线性回归之梯度下降详解
在了解梯度下降(Gradient Descent)之前,我们先要知道有关线性回归的基本知识,这样可以进一步的加深对梯度下降的理解,当然梯度下降(Gradient Descent)并不单单只能进行回归预测,它还可以进行诸如分类等操作。
关于线性回归的具体讲解本文不详细涉及,只简单列出几个相关公式。(关于线性回归可以看这篇 传送门)
线性回归
公式 4-1:线性回归模型预测
y ^ = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n \hat{y} = \theta_0 + \theta_1x_{1} + \theta_2x_{2} + ... + \theta_nx_{n} y^=θ0+θ1x1+θ2x2+...+θnxn
- y ^ \hat{y} y^ 是预测值
- n n n 是特征的数量
- x i x_{i} xi 是 i i i 个特征值
- θ j \theta_j θj 是第 j j j 个模型参数 (包括偏置项 θ 0 \theta_0 θ0 以及特征权重 θ 1 , θ 2 , . . . , θ n \theta_1, \theta_2, ..., \theta_n θ1,θ2,...,θn)
也可以用更为简洁的向量化形式表达
公式 4-2:线性回归模型预测 (向量化)
y ^ = h θ ( X ) = θ T ⋅ X \hat{y} = h_{\theta}(X) = \theta^T \cdot X y^=hθ(X)=θT⋅X
- θ \theta θ 是模型的参数向量,包括偏置项 θ 0 \theta_0 θ0 以及特征权重 θ 1 \theta_1 θ1 到 θ n \theta_n θn
- θ T \theta^T θT 是 θ \theta θ 的转置向量 (为行向量,而不再是列向量)
- X X X 是实例的特征向量,包括从 θ 0 \theta_0 θ0 到 θ n , θ 0 \theta_n, \theta_0 θn,θ0 永远为 1 1 1
- θ T ⋅ X \theta^T \cdot X θT⋅X 是 θ T \theta^T θT 和 X X X 的点积
- h θ h_{\theta} hθ 是模型参数 θ \theta θ 的假设函数
公式 4-3:线性回归模型的 M S E MSE MSE 成本函数
M S E ( X , h θ ) = 1 m ∑ i = 1 m ( θ T ⋅ X ( i ) − y ( i ) ) 2 MSE(X, h_{\theta}) = \frac{1}{m}\sum_{i=1}^{m} (\theta^T \cdot X^{(i)} - y^{(i)})^2 MSE(X,hθ)=m1i=1∑m(θT⋅X(i)−y(i))2
标准方程
为了得到使成本函数最小的 θ \theta θ 值,有一个闭式解方法——也就是一个直接得出结果的数学方程,即标准方程。
公式 4-4:标准方程
M S E ( X , h θ ) = 1 m ∑ i = 1 m ( θ T ⋅ X ( i ) − y ( i ) ) 2 MSE(X, h_{\theta}) = \frac{1}{m}\sum_{i=1}^{m} (\theta^T \cdot X^{(i)} - y^{(i)})^2 MSE(X,hθ)=m1i=1∑m(θT⋅X(i)−y(i))2
- θ ^ \hat{\theta} θ^ 是使成本函数最小的 θ \theta θ 值
- y y y 是包含 y ( 1 ) y^{(1)} y(1) 到 y ( m ) y^{(m)} y(m) 的目标值量
我们生成一些线性数据来测试这个公式:
import numpy as np
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
import matplotlib.pyplot as plt
%matplotlib inline
# 可视化
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(X, y, "b.")
