OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks(阅读)
1、Abstract:
本文展示一种ConvNets框架,整合了classification, localization, detection。利用multi-scale和sliding window与ConvNets结合达到了很好的效果。本文介绍了一种通过积累predicted bounding boxes而不是通过限制predicted bounding boxes来detection和localization的方法。论文从最好的模型中提取特征,文章称为OverFeat。
2、Introduction:
卷积网络的主要优势是提供end-to-end解决的方案;劣势就是对于标签数据集很贪婪。
ImageNet数据集上的分类任务图片,物体大致分布在图片中心而且感兴趣的物体明显填充在图片中,这就导致分类任务很完美,定位和检测效果很差。感兴趣的物体常常在尺寸和位置(以滑窗的方式)上有变化。
解决这个问题三个ideas:
“The first idea in addressing this is to apply a ConvNet at multiple locations in the image, in a sliding window fashion, and over multiple scales.”
第一个想法就是不同位置,使用滑动窗,不同缩放比例上应用卷积网络。
“the second idea is to train the system to not only produce a distribution over categories for each window, but also to produce a prediction of the location and size of the bounding box containing the object relative to the window. ”
第二个想法就是训练一个卷积网络不仅产生类别分布,还产生一个位置的预测和bounding box的尺寸(包括相对于窗口的物体);
“The third idea is to accumulate the evidence for each category at each location and size.”
第三个想法就是积累在每个位置和尺寸对应类别的置信度。
在多缩放尺度下以滑窗的方式利用卷积网络用了侦测和定位很早就有人提出了,一些学者直接训练卷积网络进行预测物体的相对于滑窗的位置或者物体的姿势。还有一些学者通过窗口中心像素输入到卷积网络中来分割图像来定位物体。利用分割的方法实现localization好处是bounding contours不必是矩形,region也无需完美地划定目标。缺点是需要像素级的labels来训练。
3、Vision Tasks
分类:是啥 预测top-5分类
定位:在哪是啥 预测top-5分类+每个类别的bounding box(50%以上的覆盖率认为是正确的)
检测:在哪都有啥
定位是介于分类和检测的中间任务,分类和定位使用相同的数据集,检测的数据集有额外的数据集(物体比较小)。
4、Classification
4.1模型的设计与训练每个图像被降采样成短边为256个像素,抽取5个大小为221*221的crops,并且进行水平翻转,mini-batches size:128。权重随机初始化:均值0,方差0.01.随着SGD更新,momentum:0.6,l2权重衰减:0.00001.学习率初始为0.05,在(30,50,60,70,80)后通过因子0.5衰减。dropout ratio 0.5应用到最后的全连接层(6th,7th)。
两个模型fast和accurate:
fast结构
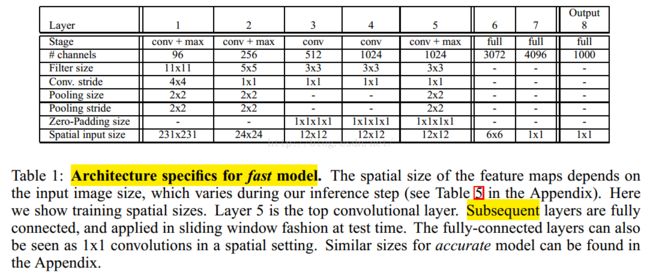
1 , 不使用LRN;
2,不使用over-pooling使用普通pooling;
3,第3,4,5卷基层特征数变大,从Alex-net的384→384→256;变为512→1024→1024.
4,fc-6层神经元个数减少,从4096变为3072
5,卷积的方式从valid卷积变为维度不变的卷积方式,所以输入变为231*231
accurate结构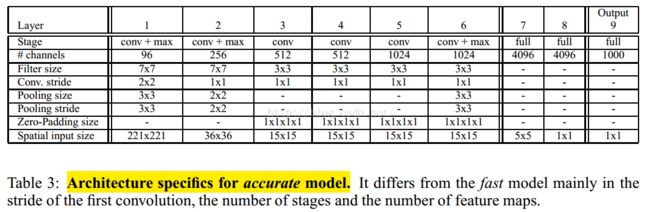
1,不使用LRN;
2,不使用over-pooling使用普通pooling,更大的pooling间隔S=2或3
3,第一个卷基层的间隔从4变为2(accurate 模型),卷积大小从11*11变为7*7;第二个卷基层filter从5*5升为7*7
4,增加了一个第三层,是的卷积层变为6层;从Alex-net的384→384→256;变为512→512→1024→1024.
