住房月租金预测
住房月租金的预测由于特征相对明显以及问题本身的复杂度较低,因此在预测中属于相对简单的,适合新手上手。本篇博客是根据自己的一系列经验以及开源社区的许多大佬整理而来,如有不合理的地方,还请多多批评指教,大家共同进步。本人看来,对这种预测问题,最重要的还是前期的数据探索以及特征工程,毕竟特征决定上限,算法只是逼近这个上限而已,所以本文的侧重点也在特征工程方面。(以下内容包含主要部分的代码及结果,需要数据集的请关注一波,私信我)
先看一下任务需求:
利用某地1-3月份的房屋租赁价格以及房屋的基本信息,对4月份的房屋月租金进行预测。
PS: 由于数据的保密性,因此提供的数据做了一定程度的脱敏处理,数据特征的大小关系以及相对关系保留。
接下来是数据集:
数据分为两组,分别是训练集和测试集:训练集为前3个月采集的数据,共196539条。 测试集为第4个月采集的数据,相对于训练集,增加了“id”字段,为房屋的唯一id,无“月租金”字段,其它字段与训练集相同,共56279条。
相关特征如下:(共19个特征)
| 字段名 | 说明 | 字段名 | 说明 |
|---|---|---|---|
| 时间 | 房屋信息采集时间 | 小区名 | 房屋所在小区(脱敏) |
| 小区房屋出租数量 | 小区房屋出租数量(脱敏,保留大小关系) | 楼层 | 楼层高中低(脱敏) |
| 总楼层 | 房屋所在建筑的总楼层数(脱敏) | 房屋面积 | 房屋面积(脱敏) |
| 房屋朝向 | 房屋朝向 | 居住状态 | 是否已经出租或居住中(脱敏) |
| 卧室数量 | 卧室数量 | 客厅数量 | 客厅数量 |
| 卫的数量 | 卫的数量 | 租出方式 | 表示是否整租 |
| 区 | 房屋所在区级行政单位(脱敏) | 位置 | 小区所在商圈(脱敏) |
| 地铁线路 | 第几条线路(脱敏) | 地铁站点 | 房屋临近站点(脱敏) |
| 距离 | 房屋距地铁站距离(脱敏) | 装修情况 | 房屋装修档次(脱敏) |
首先,我们大体熟悉一下数据集:
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
train.head()
train.info()
我们看到里面是存在缺失值的,而且有的特征缺失值似乎很多,我们需要进一步探索。
查看缺失值,并删除缺失率过高的特征
all_data_na = (train.isnull().sum()/len(train))*100
all_data_na=all_data_na.drop(all_data_na[all_data_na ==0].index).sort_values(ascending=False)
missing_data = pd.DataFrame({'数据缺失率' : all_data_na})
missing_data| 数据缺失率(%) 装修情况 90.591180 居住状态 89.753688 出租方式 87.671658 距离 53.302907 地铁站点 53.302907 地铁线路 53.302907 小区房屋出租数量0.509314 位置 0.015773 区 0.015773 |
直接将缺失率图像显示:
fig, axis = plt.subplots(figsize=(8,5))
plt.xticks(rotation='45')
sns.barplot(x=all_data_na.index, y=all_data_na)
plt.xlabel('Features', fontsize=10)
plt.ylabel('Percent of missing values', fontsize=10)
plt.title('Percent missing data by feature', fontsize=10)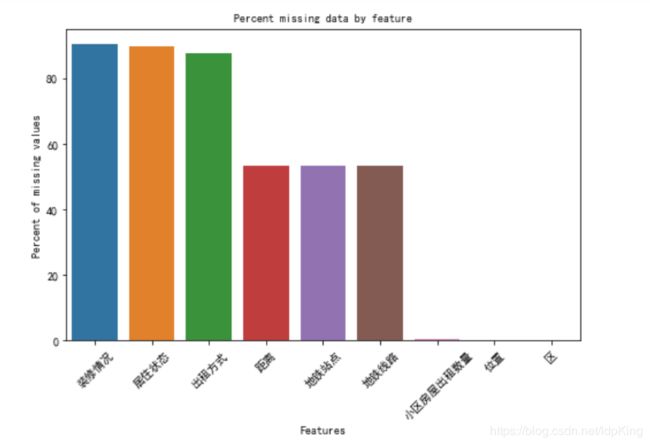