plt.show()
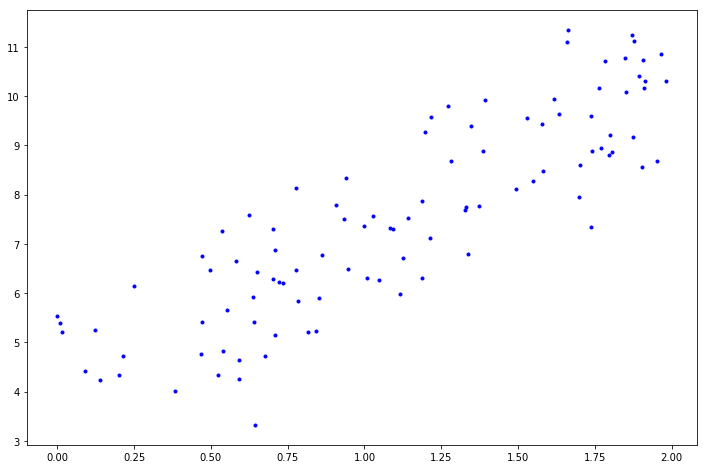
现在我们使用标准方程来计算 θ ^ \hat{\theta} θ^。使用 Numpy 的线性代数模块 (np.linalg) 中的 inv() 函数来对矩阵求逆,并用 dot() 方法计算矩阵的内积:
X_b = np.c_[np.ones((100, 1)), X] # add xo = 1 to each instance
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
我们实际用来生成数据的函数是 y = 4 + 3 x 0 + 高 斯 噪 声 y = 4 + 3x_0 + 高斯噪声 y=4+3x0+高斯噪声。
theta_best
array([[4.0939709 ],
[3.08934507]])
我们期待的是 θ 0 = 4 , θ 1 = 3 \theta_0 = 4, \theta_1 = 3 θ0=4,θ1=3 得到的是 θ 0 = 4.0939709 , θ 1 = 3.08934507 \theta_0 = 4.0939709, \theta_1 = 3.08934507 θ0=4.0939709,θ1=3.08934507。非常接近了,因为噪声的存在使其不可能完全还原为原本的函数。
现在可以用 θ ^ \hat{\theta} θ^ 做出预测:
X_new = np.array([[0], [2]])
X_new_b = np.c_[np.ones((2, 1)), X_new] # add x0 = 1 to each instance
y_predict = X_new_b.dot(theta_best)
y_predict
array([[ 4.0939709 ],
[10.27266104]])
# 绘制模型的预测结果
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(X_new, y_predict, "r-")
ax.plot(X, y, "b.")
plt.show()
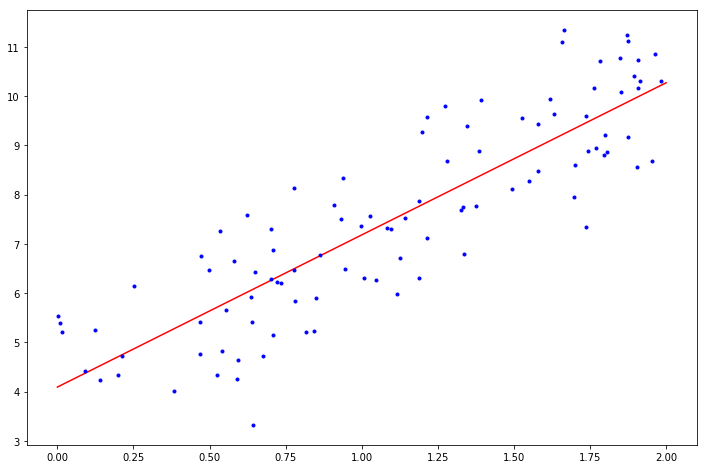
# Scikit-Learn 的等效代码
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X, y)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None,
normalize=False)
lin_reg.intercept_, lin_reg.coef_
(array([4.0939709]), array([[3.08934507]]))
lin_reg.predict(X_new)
array([[ 4.0939709 ],
[10.27266104]])
梯度下降
梯度下降是一种非常通用的优化算法,能够为大范围的问题找到最优解。梯度下降的中心思想就是迭代地调整参数从而使成本函数最小化。
假设你迷失在山上的浓雾之中,你能感觉到的只有你脚下路面的坡度。快速到达山脚的一个策略就是沿着最陡的方向下坡。这就是梯度下降的做法:通过测量参数向量 θ \theta θ 相关的误差函数的局部梯度,并不断沿着降低梯度的方向调整,直到梯度降为0,到达最小值!
