论文:Wide & Deep Learning for Recommender Systems,DLRS,2016,Google
业务背景
Google Play是一个由Google为Android设备开发的在线应用程序商店(类似于apple store),可以让用户去浏览、下载及购买在Google Play上的第三方应用程序。Google Play拥有超过10亿活跃用户和超过100万个应用。WDL的应用场景就是Google Play的app推荐。
overview
推荐系统可以看作一个搜索排序系统,其中输入语句是一组用户和上下文信息,输出是一个排了序的商品列表。给定一个查询语句,推荐任务是在数据库中查询相关的商品,然后基于某些目标(例如点击或者购买)对商品排名。app推荐系统的框架如图所示。
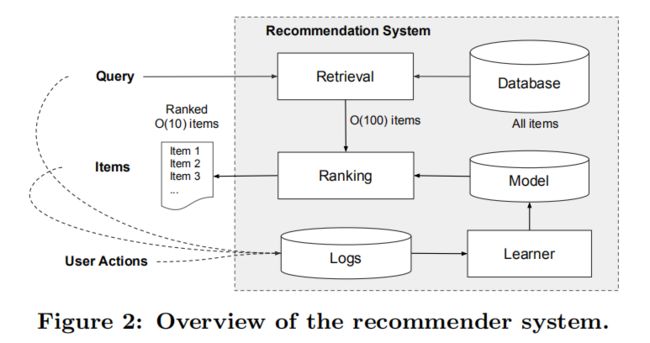
数据库中有超过一百万个应用程序,因此在服务延迟要求(通常为O(10)毫秒)内为每个查询语句全面的对每个app评分是不现实的。
因此,推荐系统的整体架构由两个部分组成,检索系统(或者说候选生成系统)和排序系统(排序网络)。首先,用 检索(retrieval) 的方法对大数据集进行初步筛选,返回最匹配 query 的一部分物品列表,这里的检索通常会结合采用 机器学习模型(machine-learned models) 和 人工定义规则(human-defined rules) 两种方法。从大规模样本中召回最佳候选集之后,再使用 排序系统 对每个物品进行算分和排序。
排序分数通常是P(y|x), 即在给定特征x的前提下用户行为label y出现的概率;
使用的特征有:
1.用户特征(国家、语言、人口统计)
2.上下文特征(设备、时间、星期)
3.印象特征(应用年龄、应用历史数据)
Wide&Deep Learning 主要就是应用在 Ranking 模型。
Wide & Deep Models
简单来说,人脑就是一个不断记忆(memorization)并且归纳(generalization)的过程,而这篇论文的思想,就是将宽线性模型(Wide Model,用于记忆,下图左侧)和深度神经网络模型(Deep Model,用于归纳,下图右侧)结合,汲取各自优势形成了 Wide & Deep 模型用于推荐排序(下图中间)。
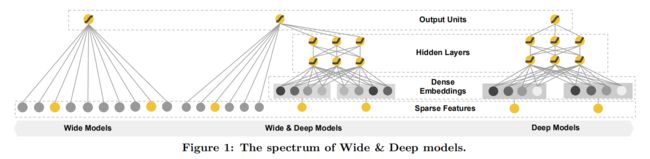
Wide模型
Memorization can be loosely defined as learning the frequent co-occurrence of items or features and exploiting the correlation available in the historical data.
要理解的概念是 Memorization,主要是学习特征的共性或者说相关性,产生的推荐是和已经有用户行为的物品直接相关的物品。为了达到 Memorization,我们对稀疏的特征采取 cross-product transformation,即使用向量外积表示组合特征。
用的模型是 逻辑回归(logistic regression, LR),LR 的优点就是简单(simple)、容易规模化(scalable)、可解释性强(interpretable)。
总结一下,Wide模型如上图中的左侧图所示,实际上就是一个广义线性模型:
特征包括两类: 原始特征和 组合特征。
如性别和语言的组合特征:
性别:{男,女},
语言:{中文,英语},
组合特征:{男且中文,男且英语,女且中文,女且英语},
某样本{性别=女,语言=英语},则组合特征 {女且英语}=1,其他组合特征=0
ps:组合特征是人工定义的。组合特征捕获了二元特征之间的相互作用,并为广义线性模型增加了非线性。
Deep模型
Generalization is based on transitivity of correlation and explores new feature combinations that have never or rarely occurred in the past.
