模式层的冲突
- 合并关系数据库,有RDB2RDF等方法
(四)知识加工(Knowledge Processing)
海量数据在经信息抽取、知识融合之后得到一系列基本的事实表达,但这并不等同于知识,要想获得结构化,网络化的知识体系,还需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分纳入知识体系中以确保知识库的质量,这就是知识加工的过程。知识加工主要包括3方面内容:本体构建、知识推理和质量评估。
(1)本体(Ontology)
本体的概念
来自维基百科的本体的定义:
In computer science and information science, an ontology is a formal naming and definition of the types, properties, and interrelationships of the entities that really or fundamentally exist for a particular domain of discourse.
译:在计算机科学和信息科学中,一个本体就是特定领域或根本存在的实体的类型、属性、相互关系的一个正式的命名和定义
本体这个概念,对于初学者来说的确有些抽象,不易理解。它可以用多种方式来描述:
- 本体是一种描述术语(包含哪些词汇)及术语间关系(描述苹果、香蕉、水果之间的关系)的概念模型。以图书分类为例,一方面限定了术语集合(即规定大家必须采用共同承认的一套词汇,禁止私自发明新词),另一方面定义术语之间的上下位关系(如:计算机技术隶属于工业技术,软件技术隶属于计算机技术,等等)。
- 本体是指公认的的概念集合、概念框架,如“人”、“事”、“物”等。
- 本体实际上就是对特定领域之中某套概念及其相互之间关系的形式化表达(formal representation)。
- 本体是指一种“形式化的,对于共享概念体系的明确而又详细的说明”,本体提供的是一种共享词表,也就是特定领域之中那些存在着的对象类型或概念及其属性和相互关系。
总的概括:本体定义了组成领域的词汇表的基本术语及其关系,以及结合这些术语和关系来定义词汇表外延的规则。
- 领域。一个本体描述的是一个特定的领域。比如我们确定这次要描述的领域是「大学」。
- 术语。指给定领域中的重要概念。例如,确定要描述大学了,对于一个大学来说什么概念是重要的呢?我们可以列举出教职工、学生、课程等等概念。
- 基本术语之间的关系。包括类的层次结构,包括并列关系、上下位关系等等。比如教职工是老师、行政人员、技术支持人员的父类;学生是本科生、研究生的父类;研究生是硕士、博士的父类等等。
- 词汇表外延的规则。包括属性、值约束、不相交描述(如教职人员和学生不相交)、对象间逻辑关系的规定(如一个教研室至少有10名教职工)等等。
本体 VS 知识图谱 VS 知识地图
引用:
本体和知识图谱都通过定义元数据以支持语义服务。不同之处在于:知识图谱更灵活, 支持通过添加自定义的标签划分事物的类别。本体侧重概念模型的说明,能对知识表示进行概括性、抽象性的描述,强调的是概念以及概念之间的关系。大部分本体不包含过多的实例,本体实例的填充通常是在本体构建完成以后进行的。知识图谱更侧重描述实体关系,在实体层面对本体进行大量的丰富与扩充。可以认为,本体是知识图谱的抽象表达,描述知识图谱的上层模式;知识图谱是本体的实例化, 是基于本体的知识库。( 黄恒琪,于娟,廖晓,席运江.知识图谱研究综述.计算机系统应用,2019,28(6):1–12.)
知识地图 (knowledge map) 将特定组织内的知识索引通过“地图”的形式串联在一起,揭示相关知识资源的类型、特征以及相互关系。 知识地图的主要功能在于实现知识的快速检索、共享和再重用,充分有效地利用知识资源。知识地图是关于知识的来源的知识。知识并非存储在知识地图中,而是存储在知识地图所指向的知识源中。知识地图指向的知识源包含数据库、文件以及拥有丰富隐性知识的专家或员工。有的企业应用知识地图来揭示知识的结构,实现对知识及其相关知识的检索。( 黄恒琪,于娟,廖晓,席运江.知识图谱研究综述.计算机系统应用,2019,28(6):1–12.)
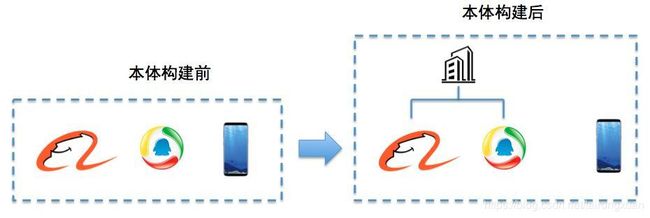
(2)本体构建(Ontology Extraction)
本体构建过程包含三个阶段:
- 实体并列关系相似度计算
- 实体上下位关系抽取
- 本体的生成
比如对下面这个例子,当知识图谱刚得到“阿里巴巴”、“腾讯”、“手机”这三个实体的时候,可能会认为它们三个之间并没有什么差别,但当它去计算三个实体之间的相似度后,就会发现,阿里巴巴和腾讯之间可能更相似,和手机差别更大一些。
这就是第一步的作用,但这样下来,知识图谱实际上还是没有一个上下层的概念,它还是不知道,阿里巴巴和手机,根本就不隶属于一个类型,无法比较。因此我们在实体上下位关系抽取这一步,就需要去完成这样的工作,从而生成第三步的本体。
当三步结束后,这个知识图谱可能就会明白,“阿里巴巴和腾讯,其实都是公司这样一个实体下的细分实体。它们和手机并不是一类。”
(3)知识推理(Knowledge Inference)
完成了本体构建这一步之后,一个知识图谱的雏形便已经搭建好了。但可能在这个时候,知识图谱之间大多数关系都是残缺的,缺失值非常严重,那么这个时候,我们就可以使用知识推理技术,去完成进一步的知识发现。
知识推理就是指从知识库中已有的实体关系数据出发,经过计算机推理,建立实体间的新关联,从而扩展和丰富知识网络。
例如康熙是雍正的父亲,雍正是乾隆的父亲,那么尽管康熙和乾隆这两个实体之间通过知识推理,就可以获得他们之间是祖孙关系。
知识推理的对象也并不局限于实体间的关系,也可以是实体的属性值,本体的概念层次关系等。比如:
- 推理属性值:已知某实体的生日属性,可以通过推理得到该实体的年龄属性;
- 推理概念:已知(老虎,科,猫科)和(猫科,目,食肉目)可以推出(老虎,目,食肉目)
知识的推理方法可以分为2大类:基于逻辑的推理和基于图的推理。
(4)质量评估(Quality Evaluation)
质量评估也是知识库构建技术的重要组成部分,这一部分存在的意义在于:可以对知识的可信度进行量化,通过舍弃置信度较低的知识来保障知识库的质量。
三、Reference
1、通俗易懂解释知识图谱 或 一文揭秘!自底向上构建知识图谱全过程
2、斯坦福CS224n(15)指代消解
3、知识图谱学习系列之一:知识图谱综述
4、知识图谱的总体构建思路
5、知识图谱—初识本体
6、本体概述