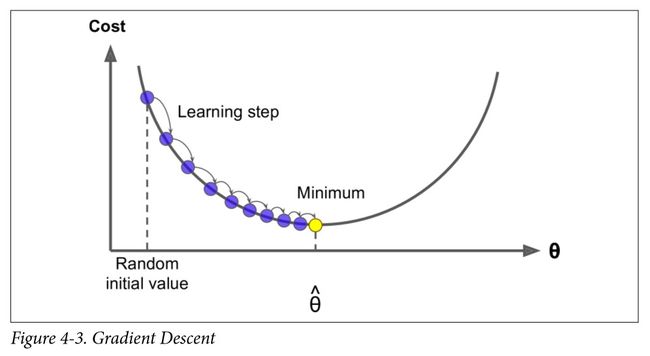
具体来说,首先使用一个随机的 θ \theta θ 值(这被称为随机初始化), 然后逐步改进,每次踏出一步,每一步都尝试降低一点成本函数(如 M S E MSE MSE ),直到算法收敛出一个最小值(参见图4-3)
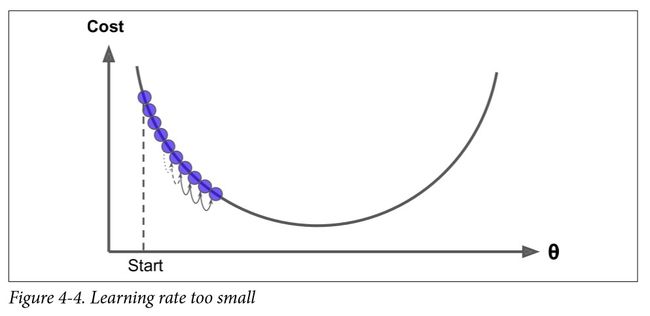
梯度下降中一个重要参数是每一步的步长,这取决于超参数学习率。如果学习率太低,算法需要经过大量迭代才能收敛,这将耗费很长时间(参见图4-4)。
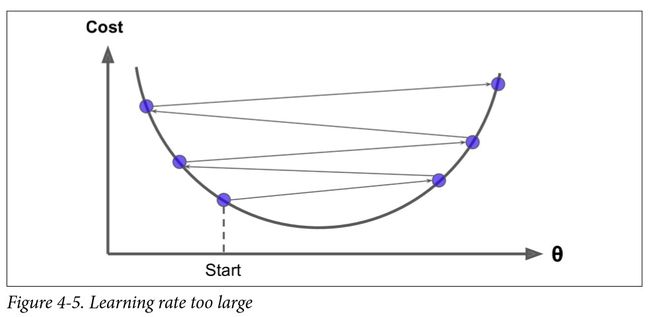
反过来说,如果学习率太高,那你可能会越过山谷直接到达山的另一边,甚至有可能比之前的起点还要高。这会导致算法发散,值越来越大,最后无法找到好的解决方案(参见图4-5)。
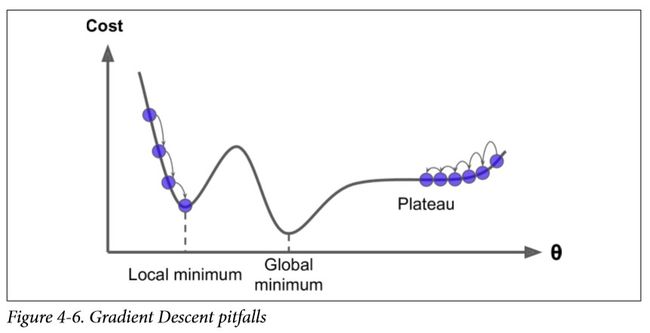
最后,并不是所有的成本函数看起来都像一个漂亮的碗。有的可能看着像洞、像山脉、像高原或者是各种不规则的地形,导致很难收敛到最小值。图4-6显示了梯度下降的两个主要挑战:如果随机初始化,算法从左侧起步,那么会收敛到一个局部最小值,而不是全局最小值。如果算法从右侧起步,那么需要经过很长时间才能越过整片高原,如果你停下得太早,将永远达不到全局最小值。
幸好,线性回归模型的 M S E MSE MSE 成本函数恰好是个凸函数,这意味着连接曲线上任意两个点的线段永远不会跟曲线相交。也就是说不存在局部最小,只有一个全局最小值。它同时也是一个连续函数,所以斜率不会产生陡峭的变化1。这两件事保证的结论是:即便是乱走,梯度下降都可以趋近到全局最小值(只要等待时间足够长,学习率也不是太高)。
成本函数虽然是碗状的,但如果不同特征的尺寸差别巨大,那它可能是一个非常细长的碗。如图4-7所示的梯度下降,左边的训练集上特征1和特征2具有相同的数值规模,而右边的训练集上,特征1的值则比特征2要小得多。因为特征1的值较小,所以 θ 1 \theta_1 θ1 需要更大 的变化来影响成本函数,这就是为什么碗形会沿着 θ 1 \theta_1 θ1 轴拉长。)
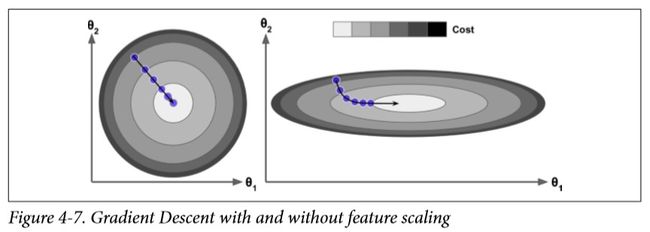
正如你所见,左图的梯度下降算法直接走向最小值,可以快速到达。而在右图中,先是沿着与全局最小值方向近乎垂直的方向前进, 接下来是一段几乎平坦的长长的山谷。最终还是会抵达最小值,但是这需要花费大量的时间。
注意: 应用梯度下降时,需要保证所有特征值的大小比例都差不多 (比如使用Scikit-Learn的StandardScaler类),否则收敛的时间会长很多。
这张图也说明,训练模型也就是搜寻使成本函数(在训练集上)最小化的参数组合。这是模型参数空间层面上的搜索:模型的参数越多,这个空间的维度就越多,搜索就越难。同样是在干草堆里寻找一根针,在一个三百维的空间里就比在一个三维空间里要棘手得多。幸运的是,线性回归模型的成本函数是凸函数,针就躺在碗底。
批量梯度下降
