想玩转工业界机器学习?先学Spark吧
正文共5145个字,16张图,预计阅读时间13分钟。
关于大数据,有这样段话:
“Big data is like teenage sex,everyone talks about it,nobody really knows how to do it,everyone thinks everyone else is doing it,so everyone claims they are doing it.”
作为一名学生,如何还没听说过Spark这套计算框架,那么我觉得还是留在学术界的机器学习混吧,工业界现在也许还不适合你。
在学术界,数据一般都是别人处理好的公开数据集,而我们只是在上面实践学术界的算法,在工业界可没人给你把业务数据都给你准备好...
众所周知,机器学习和统计学技术是把大数据转化为行为知识的关键技术,此外,机器学习者常言道:你能掌控的数据量决定了你模型最终所能达到效果上限,不断优化的模型只是为了不断的接近这个上限而已。

数据和算法之间的关联,一个是血液,一个是心脏。
信息时代,大部分顶层的互联网公司都积累了海量的数据,能掌控的数据量是你模型最终能接近最好效果的很重要的一个要素之一,对于工业界的业机器学习算法工程师,除了明白学术界的机器学习原理、优化理论以及实现各种单机版小demo外…..要想真正的能解决实际的业务问题,那就必须具备处理、利用海量业务数据的能力,而Spark正是赋予我们掌控大数据能力的利器。
拥有的数据量,不等于你能掌控的数据量,学习Spark,赋予你掌控大数据的能力!
数据和算法之间的关联,一个是血液,一个是心脏。
看看相关职位的需求…..

工业界需要Spark
我曾经接触的两个公司的推荐部门都是基于scala(python)+spark+hadoop平台工作的,由此可见,Spark在机器学习的工业领域是非常重要的技能之一!
总之,想将来从事机器学习相关工作的朋友们,开始学Spark吧!

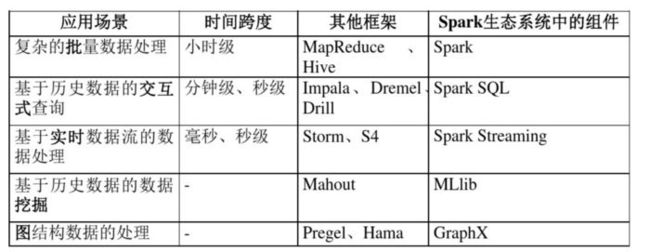
Spark与大数据
Spark是继Hadoop之后的下一代分布式内存计算引擎,于2009年诞生于加州大学伯克利分校AMPLab实验室,现在主要由Databricks公司进行维护。是当今大数据领域最活跃、最热门、最高效的大数据通用计算平台。
官方定义:spark是一个通用的大数据处理引擎,可以简单的理解为一个大数据分布式处理框架。
相比于传统的以hadoop为基础的第一代大数据技术生态体系来说,Spark性能更好(快速)、可扩展性更高(技术栈)。
Spark的特点
2006年项目成立的一开始,“Hadoop”这个单词只代表了两个组件——HDFS和MapReduce。到现在的10个年头,这个单词代表的是“核心”(即Core Hadoop项目)以及与之相关的一个不断成长的生态系统。这个和Linux非常类似,都是由一个核心和一个生态系统组成。
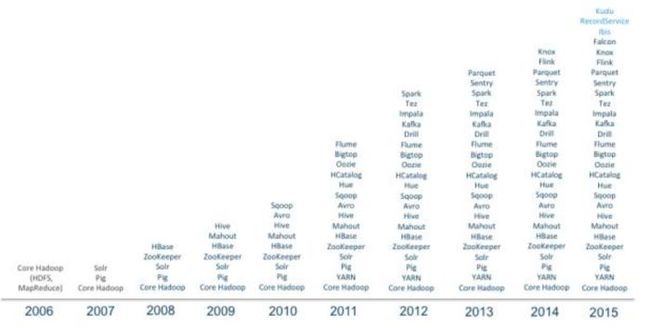
Hadoop发展历程
现在Hadoop在一月发布了2.7.2的稳定版, 已经从传统的Hadoop三驾马车HDFS,MapReduce和HBase社区发展为60多个相关组件组成的庞大生态,其中包含在各大发行版中的组件就有25个以上,包括数据存储、执行引擎、编程和数据访问框架等。
Hadoop在2.0将资源管理从MapReduce中独立出来变成通用框架后,就从1.0的三层结构演变为了现在的四层架构:

Hadoop的框架
底层——存储层,文件系统HDFS
中间层——资源及数据管理层,YARN以及Sentry等
上层——MapReduce、Impala、Spark等计算引擎
顶层——基于MapReduce、Spark等计算引擎的高级封装及工具,如Hive、Pig、Mahout等等
有了Hadoop为什么还需要spark?
肯定Spark有比Hadoop的MR计算更好的优势,好在如下方面:
(1)为什么高效?
1、相对于Hadoop的MR计算,Spark支持DAG,能缓存中间数据,减少数据落盘次数;
2、使用多线程启动task,更轻量,任务启动快。计算速度理论上有10-100倍提升。(根据个人工作验证,计算效率相对Hadoop至少是3倍以上)
3、高度抽象API,代码比MR少2-5倍甚至更多,开发效率高
(2)为什么多框架整合?
相对于过去使用Hadoop + Hive + Mahout + Storm 解决批处理、SQL查询和实时处理和机器学习场景的大数据平台架构,其最大的问题在于不同框架语言不同,整合复杂,同时也需要更多维护成本。
而使用Spark在Spark core的批处理基础上,建立了Spark Sql、Spark Streaming,Spark Mllib,Spark GraphX来解决实时计算,机器学习和图计算场景,方便将不同组件功能进行整合,同时维护成本小。
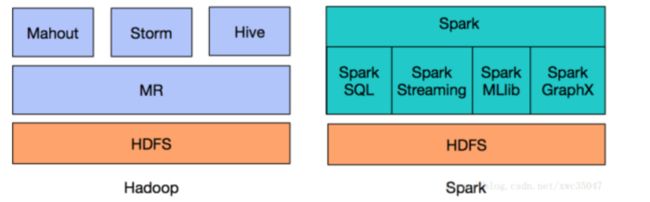
Spark与Hadoop对比
因为传统的hadoop的MapReduce具有高延迟的致命缺点,无法处理高时效性的数据。hadoop本身的计算模型就决定了,hadoop上的所有工作都需要转换为Map、Shuffle、Reduce等核心阶段,由于每次计算都需要从磁盘读写数据,同时整个模型都需要网络传输,这就导致了不可改变的延迟。而spark的出现,让hadoop也没有时间、也没有必要再重构自己。当然hadoop作为一个技术体系,spark主要是替代其Map/Reduce的功能,hadoop的HDFS功能还是被与spark结合起来使用。

Spark的特点
spark的成本
Spark 和 Hadoop MapReduce 都是开源的,但是机器和人工的花费仍是不可避免的。
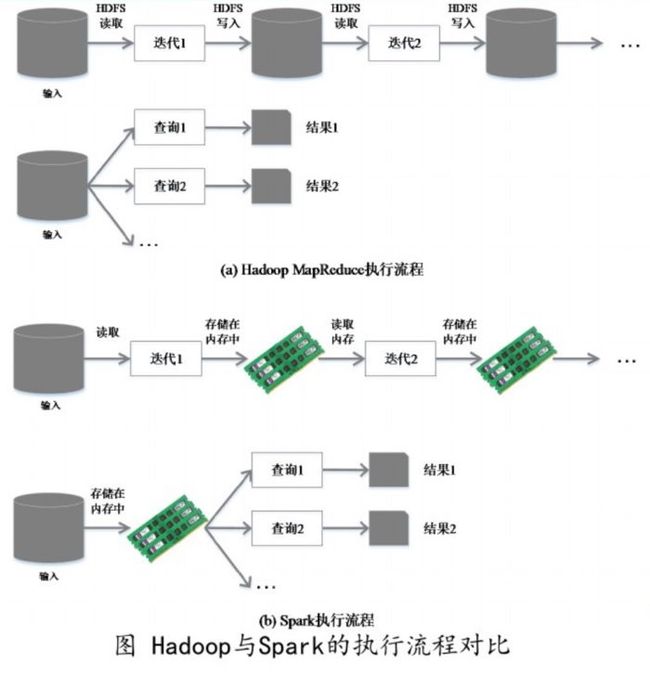
Spark与Hadoop的硬件差异
Spark 集群的内存至少要和需要处理的数据块一样大,因为只有数据块和内存大小合适才能发挥出其最优的性能。所以如果真的需要处理非常大的数据,Hadoop 是合适之选,毕竟硬盘的费用要远远低于内存的费用。
考虑到 Spark 的性能标准,在执行相同的任务的时候,需要的硬件更少而运行速度却更快,因此应该是更合算的,尤其是在云端的时候,此时只需要即用即付。
更准确地说,Spark是一个计算框架,而Hadoop中包含计算框架MapReduce和分布式文件系统HDFS,Hadoop更广泛地说还包括在其生态系统上的其他系统,如Hbase、Hive等。Spark是MapReduce的替代方案,而且兼容HDFS、Hive等分布式存储层,可融入Hadoop的生态系统,以弥补缺失MapReduce的不足。
Spark与Hadoop在数据中间数据处理区别:

Spark架构采用了分布式计算中的Master-Slave模型。Master是对应集群中的含有Master进程的节点,Slave是集群中含有Worker进程的节点。Master作为整个集群的控制器,负责整个集群的正常运行;Worker相当于是计算节点,接收主节点命令与进行状态汇报;Executor负责任务的执行;Client作为用户的客户端负责提交应用,Driver负责控制一个应用的执行。

