分片配置的目的显而易见:就是将数据库分片规则和策略告诉sharding-jdbc
sharding-jdbc需要知道如下信息:
(1)哪些表需要分片
(2)需要分成哪些库?哪些表?名字分别是什么
(3)通过哪个字段(或哪些字段)进行分库分表
(4)具体的分库或分表算法什么怎样的
(5)分片规则和策略相关的一组表怎么处理
刚开始看官方的小例子,分片配置的代码有些懵逼,梳理了一下,需要如下类进行实现
DataSourceRule
TableRule
BindingTableRule
ShardingRule
这些对象的创建次序轴是这样的:
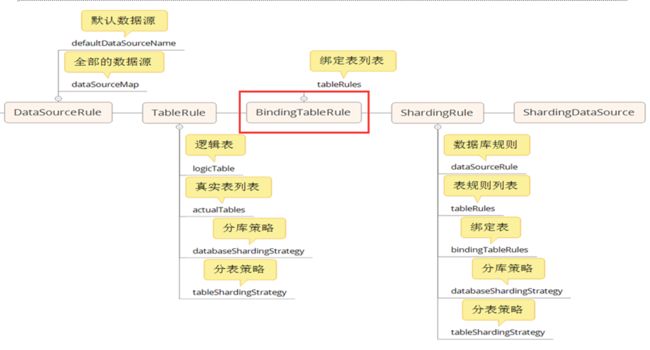
先看DataSourceRule
这个类可以理解为:存放所有被拆分的数据库对象和默认数据源的名称
这个类一共有两个属性:
(1)defaultDataSourceName:默认数据源的名字,那些不需要分片的数据表放到这个数据源中
(2)dataSourceMap:全部的数据源对象(DataSource),这是一个map结构,key:数据库的名字,value:数据源对象(DataSource)
public DataSourceRule(final Map dataSourceMap, final String defaultDataSourceName) {
Preconditions.checkState(!dataSourceMap.isEmpty(), "Must have one data source at least.");
this.dataSourceMap = dataSourceMap;
if (1 == dataSourceMap.size()) {
this.defaultDataSourceName = dataSourceMap.entrySet().iterator().next().getKey();
return;
}
if (Strings.isNullOrEmpty(defaultDataSourceName)) {
this.defaultDataSourceName = null;
return;
}
Preconditions.checkState(dataSourceMap.containsKey(defaultDataSourceName), "Data source rule must include default data source.");
this.defaultDataSourceName = defaultDataSourceName;
}
上面是构造函数,比较简单,做下面几件事情:
(1)数据源map不能为空,否则抛异常
(2)如果map的大小为1,默认数据源的名字就是这个唯一的数据源,可以理解为不分库只分表,或不分库分表
(3)如果存在默认数据源,则要判断这个数据源是否存在于map中
这个类的其它方法比较简单,通过注释就能明白什么意思
TableRule
这个对象用来存放逻辑表、所有的分片最小单位(DataNode)、分库策略、分表策略、是否动态表,下面分表解释含义:
(1)逻辑表:这个简单不解释
(2)分片最小单位:比如db_0.order_1,这个最小单位是通过计算来生成的,后面会讲到
(3)分库策略:定义分库算法的类
(4)分表策略:定义分表算法的类
(5)是否为动态表:表示实际表的名字和个数无法确认,是动态变化的,无法在程序中静态配置。比如:真实表的名称随着时间的推移会产生变化。
/**
* 全属性构造器.
*
* 用于Spring非命名空间的配置.
*
* 未来将改为private权限, 不在对外公开, 不建议使用非Spring命名空间的配置.
*
* @deprecated 未来将改为private权限, 不在对外公开, 不建议使用非Spring命名空间的配置.
*/
@Deprecated
public TableRule(final String logicTable, final boolean dynamic, final List actualTables, final DataSourceRule dataSourceRule, final Collection dataSourceNames,
final DatabaseShardingStrategy databaseShardingStrategy, final TableShardingStrategy tableShardingStrategy) {
Preconditions.checkNotNull(logicTable);
this.logicTable = logicTable;
this.dynamic = dynamic;
this.databaseShardingStrategy = databaseShardingStrategy;
this.tableShardingStrategy = tableShardingStrategy;
if (dynamic) {
Preconditions.checkNotNull(dataSourceRule);
this.actualTables = generateDataNodes(dataSourceRule);
} else if (null == actualTables || actualTables.isEmpty()) {
Preconditions.checkNotNull(dataSourceRule);
this.actualTables = generateDataNodes(Collections.singletonList(logicTable), dataSourceRule, dataSourceNames);
} else {
this.actualTables = generateDataNodes(actualTables, dataSourceRule, dataSourceNames);
}
}
这个是构造函数的代码:
(1)前几行比较简单,就是根据入参设置属性值
(2)紧接着是生成DataNode的代码
(3)如果是动态表,生成的DataNode只有数据源,表的名字没有
(4)如果真实表为空,则把逻辑表名作为真实表名(只分库不分表或不分库分表)
(5)其它情况,就会根据所有的数据源和真实表,通过笛卡尔积计算生成最小分片单元(DataNode)
/**
* 根据数据源名称过滤获取真实数据单元.