要实现梯度下降,你需要计算每个模型关于参数 θ j \theta_j θj 的成本函数的梯度。换言之,你需要计算的是如果改变 θ j \theta_j θj ,成本函数会改变多少。 这被称为偏导数。这就好比是在问 “如果我面向东,我脚下的坡度斜率是多少?” 然后面向北问同样的问题(如果你想象超过三个维度的宇宙,对于其他的维度以此类推)。公式4-5计算了关于参数 θ j \theta_j θj 的成本函数的偏导数,计作 ∂ ∂ θ j M S E ( θ ) \frac{\partial}{\partial \theta_j}MSE(\theta) ∂θj∂MSE(θ)
公式 4-5 :成本函数的偏导数
∂ ∂ θ j M S E ( θ ) = 2 m ∑ i = 1 m ( θ T ⋅ X ( i ) − y ( i ) ) x j ( i ) \frac{\partial}{\partial \theta_j}MSE(\theta) = \frac{2}{m}\sum_{i=1}^{m} (\theta^T \cdot X^{(i)} - y^{(i)})x_j^{(i)} ∂θj∂MSE(θ)=m2i=1∑m(θT⋅X(i)−y(i))xj(i)
如果不想单独计算这些梯度,可以使用公式4-6对其进行一次性计算。梯度向量,记作 ∇ θ M S E ( θ ) \nabla_\theta MSE(\theta) ∇θMSE(θ) ,包含所有成本函数(每个模型参数一个)的偏导数。
公式 4-6 :成本函数的梯度向量
∇ θ M S E ( θ ) = [ ∂ ∂ θ 0 M S E ( θ ) ∂ ∂ θ 1 M S E ( θ ) . . . ∂ ∂ θ n M S E ( θ ) ] = 2 m X T ⋅ ( X ⋅ θ − y ) \nabla_\theta MSE(\theta) = \left[ \begin{matrix} \frac{\partial}{\partial \theta_0}MSE(\theta) \\ \frac{\partial}{\partial \theta_1}MSE(\theta) \\ ... \\ \frac{\partial}{\partial \theta_n}MSE(\theta) \end{matrix} \right] = \frac{2}{m}X^T \cdot (X \cdot \theta - y) ∇θMSE(θ)=⎣⎢⎢⎡∂θ0∂MSE(θ)∂θ1∂MSE(θ)...∂θn∂MSE(θ)⎦⎥⎥⎤=m2XT⋅(X⋅θ−y)
注意: 公式4-6在计算梯度下降的每一步时,都是基于完整的训练集 X X X 的。这就是为什么该算法会被称为批量梯度下降:每一步都使用整批训练数据。因此,面对非常庞大的训练集时,算法会变得极慢(不过我们即将看到快得多的梯度下降算法)。但是,梯度下降算法随特征数量扩展的表现比较好:如果要训练的线性模型拥有几十万个特征,使用梯度下降比标准方程要快得多。
一旦有了梯度向量,哪个点向上,就朝反方向下坡。也就是从 θ \theta θ 中减去 ∇ θ M S E ( θ ) \nabla_\theta MSE(\theta) ∇θMSE(θ) 。这时学习率 η \eta η 就发挥作用了:用梯度向量乘以 η \eta η 确定下坡步长的大小(公式4-7)。