Spark调度模块
Spark集群部署后,需要在主节点和从节点分别启动Master进程和Worker进程,对整个集群进行控制。在一个Spark应用的执行过程中,Driver和Worker是两个重要角色。Driver程序是应用逻辑执行的起点,负责作业的调度,即Task任务的分发,而多个Worker用来管理计算节点和创建Executor并行处理任务。在执行阶段,Driver会将Task和Task所依赖的file和jar序列化后传递给对应的Worker机器,同时Executor对相应数据分区的任务进行处理。
下面详细介绍Spark的架构中的基本组件。
1、ClusterManager:在Standalone模式中即为Master(主节点),控制整个集群,监控Worker。在YARN模式中为资源管理器。
2、Worker:从节点,负责控制计算节点,启动Executor或Driver。在YARN模式中为NodeManager,负责计算节点的控制。
3、Driver:运行Application的main()函数并创建SparkContext。
4、Executor:执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executors。
5、SparkContext:整个应用的上下文,控制应用的生命周期。
6、RDD:Spark的基本计算单元,一组RDD可形成执行的有向无环图RDD Graph。
7、DAG Scheduler:根据作业(Job)构建基于Stage的DAG,并提交Stage给TaskScheduler。
8、TaskScheduler:将任务(Task)分发给Executor执行。
9、SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。SparkEnv内创建并包含如下一些重要组件的引用。
10、MapOutPutTracker:负责Shuffle元信息的存储。
11、BroadcastManager:负责广播变量的控制与元信息的存储。
12、BlockManager:负责存储管理、创建和查找块。
13、MetricsSystem:监控运行时性能指标信息。
14、SparkConf:负责存储配置信息。
Spark的整体流程为:Client提交应用,Master找到一个Worker启动Driver,Driver向Master或者资源管理器申请资源,之后将应用转化为RDD Graph,再由DAGScheduler将RDD Graph转化为Stage的有向无环图提交给TaskScheduler,由TaskScheduler提交任务给Executor执行。在任务执行的过程中,其他组件协同工作,确保整个应用顺利执行。
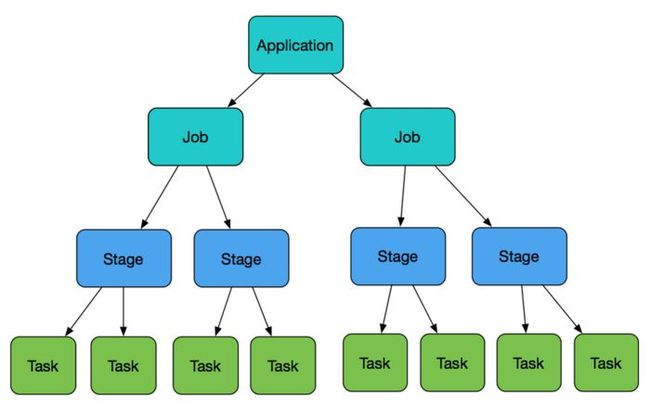
Spark作业层次划分
Application就是用户submit提交的整体代码,代码中又有很多action操作,action算子把Application划分为多个job,job根据宽依赖划分为不同Stage,Stage内划分为许多(数量由分区决定,一个分区的数据由一个task计算)功能相同的task,然后这些task提交给Executor进行计算执行,把结果返回给Driver汇总或存储。
下面看一下使用Spark解决一个HelloWord入门级别的Spark程序代码,比写Hadoop里面的Map/Reduce代码简单多了....
# 统计单词的词频 val rdd = sc.textFile("/home/scipio/README.md") val wordcount = rdd.flatMap(_.split(' ')).map((_,1)).reduceByKey(_+_) val wcsort = wordcount.map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1)) wcsort.saveAsTextFile("/home/scipio/sort.txt")
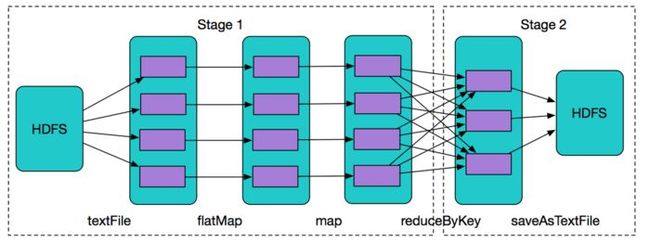
Spark执行过程
上图是一个Spark的wordcount例子,根据上述stage划分原则,这个job划分为2个stage,有三行,分别是数据读取、计算和存储过程。
仅看代码,我们根本体会不到数据在背后是并行计算。从图中能看出数据分布在不同分区(集群上不同机器上),数据经过flapMap、map和reduceByKey算子在不同RDD的分区中流转。(这些算子就是上面所说对RDD进行计算的函数),后面有空再介绍一下自己总结的Spark常用的算子以及Scala函数(https://www.jianshu.com/p/addc95d9ebb9)。
推荐Spark官网中文翻译版入门学习资料:http://spark.apachecn.org/docs/cn/2.2.0/sql-programming-guide.html
原文链接:https://www.jianshu.com/p/b848865e5299
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看
LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础
![]()