要理解的概念是 Generalization,可以理解为相关性的传递(transitivity),会学习新的特征组合,来提高推荐物品的多样性,或者说提供泛化能力(Generalization)。
泛化往往是通过学习 low-dimensional dense embeddings 来探索过去从未或很少出现的新的特征组合来实现的,通常的 embedding-based model 有 Factorization Machines(FM) 和 Deep Neural Networks(DNN)。
特殊兴趣或者小众爱好的用户,query-item matrix 非常稀疏,很难学习,然而 dense embedding 的方法还是可以得到对所有 query-item pair 非零的预测,这就会导致 over-generalize,推荐不怎么相关的物品。这点和 LR 正好互补,因为 LR 只能记住很少的特征组合。
Deep模型如上图中的右侧的图所示,是一个前馈神经网络。
f 是激活函数(通常用 ReLU),l 是层数。
基于 embedding 的深度模型的输入是 类别特征(产生的embedding)+连续特征(归一化)。
Wide & Deep联合训练
wide部分和deep部分的输出加权求和,使用一个公共的logistic损失函数用来联合训练:
- 得到output后wide部分和deep部分使用mini batch随机优化同步反向传播梯度;
- 训练时 Wide Model 部分用了 Follow-the-regularized-learder(FTRL)+ L1 正则,Deep Model 用了 AdaGrad
系统实施
如图展示了整个 Wide & Deep Learning 的整体运行流程。
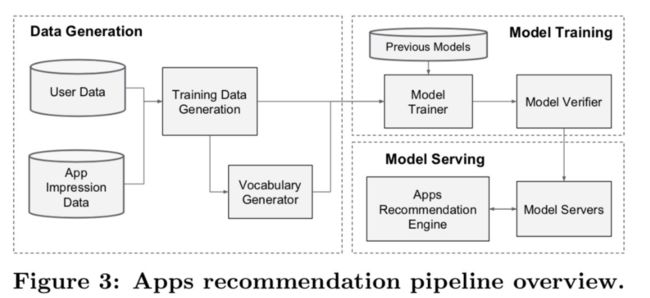
数据生成
训练数据生成。一段时间的用户和展示数据。一条数据对应一次展示,label是展示的这个app是否被安装的二分类标签。
类别特征映射到整数ID,转为one-hot向量。举例来说,education 是个类别特征。其可能的取值有 ["Preschool","1st-4th", "5th-6th", "7th-8th", "9th","10th-12th", "Bachelors", "HS-grad", "Masters","Some-college", "Assoc-acdm", "Assoc-voc", "Doctorate", "Prof-school"],通过这样的分类特征的字符串-ID的映射表,可以将分类特征的字符值转化为ID值。如果某用户的 education = "9th" ,则 转换后为 [0,0,0,0,1,0,...,0]
上述的 education 类别特征是“知道所有的不同取值,而且取值不多”的情况。
如果类别特征中,不知道其所有不同取值,或者取值非常多。比如特征 occupation,取值可能有好几千种,则使用 hash_bucket 来将类别特征转化为一个定长的 one-hot 向量。代码示例:
occupation = tf.feature_column.categorical_column_with_hash_bucket( 'occupation', hash_bucket_size=1000)