公式 4-6 :梯度下降步长
θ ( n e x t s t e p ) = θ − η ∇ θ M S E ( θ ) \theta^{(next \ step)} = \theta - \eta\nabla_\theta MSE(\theta) θ(next step)=θ−η∇θMSE(θ)
eta = 0.1 # learning rate
n_iterations = 1000
m = 100
theta = np.random.randn(2,1) # random initialization
for iteration in range(n_iterations):
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
theta
array([[4.0939709 ],
[3.08934507]])
这不正是标准方程的发现么!梯度下降表现完美。如果使用了其他的学习率 η \eta η 呢?图4-8展现了分别使用三种不同的学习率时, 梯度下降的前十步(虚线表示起点)。
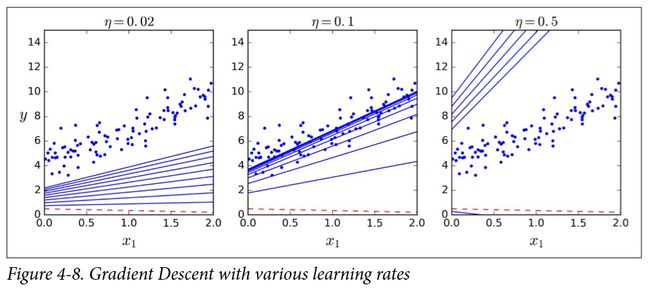
左图的学习率太低:算法最终还是能找到解决方法,就是需要太长时间。中间的学习率看起来非常棒:几次迭代就收敛出了最终解。 而右边的学习率太高:算法发散,直接跳过了数据区域,并且每一步都离实际解决方案越来越远。
要找到合适的学习率,可以使用网格搜索。但是你可能需要限制迭代次数,这样网格搜索可以淘汰掉那些收敛耗时太长的模型。
你可能会问,要怎么限制迭代次数呢?如果设置太低,算法可能在离最优解还很远时就停了;但是如果设置得太高,模型达到最优解后,继续迭代参数不再变化,又会浪费时间。一个简单的办法是,在 开始时设置一个非常大的迭代次数,但是当梯度向量的值变得很微小时中断算法——也就是当它的范数变得低于 ε \varepsilon ε(称为容差)时,因为这时梯度下降已经(几乎)到达了最小值。
收敛率
成本函数为凸函数,并且斜率没有陡峭的变化时(如 M S E MSE MSE 成本函数),通过批量梯度下降可以看出一个固定的学习率有一个收敛率,为 0 ( 1 迭 代 次 数 ) 0(\dfrac{1}{迭代次数}) 0(迭代次数1)。换句话说,如果将容差 ε \varepsilon ε 缩小为原来的 1 10 \dfrac{1}{10} 101(以得到更精确的解),算法将不得不运行10倍的迭代次数
随机梯度下降
批量梯度下降的主要问题是它要用整个训练集来计算每一步的梯度,所以训练集很大时,算法会特别慢。与之相反的极端是随机梯度下降,每一步在训练集中随机选择一个实例,并且仅基于该单个实例来计算梯度。显然,这让算法变得快多了,因为每个迭代都只需要操作少量的数据。它也可以被用来训练海量的数据集,因为每次迭代只需要在内存中运行一个实例即可( S G D SGD SGD 可以作为核外算法实现)。
