JDK源码阅读——ArrayList\LinkedList
ArrayList (动态数组)
javaDoc
1.可变数组,允许null值存入.性能比LinkedList好?后文会做一个时间复杂度的比较
2.每个ArrayList实例都有一个容量capacity,这个容量就是数组的size,通常这个
capacity不小于ArryList的size. 随着元素的不断加入,ArrayList的capacity自动增涨
可以提前预设ArrayList的capacity,这样比自动增涨的内存分配更有效的降低内存使用
3.ArrayList与HashMap一样,非线程安全,实现了fail-fast机制
关于 fail-fast:
建议先看一下下边的文章,理解fail-fast机制(也就是说ArrayList是非线程安全的原因)
http://blog.csdn.net/lemon89/article/details/50994691
成员变量(field)
/**
* arrayList使用数组实现,所以我们常把它叫做可变数组
*/
private transient Object[] elementData;
/**
* size就是arryList实际的容量, 但这个size不一定等于elementDate的 length.比如,remove一个元素,
* 时间是把elementData数组中对应的元素置为null, 同时size--
*/
private int size;* transient Object[] elementData:transient关键字*
表示序列化该对象时忽略这个对象中的某个成员变量,可以看一些什么是序列化反序列化,并且为什么这样做
ArrayList主要方法
容量的拓展将导致数组元素的复制,多次拓展容量将执行多次整个数组内容的复制。若提前能大致判断list的长度,调用ensureCapacity调整容量,将有效的提高运行速度。
/**
*
* 返回当前ArrayList的浅拷贝(ArrayList中的具体元素只不过是指向同一个内存地址)
*
* 因为其实现使用System.arraycopy,只是引用的拷贝
*
* Returns a shallow copy of this ArrayList instance. (The elements
* themselves are not copied.)
*
* @return a clone of this ArrayList instance
*/
public Object clone() {
try {
ArrayList v = (ArrayList) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError();
}
} public boolean add(E e) {
//add之前做校验,如果发现已经达到数组的length,那么扩大至1.5倍。
//new length=length+length*0.5
ensureCapacity(size + 1); // 扩大数组length,并把原有元素拷贝到新数组中,原有元素末尾加入新增元素e,
// Increments modCount!!
elementData[size++] = e;
return true;
} /*
* Private remove method that skips bounds checking and does not return the
* value removed.
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index, numMoved);
elementData[--size] = null; // Let gc do its
// work;gc回收索引原有对象,但是gc并不会改变size的值,而是手动把这个size减小。也就是说这个elementDate的实际length,并不是size
} /**
* Removes all of the elements from this list. The list will be empty after
* this call returns.
*/
public void clear() {
modCount++;
// Let gc do its
// work.gc回收索引原有对象,但是gc并不会改变size的值,而是手动把这个size减小。也就是说这个elementDate的实际length,并不是size
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
ArrayList 总结:
什么是数组
顺序表的实现,一种线性的,通过在内存中分配一片连续的内存地址,用来存储数据的数据结构
为什么说ArrayList是可变数组
其实数组是不可变的,只不过是初始化新的数组,然后把原有数组中元素的引用,放到新的数组中.
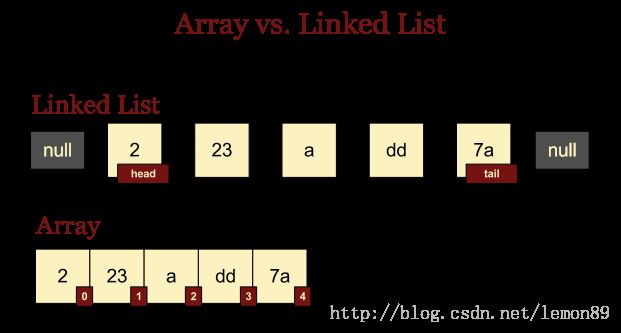
LinkedList
(值得一看,比ArrayList有趣)
/**
*
* 1.实现了List接口,并实现了List的所有操作,允许放入任何元素类型(包括null).
*
* 这个类实现了Deque接口,什么是Deque?