可以发现,装修状态、出租方式、居住状态3个特征变量缺失严重,缺失比例达80%,虽说这几个特征很重要,是影响月租金的强特,但是由于缺失值比较严重,不好插补,所以直接删除来处理。其余特征保留
train.drop(['装修情况','居住状态','出租方式'],axis=1,inplace=True)然后,查看各特征之间的相关关系
热力图
colnmns = train.columns.tolist()# 列表头
mcorr = train[colnmns].corr() # 相关系数矩阵,即给出了任意两个变量之间的相关系数
mask = np.zeros_like(mcorr, dtype=np.bool) # 构造与mcorr同维数矩阵 为bool型
mask[np.triu_indices_from(mask)] = True # 角分线右侧为True
plt.figure(figsize=(10, 6)) # 指定绘图对象宽度和高度
cmap = sns.diverging_palette(220, 10, as_cmap=True) # 返回matplotlib colormap对象
g = sns.heatmap(mcorr, mask=mask, cmap=cmap, square=False, annot=True, fmt='0.2f') # 热力图(看两两相似度)
plt.show()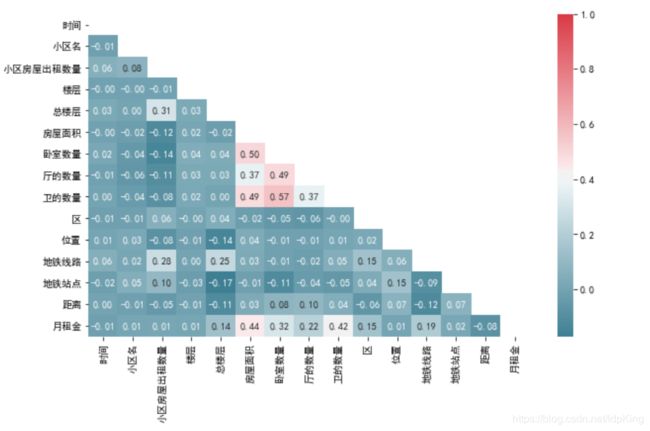
根据热力度,发现房屋面积、卧室数量、厅的数量、卫的数量与月租金的相关系数较大 ,其次是总楼层、区、地铁线路。其他特征的相关系数则较小。因此,我们着重考虑相关系数较大的特征。
房屋面积与月租金的分布
fig, axis = plt.subplots(1,2,sharey=True,figsize=(15,4))
axis[0].scatter(x=train['房屋面积'], y=train['月租金'])
#去掉异常值
train2 = train.drop(train[(train['房屋面积']>0.2) & (train['月租金']<20)].index)
axis[1].scatter(x=train2['房屋面积'], y=train2['月租金'])
plt.show()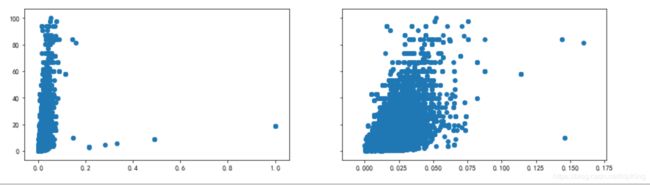
去掉异常值后,可以明显看出房屋面积与月租金呈正相关关系。
各个特征的分布曲线如下:
train.hist(figsize=(20, 15), bins=50, grid=False)
plt.show()
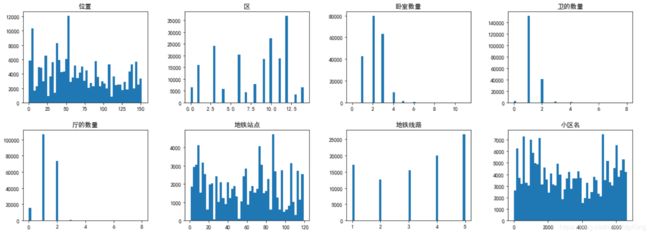
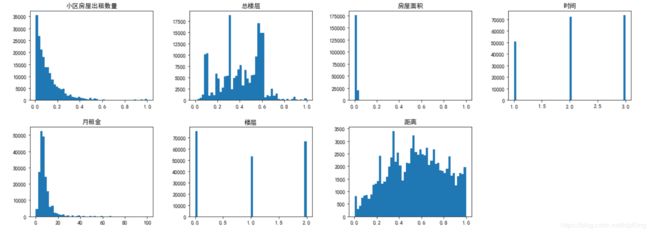
在大体了解了数据之间的关系及特征分布之后,接下来进入到特征工程部分。
特征工程
去掉缺失值过多的特征后,还有时间、小区名、小区房屋出租数量、楼层、总楼层、房屋面积、房屋朝向、卧室数量、厅的数量、卫的数量、区、位置、地铁线路、地铁站点、距离15个特征变量。 从热力图中我们已经发现,房屋面积、卧室数量、厅的数量、卫的数量这四个特征对租金价格影响较大。 在现实中,每个房屋的户型也很大程度上影响了房屋的月祖金,比如3室2厅和2室1厅租金是不一样的,所以要构造出卧室数量+厅的数量、卧室数量+卫的数量、厅的数量+卫的数量、及卧室+厅+卫的数量。
对房屋面积、卧室数量、厅的数量、卫的数量进行特征提取
根据这四个特征,我们又构造了11个特征:
train['卧室厅']=train['卧室数量']+train['厅的数量']
train['卧室卫']=train['卧室数量']+train['卫的数量']