4.2、Feature Extractor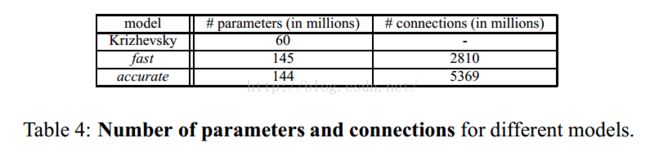
Fast模型比accurate模型的参数还多,连接数比较符合逻辑思维,为什么参数会多呢?
按理说两张图大小有区别,accurate自然会小,这应该不是根本原因吧,我们知道的caffemodel的参数主要集中在全连接层,第7层的连接数fast模型少,特征图大,说明特征图6*6大于5*5是导致模型参数大的主要因素吧。
4.3、多尺寸分类
Alex-net中,使用multi-view的方式来投票分类测试;然而这种方式可能忽略图像的一些区域,在重叠的view区域会有重复计算;而且还只在单一的图片缩放比例上测试图片,这个单一比例可能不是反馈最优的置信区域。
作者在多个缩放比例,不同位置上,对整个图片密集地进行卷积计算;这种滑窗的方式对于一些模型可能由于计算复杂而被禁止,但是在卷积网络上进行滑窗计算不仅保留了滑窗的鲁棒性,而且还很高效。每一个卷积网络的都输出一个m*n-C维的空间向量,C是分类的类别数;不同的缩放比例对应不同的m和n。
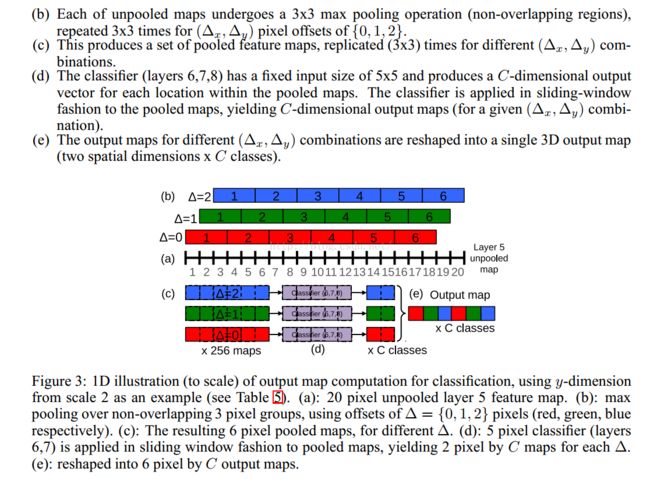
整个网络的子采样比例=2*3*2*3=36,即当应用网络计算时,输入图像的每个维度上,每36个像素才能产生一个输出。在图像上密集地应用卷积网络,对比10-views(图像做了crop,四个corner,加一个中间,总共变成了5个子图像,然后对图像进行翻转,这样就变成了10个图像)的测试分类方法,此时输出分布会降低准确率;因为物体和view可能没有很好的匹配分布(物体和view越好的匹配,网络输出的置信度越高)。这个36是什么呢?这个是针对accurate模型里面的,看下图的红色圈,