另一方面,由于算法的随机性质,它比批量梯度下降要不规则得多。成本函数将不再是缓缓降低直到抵达最小值,而是不断上上下下,但是从整体来看,还是在慢慢下降。随着时间推移,最终会非常接近最小值,但是即使它到达了最小值,依旧还会持续反弹,永远不会停止(见图4-9)。所以算法停下来的参数值肯定是足够好的,但不是最优的。
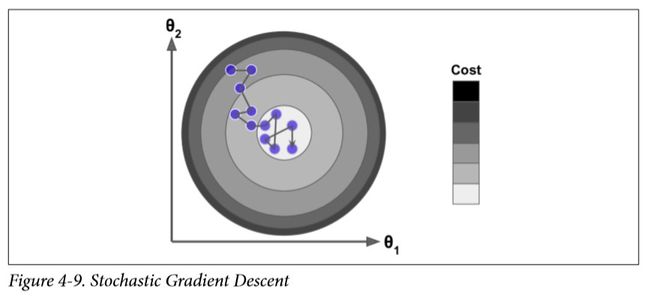
当成本函数非常不规则时(见图4-6),随机梯度下降其实可以帮助算法跳出局部最小值,所以相比批量梯度下降,它对找到全局最小值更有优势。
因此,随机性的好处在于可以逃离局部最优,但缺点是永远定位不出最小值。要解决这个困境,有一个办法是逐步降低学习率。开始的步长比较大(这有助于快速进展和逃离局部最小值),然后越来越小,让算法尽量靠近全局最小值。这个过程叫作模拟退火,因为它类似于冶金时熔化的金属慢慢冷却的退火过程。确定每个迭代学习率的函数叫作学习计划。如果学习率降得太快,可能会陷入局部最小值, 甚至是停留在走向最小值的半途中。如果学习率降得太慢,你需要太长时间才能跳到差不多最小值附近,如果提早结束训练,可能只得到一个次优的解决方案。
n_epochs = 50
t0, t1 = 5, 50 # learning schedule hyperparameters
def learning_schedule(t):
return t0 / (t + t1)
theta = np.random.randn(2,1) # random initialization
for epoch in range(n_epochs):
for i in range(m):
random_index = np.random.randint(m)
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2 * xi.T.dot(xi.dot(theta) - yi)
eta = learning_schedule(epoch * m + i)
theta = theta - eta * gradients
按照惯例,我们用 m m m 来表示迭代次数,每一次迭代称为一轮。前面的批量梯度下降需要在整个训练集上迭代 1000 1000 1000次,而这段代码只迭代了 50 50 50 次就得到了一个相当不错的解:
theta
array([[4.11135275],
[3.06756448]])
图 4-10 显示了训练过程的前 10 步 (注意不规则的步子)
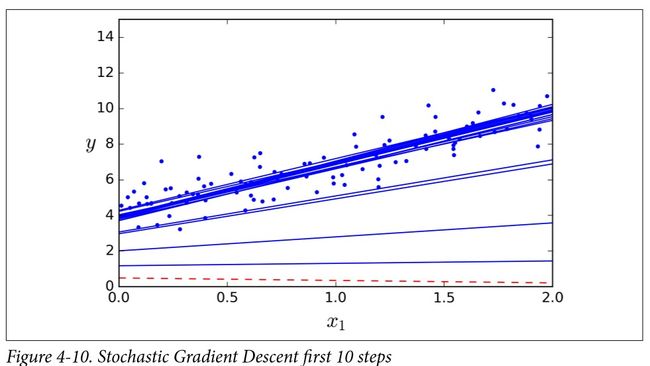
因为实例是随机挑选,所以在同一轮里某些实例可能被挑选多次,而有些实例则完全没被选到。如果你希望每一轮算法都能遍历每个实例,有一种办法是将训练集洗牌打乱,然后一个接一个的使用实例,用完再重新洗牌,以此继续。不过这种方法通常收敛得更慢。
在 Scikit-Learn 里,用 S G D SGD SGD 执行线性回归可以使用 SGDRegressor 类,其默认优化的成本函数是平方误差。下面这段代码从学习率 0.1 开始(eta0=0.1),使用默认的学习计划(跟前面的学习计划不同) 运行了50 轮,而且没有使用任何正则化(penalty=None):