train['厅卫']=train['厅的数量']+train['卫的数量']
train['卧厅卫']=train['卫的数量']+train['厅的数量']+train['卧室数量']
train['卧室占比']=train['卧室数量']/train['卧厅卫']
train['厅的占比']=train['厅的数量']/train['卧厅卫']
train['卫的占比']=train['卫的数量']/train['卧厅卫']
train['平均面积']=train['房屋面积']/train['卧厅卫']
train['卧室面积']=train['房屋面积']* train['卧室占比']
train['厅的面积']=train['房屋面积']* train['厅的占比']
train['卫的面积']=train['房屋面积']* train['卫的占比']
train['房屋面积'] = (train['房屋面积']*100)**2
train['卫的数量'] = (train['卫的数量']*10)**2
train['卧室数量']=(train['卧室数量']*10)**2
train['厅的数量']=(train['厅的数量']*10)*2
train['小区房屋出租数量']=train['小区房屋出租数量']*100原数据给了0、1、2来描述楼的高低程度,首先对其归一化并进行量化,然后与总楼层相乘可以推断出房屋所在的大体楼层
def fun(p):
if p==0:
r=0
elif p==1:
r=0.3333
elif p==2:
r=0.6666
return r
train['楼层']=train['楼层'].apply(lambda x:fun(x))
train['总楼层']=(train['总楼层']*100)**2
train['所在楼层']=train['总楼层']*train['楼层']地铁线路处理
train['地铁线路'].isnull().sum()
train['地铁线路'].value_counts()
train['地铁线路'] = train['地铁线路'].fillna(0)地铁线路存在104761条缺失值,value_counts()以后发现,存在1、2、3、4、5共五组数据,因此我们认为缺失值为没有地铁线路存在,填充0
地铁站点处理
sub = set(train['地铁站点'].value_counts().index)
sub_a = set(np.arange(1,120))
sub_nan = sub_a - sub
train['地铁站点'] = train['地铁站点'].fillna(60)地铁站点同样存在104761条缺失值,观察数据发现,其值为1-119之间的整数,但是唯独缺少了60这个数字,其他数字都存在。因此,我们将缺失值填充为60
区、位置处理、小区房屋出租数量
train['区'] = train['区'].fillna(5)
train['位置'] = train['位置'].fillna(76)
train['小区房屋出租数量'] = train['小区房屋出租数量'].fillna(train['小区房屋出租数量'].mode()[0])
train.drop(['距离'], axis=1, inplace=True)同样,区的缺失值较少,值为0-14之间的整数,但是也唯独缺少了5,因此填充为5。位置值为0-152,唯独缺少76,填充76。
小区房屋出租数量缺失了31条,不多,不影响主要结果,可以删掉这31条,或者拿众数填充,我用众数填充了一下。
距离属性缺失太多,104761条缺失,而且不是分类变量,无法填充,删掉。
小区名处理
房屋面积和地铁线路处理完后,接下来针对小区名进行处理。小区名在整个特征里面其实重要性非常大,因为同一个小区的房屋租金价格基本相似,而不同小区之间的价格差别很大.