*
* @param targetDataSources 数据源名称集合
* @param targetTables 真实表名称集合
* @return 真实数据单元
*/
public Collection getActualDataNodes(final Collection targetDataSources, final Collection targetTables) {
return dynamic ? getDynamicDataNodes(targetDataSources, targetTables) : getStaticDataNodes(targetDataSources, targetTables);
}
上面这个方法是根据数据源列表和真实表列表获取最小分片单元。
这个方法会在分库和分表策略计算完毕后,得到路由到的数据库列表和数据表列表,但是不知道数据表和数据库的对应关系(这边表属于哪个数据库),通过这个方法来获取最小分片单元
这个方法会分两种情况
(1)如果是动态分表,则会拿这些需要路由的表和所有的分库做笛卡尔积计算(也就是说动态表这种场景,分多少个库一定是确定的,并且表要在每个库都动态新增)
(2)不是动态分表,会计算出这些数据库和数据表的真实对应关系
这个地方不太好理解,举个例子:
比如分了两个库,db0和db1,这个两个库中分别有下面这些表:
db0:order0,order1,order2
db1:order3,order4,order5
经过分库分表计算后,得到的结果是:需要查询两个库:db0和db1,两张表:order1和order5,我怎么知道order1是属于db0的,二order5是属于db1的呢?就是通过这个方法来计算
/**
* 根据数据源名称过滤获取真实表名称.
*
* @param targetDataSources 数据源名称
* @return 真实表名称
*/
public Collection getActualTableNames(final Collection targetDataSources) {
Collection result = new LinkedHashSet<>(actualTables.size());
for (DataNode each : actualTables) {
if (targetDataSources.contains(each.getDataSourceName())) {
result.add(each.getTableName());
}
}
return result;
}
这个方法比较好理解,根据数据源名字获取这些数据源下面的所有真实表的名字
当进行了分库计算,再进行分表计算时,我只需要获取这些数据源下面的真实表,缩小了范围
int findActualTableIndex(final String dataSourceName, final String actualTableName) {
int result = 0;
for (DataNode each : actualTables) {
if (each.getDataSourceName().equals(dataSourceName) && each.getTableName().equals(actualTableName)) {
return result;
}
result++;
}
return -1;
}这个方法是根据数据源名字和表名字获取这个分片单元在actualTables中的索引,这个用于确定绑定表,讲绑定表时会详细讲解
BindingTableRule
如果两张表在任何场景下,分片规则完全一样,我们可以对这两张表进行绑定,这两张表互为绑定表,例如订单表和子订单表。关联表查询时,可以显著的提高查询效率,避免笛卡尔积查询。
这个对象只有一个属性:tableRules,这个列表中的表互为绑定表
/**
* 根据其他Binding表真实表名称获取相应的真实Binding表名称.
*
* @param dataSource 数据源名称
* @param logicTable 逻辑表名称
* @param otherActualTable 其他真实Binding表名称
* @return 真实Binding表名称
*/
public String getBindingActualTable(final String dataSource, final String logicTable, final String otherActualTable) {
int index = -1;
for (TableRule each : tableRules) {
if (each.isDynamic()) {
throw new UnsupportedOperationException("Dynamic table cannot support Binding table.");
}
index = each.findActualTableIndex(dataSource, otherActualTable);
if (-1 != index) {
break;
}
}
Preconditions.checkState(-1 != index, String.format("Actual table [%s].[%s] is not in table config", dataSource, otherActualTable));
for (TableRule each : tableRules) {
if (each.getLogicTable().equals(logicTable)) {
return each.getActualTables().get(index).getTableName();
}
}
throw new IllegalStateException(String.format("Cannot find binding actual table, data source: %s, logic table: %s, other actual table: %s", dataSource, logicTable, otherActualTable));
}
一个sql语句中,如果几个表关联查询,并且这几个表互为绑定表,其中一个表进行了分片计算,其它表就不需要再次进行分片计算(绑定表的分片规则一样),就需要根据主表计算出其它表的真实名字,上面的方法就实现这个功能
(1)获取绑定表主表(已经进行了分片计算的表)位于actualTables中的索引
(2)根据索引和逻辑表名字获取绑定表子表名
绑定表的一个坑(版本1.3.1):
order和sub_order是绑定表,都以order_id进行分表。
写法一(正确的写法):SELECT * FROM order,sub_order WHERE order.order_id = sub_order.order_id and order.order_id = ?
写法二(错误的写法):SELECT * FROM sub_order,order WHERE order.order_id = sub_order.order_id and order.order_id = ?
写法二会导致不进行分表计算,很容易造成陷阱,可能是因为选主的算法,FROM后面的第一个表认为是主表,所用的绑定表的分库分别规则都以主表为准。所以写法二认为主表是sub_order,但是where条件中却是order.order_id,所以就不进行分表计算。
ShardingRule
这个对象会汇总DataSourceRule、TableRule、BindingTableRule、分表策略、分库策略
这个对象的构造方法中会传入DataSourceRule,TableRule对象中的构造方法中也有这个参数,
(1)在ShardingRule中,数据源对象会被存放起来,供后面使用。
(2)在TableRule中数据源对象是用来计算最小分片单元的。
这个对象中会设置分库和分表策略,TableRule中同样也有,优先级TableRule更高