红色标记的stride表示的就相当于对原图降采样,所以作者说的:“However, thetotal subsampling ratio in the network described above is 2x3x2x3, or 36.”那么对于221*221的图像来说,通过了前面的conv+pooling就瞬间变成了6*6了。现在可以开心的在这个feature map上做滑动了。可以看到layer7(第一个fc层)的输入是5*5的,也就是说用这个5*5的窗口去6*6的上面滑,就可以得到2*2的窗口了,每一个窗口对应一个位置,将这4个5*5的作为输入,分别输入fc,这样就可以得到4个C向量,C代表要分的1000个类。这样实现了一个粗糙的滑窗。
为什么不用直接输入图像就给出类别呢?那是因为像ImageNet这样的数据,主要的物体是在图像中央,并且大小是填充了图像相当大的部分的,所以就算是有一些variation,那也是CNN能handle的,但是如果在测试中物体只是一个很小尺寸,并且出现在图像的一个角落,那么这个variation对于训练数据来说是完全impossible的。所以直接CNN分类的效果会很差。除非训练数据覆盖了各种尺寸和位置,当然这是non-sense的。文章的亮点:在原图上滑窗是没有明确的特征,那么就在输出的feature map上滑,这样就有针对性。
作者觉得方法还是不好,采取在最后一个max-pooling层换成偏置pooling,偏置pooling也算是一种数据增益技术。
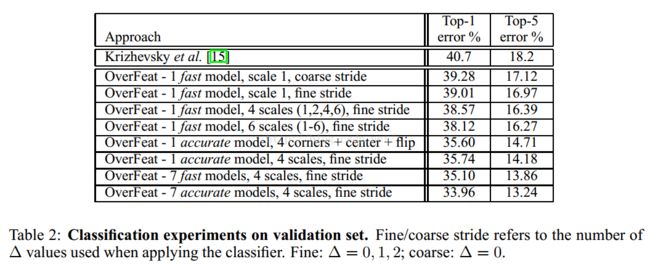
1,fast模型,比Alex-net结果提升了近1%。本文Alex-net模型结果为18.2%比他们自己测试的高2%左右
2,accurate模型单个模型提升了近4%,说明增大网络可以提高分类效果。
3,采用偏置max-pooling感觉提升效果很小,感觉是因为卷积特征激活值具有很高的聚集性,每个offset特征图很相似,max-pooling后也会很相似。
4,多个缩放比例测试分类对于结果提升比较重要,通过多个比例可以把相对较小的物体放大,以便于特征捕捉。
4.4、卷积网络和滑窗效率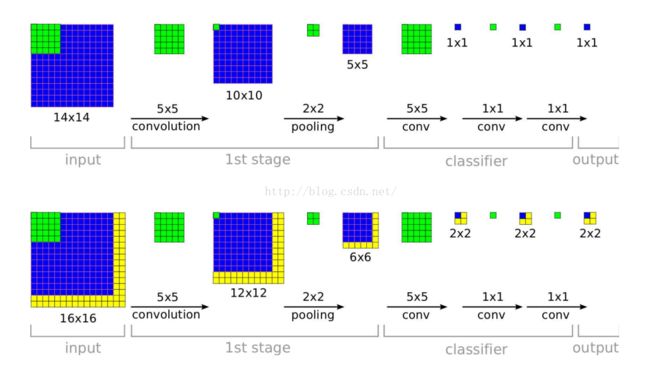
前面的multi-scale能提升预测的性能。