import warnings
warnings.filterwarnings('ignore')
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(n_iter=50, penalty=None, eta0=0.1)
sgd_reg.fit(X, y.ravel())
SGDRegressor(alpha=0.0001, average=False, early_stopping=False, epsilon=0.1,
eta0=0.1, fit_intercept=True, l1_ratio=0.15,
learning_rate='invscaling', loss='squared_loss', max_iter=None,
n_iter=50, n_iter_no_change=5, penalty=None, power_t=0.25,
random_state=None, shuffle=True, tol=None, validation_fraction=0.1,
verbose=0, warm_start=False)
你再次得到了一个跟标准方程的解非常相近的解决方案:
sgd_reg.intercept_, sgd_reg.coef_
(array([4.08805401]), array([3.08242337]))
小批量梯度下降
我们要了解的最后一个梯度下降算法叫作小批量梯度下降。一旦理解了批量梯度下降和随机梯度下降,这个算法就非常容易理解了: 每一步的梯度计算,既不是基于整个训练集(如批量梯度下降)也不是基于单个实例(如随机梯度下降),而是基于一小部分随机的实例集也就是小批量。相比随机梯度下降,小批量梯度下降的主要优势在于可以从矩阵运算的硬件优化中获得显著的性能提升,特别是需要用到图形处理器时。
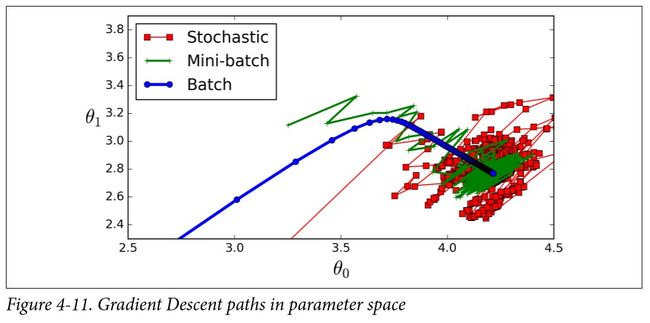
这个算法在参数空间层面的前进过程也不像 S G D SGD SGD 那样不稳定,特别是批量较大时。所以小批量梯度下降最终会比 S G D SGD SGD 更接近最小值一 些。但是另一方面,它可能更难从局部最小值中逃脱(不是我们前面看到的线性回归问题,而是对于那些深受局部最小值陷阱困扰的问题)。图 4-11 显示了三种梯度下降算法在训练过程中参数空间里的行进路线。它们最终都汇聚在最小值附近,批量梯度下降最终停在了最小值上,而随机梯度下降和小批量梯度下降还在继续游走。但是,别忘了批量梯度可是花费了大量时间来计算每一步的,如果用好了学习计划,随机梯度下降和小批量梯度下降也同样能到达最小值。
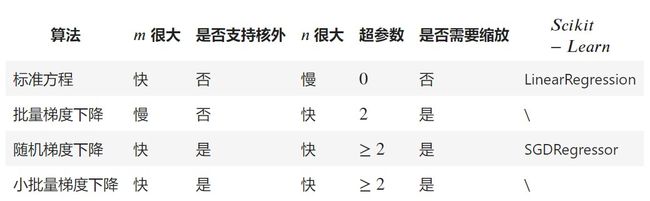
最后,我们来比较一下到目前为止所讨论过的线性回归算法 ( m m m 是训练实例的数量, n n n 是特征数量)。
参考:
- Hands-On Machine Learning with Scikit-Learn and TensorFlow