但是训练集中共存在5547个小区,做one-hot处理或者直接不处理都是不可行的。one-hot处理后特征爆炸,直接不处理更不妥,因其为分类变量,无大小关系之分,必须要进行处理。
因此,我们根据小区名与其他特征的关系重新构造了新特征:
小区名与该小区的出租房屋面积、小区卧室出租数量、小区厅的出租数量、小区卫的出租数量、小区总楼层之间构造特征
items=['房屋面积','卧室数量','厅的数量','卫的数量','总楼层']
train_add = train
for item in items:
xiaoquname_mean=train.groupby('小区名',as_index=False)[item].agg({item+'mean小区名':'mean'})
train_add = train_add.merge(xiaoquname_mean,on='小区名',how='left') 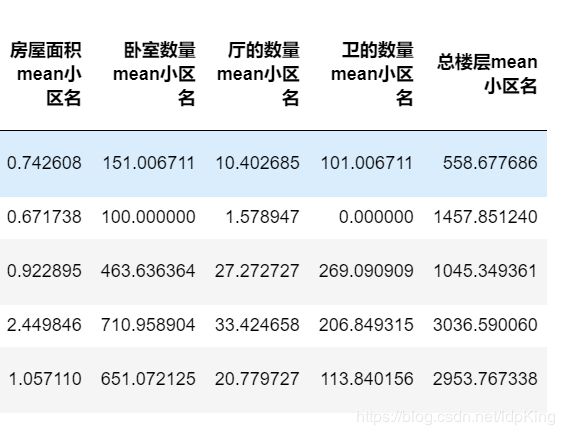
重新构造的特征,显示了该小区的平均出租房屋面积、卧室数量、厅的数量、卫的数量以及总楼层 ,这些特征,大体可以将小区之间区别开来,而且特征已经变为连续型数据,不再是分类标签。
位置与该小区的出租房屋面积、小区卧室出租数量、小区厅的出租数量、小区卫的出租数量、小区总楼层之间构造特征
同样,位置特征存在152个类别,依然需要处理一下。与小区名同样的处理方式。
for item in items:
xiaoquloc_mean=train.groupby('位置',as_index=False)[item].agg({item+'mean位置':'mean'})
train_add = train_add.merge(xiaoquloc_mean,on='位置',how='left') 然后,将小区名特征去掉
train_add.drop(['小区名'], axis=1, inplace=True)房屋朝向
训练集数据中,房屋朝向种类太多,主要原因是有的房间存在多个朝向,甚至有的房间东南西北四个朝向都有。因此我们按照第一个给出的方向处理。或者按照方向里面是否存在南朝向(此处处理方法很多,自我感觉我的处理方法存在欠缺,但是也想不出更好的处理方式,此处有待提高)
train_add['房屋朝向'] = train_add['房屋朝向'].apply(lambda x: x.split(' ')[0])接下来,就要对一些分类特征(类别有限且唯独维度不爆炸)做one-hot处理
对区,房屋朝向,地铁线路三个特征进行处理。
#虚拟变量编码处理
ordinal_cols = ['区', '房屋朝向','地铁线路']
for col in ordinal_cols:
dummies = pd.get_dummies(train_add[col], drop_first=False)
dummies = dummies.add_prefix("{}#".format(col))
train_add.drop(col, axis=1, inplace=True)
train_add = train_add.join(dummies)至此,我们一共得到了61个特征。当然,这61个特征不可能全用,需要筛选一下,无用的需要去掉,同时,也要防止过拟合。具体的特征再筛选再这里就不再详细描述了,比较繁琐。
['时间', '小区房屋出租数量', '楼层', '总楼层', '房屋面积', '卧室数量', '厅的数量', '卫的数量', '位置',
'月租金', '卧室厅', '卧室卫', '厅卫', '卧厅卫', '卧室占比', '厅的占比', '卫的占比', '平均面积',
'卧室面积', '厅的面积', '卫的面积', '所在楼层', '房屋面积mean小区名', '卧室数量mean小区名',
'厅的数量mean小区名', '卫的数量mean小区名', '总楼层mean小区名', '房屋面积mean位置', '卧室数量mean位置',
'厅的数量mean位置', '卫的数量mean位置', '总楼层mean位置', '区#0.0', '区#1.0', '区#2.0',
'区#3.0', '区#4.0', '区#5.0', '区#6.0', '区#7.0', '区#8.0', '区#9.0', '区#10.0',
'区#11.0', '区#12.0', '区#13.0', '区#14.0', '房屋朝向#东', '房屋朝向#东北', '房屋朝向#东南',
'房屋朝向#北', '房屋朝向#南', '房屋朝向#西', '房屋朝向#西北', '房屋朝向#西南', '地铁线路#0.0',
'地铁线路#1.0', '地铁线路#2.0', '地铁线路#3.0', '地铁线路#4.0', '地铁线路#5.0']模型训练
接下来就是模型的训练以及参数的调整了。
可以用train_test_split或者交叉验证来进行参数选取,具体使用哪个根据特定情况决定。
模型个人推荐使用lgb或者xgboost等集成模型,有时候随机森林表现效果也不错,可选其做一个基准模型。
以上基本就是整个过程,有问题还请大家批评指出。码字不易,多多支持!感谢!