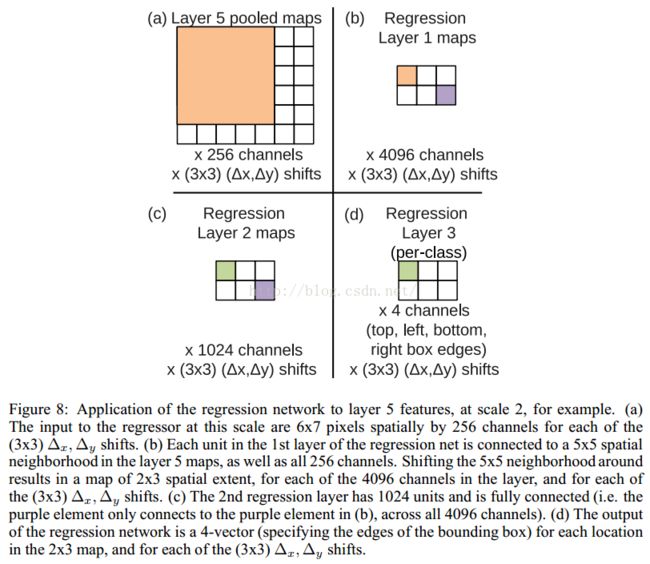
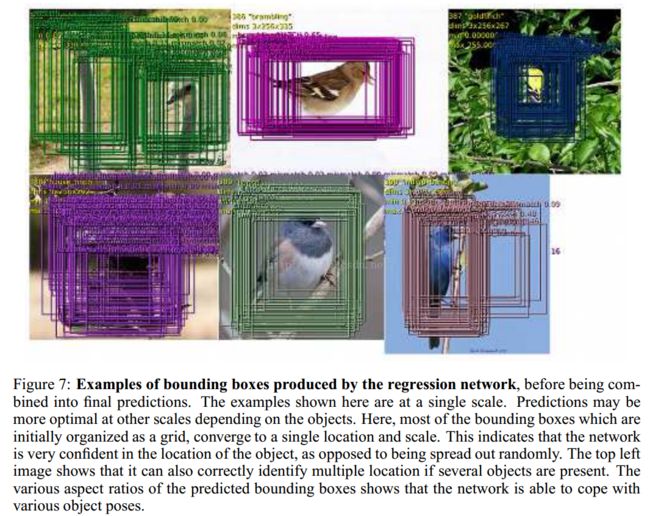


a)在6个缩放比例上运行分类网络,在每个比例上选取top-k个类别,就是给每个图片进行类别标定Cs
b)在每个比例上运行预测boundingbox网络,产生每个类别对应的bounding box集合Bs
c)各个比例的Bs到放到一个大集合B
d)融合bounding box。具体过程应该是选取两个bounding box b1,b2;计算b1和b2的匹配分式,如果匹配分数大于一个阈值,就结束,如果小于阈值就在B中删除b1,b2,然后把b1和b2的融合放入B中,在进行循环计算。
match score是两个bounding boxes中心的距离和它们交叉面积之和。box merge计算两bounding boxes的coordinates的平均值。
最后的预测是找maximum class scores的那个merged bounding boxes。
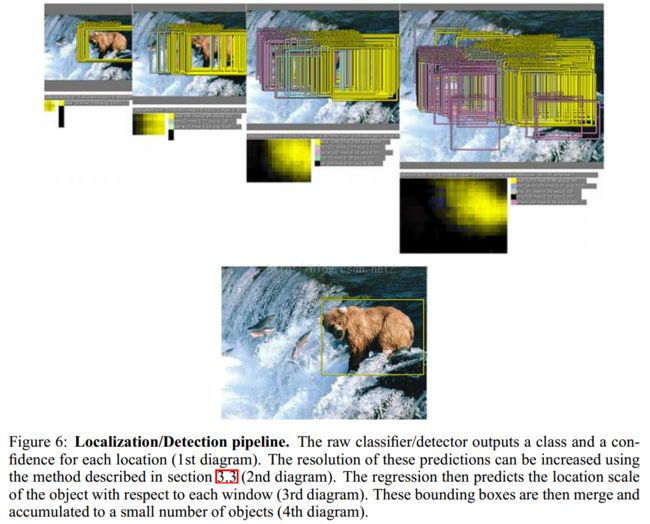

6、Detection


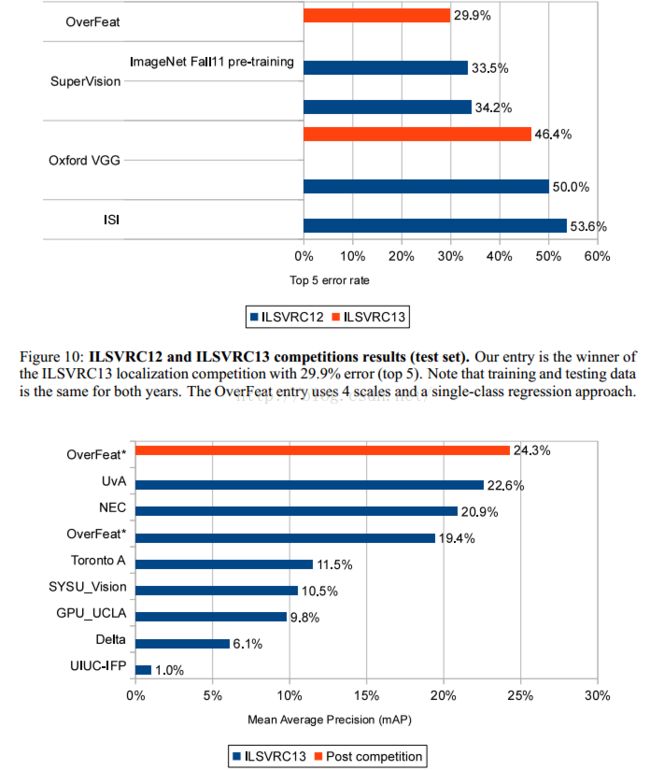
overfeat ranks 4th on classification, 1st on localization and 1st on detection.
本文解释了ConvNets在localization and detection上高效的原因。
提出了一个结合分类、定位、检测的流程,它共享特征直接从像素点学习。它用multi-scale、sliding window方法。
overfeat可以在以下方向改进:
- localization时没有实时反馈到整个网络,反馈后效果会更好。
- 本文使用 l2 loss(衰退网络的参数),而不是直接优化intersection-over-union (IOU) 准则。
- 变换bounding box的参数帮助输出去相关,这有助于网络训练。