连续特征归一化至[0,1]。举例来说,age 是一个连续特征。根据不同取值的出现次数,可以均匀设置9个边界,如 boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60],将age分为了 10 份,第 i 份的标准化值为:。如果某用户的 age = 28,则标准化后为 age = 0.3。
Model Training
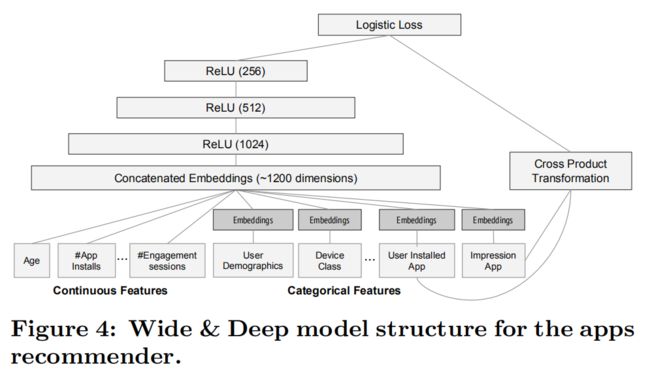
wide部分:输入用户展示的app和安装的app的 cross-product transformation(向量外积)。
这里论文里没有细说,我自己做了一个简单的尝试,体会了一下one-hot的向量外积是如何表示组合特征的。(字有点丑,请见谅~)cross-product transformation
但是!去看了一些WDL的实现,发现在实现的时候,wide部分基本没有使用外积,多数使用类似于lookup的方式去找历史交互物品ids里有没有当前的候选id,和传统方式差别不大,只是有一些“记忆”的思想。
举例来说,看阿里DIN时看了其中关于WDL对照方法的实现,只使用了向量的某两三个值的乘积作为wide,我理解为一种向量抽样上的相似度,和lookup差别不大。
问了阿里的算法,说理解wide的记忆思想即可,工业上实现时一般wide不使用了都。
deep部分:为每个 分类特征 学习32维的嵌入向量。我们将所有向量和归一化的 连续特征 连接成一个约1200维的稠密向量。然后将连接的矢量输入3个ReLU层,最后输入逻辑输出单元。
wide&deep模型在超过5000亿个样本的数据集上训练。需要注意的是,当新的训练数据来临的时候,用的是热启动(warm-starting)方式,也就是从之前的模型中读取 embeddings 以及 linear model weights 来初始化一个新模型,而不是全部推倒重新训练。
Model Serving
当模型训练并且优化好之后,我们将它载入服务器,对每一个 request,排序系统从检索系统接收候选列表以及用户特征,来为每一个 app 算分排序,分数就是前向传播的值(forward inference)啦,可以并行训练提高 performance。
实验结果
度量的指标有两个,分别针对在线的度量和离线的度量,在线时,通过A/B test,最终利用安装率(Acquisition);离线则使用AUC作为评价模型的指标。
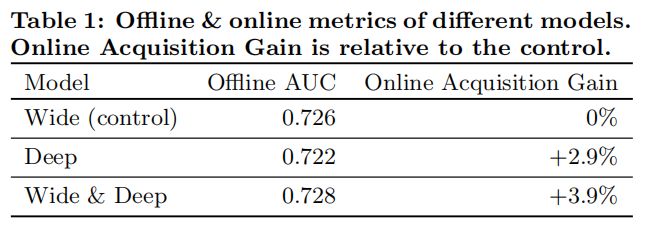
离线评估AUC提升不大,取了1%的用户在线评估,效果比较好。 解释是说离线数据是fixed的,在线能学新的用户responses。我的理解是因为排序结果变了,影响用户的点击,离线不能反映真实的用户行为。比如原来模型把差一点app的排上来,导致用户安装了。你把更好的排上了反而预测错了。
总结
Wide & Deep Learning 是非常经典的paper,其并连式的结构设计影响深远(有一批并行结构的推荐模型)。即使2018-19年发的一些论文也会把 wide & deep learning 当做 state-of-art 来进行对照实验。
paper中值得我们学习的点:
- 并连式网络结构,用LR学习浅层特征(记忆能力),用DNN学习深层特征(泛化能力)。
- 大量的特征工程。特征做得好是推荐结果好的一大关键。
- 连续值先用累计分布函数CDF归一化到[0,1],再划档离散化,是个非常有效的数据归一化处理方式。
- 离线评估没提升也不要轻易放弃,成功可能就跟你擦肩而过。仔细想想,离线评估确实有坑,线上有效果最重要。