* 双端队列(deque,全名double-ended
* queue)是一种具有Queue队列和Stack栈性质的数据结构。双端队列中的元素可以从两端弹出,插入和删除操作限定在队列的两邊进行。
*deque不仅具有队列的FIFO特点:从尾部增加新元素,从头部获取元素
还具有栈的LIFO特:从头部获取、插入元素
*
* Stack 栈的基本特点:
*
* (1),先入后出,后入先出。 push、pop操作实现了LIFO
* (2),除头尾节点之外,每个元素有一个前驱元素,一个后继元素。
*
*
* 4.以上所诉的数据结构共同构成了LinkedList循环双向链表( doubly-linked list)的实现:
*
* 双向链表:
* 双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱(当此“连接”为最后一个“连接”时,指向空值或者空列表,当此“
* 连接”为第一个“连接”时,指向空值或者空列表)。所以,从双向链表中的任意一个结点开始, 都可以很方便地访问它的前驱结点和后继结点。
*
* 与我们常用的HashMap\ArrayList一样,LinkedList也是线程不安全的,实现了fail-fast机制关于fail-fast详见
* http:blog.csdn.net/lemon89/article/details/50994691
*
*/
public class LinkedListSourceCode extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable {
private transient Entry header = new Entry(null, null, null);
// LinkedList.Entry对象实现了双向链表结构,详见Entry对象解释
private transient int size = 0;
public LinkedList() {
// 初始化,前驱指针、后继指针都指向这个heade 对象本身
//值得注意的是header只是一个有两个指针的对象,并没有实际的存储数据,
//这点与其他LinkedList中的其他Entry不同。结合Entry代码理解,接着看吧
header.next = header.previous = header;
}
/**
* Returns the first element in this list.
*
* @return the first element in this list
* @throws NoSuchElementException
* if this list is empty
*/
public E getFirst() {
if (size == 0)
throw new NoSuchElementException();
return header.next.element;// 值得注意的是header只是一个有两个指针的对象,并没有实际的存储数据.所以
// header.next.element就是第一个元素
}
public E getLast() {
if (size == 0)
throw new NoSuchElementException();
return header.previous.element;// 双向循环链表的特点(循环),详细看HashMap.Entry的实现,header.previous总是指向最后一个元素
}
public E removeFirst() {
// 双向循环链表的特点(循环),
// 详细看HashMap.Entry的实现:header.previous总是指向最后一个元素,header.next指向第一个元素
return remove(header.next);
}
public E removeLast() {
return remove(header.previous);
// 双向循环链表的特点(循环),
// 详细看HashMap.Entry的实现:header.previous总是指向最后一个元素,header.next指向第一个元素
}
public void addFirst(E e) {
addBefore(e, header.next);// 双向循环链表的特点(循环),
// 详细看HashMap.Entry的实现:header.previous总是指向最后一个元素,header.next指向第一个元素
}
public void addLast(E e) {
addBefore(e, header);// 双向循环链表的特点(循环),详细看HashMap.Entry的实现:header.previous总是指向最后一个元素,header.next指向第一个元素
}
public boolean add(E e) {
addBefore(e, header);// 时间复杂度O(1),详见addBefore
return true;
}
public boolean remove(Object o) {
// e != header其实就是说LinkedList.size>0;删除第一次遇到的满足条件的元素
// 从头依次遍历链表,时间复杂度O(n)
if (o == null) {
for (Entry e = header.next; e != header; e = e.next) {
if (e.element == null) {
remove(e);
return true;
}
}
} else {
for (Entry e = header.next; e != header; e = e.next) {
if (o.equals(e.element)) {
remove(e);
return true;
}
}
}
return false;
}
public boolean addAll(Collection c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection c) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + size);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
modCount++;
// 1.如果index==size,则从链表末端循环插入元素
// 2.如果index!=size,则从entry(index)元素后边插入元素
// 很简单,没什么好说的,画图试一下加深理解
Entry successor = (index == size ? header : entry(index));
for (int i = 0; i < numNew; i++) {
Entry e = new Entry((E) a[i], successor, predecessor);
predecessor.next = e;
predecessor = e;
}
successor.previous = predecessor;
size += numNew;
return true;
}
public void clear() {
Entry e = header.next;
while (e != header) {// 当e == header,也就是说链表循环一圈,到了header起点
Entry next = e.next;
e.next = e.previous = null;
e.element = null;
e = next;
}
header.next = header.previous = header;// 始终维护了这个没有element的Header
size = 0;
modCount++;
}
// Positional Access Operations
public E get(int index) {
return entry(index).element;
}
public E set(int index, E element) {
Entry e = entry(index);
E oldVal = e.element;
e.element = element;
return oldVal;
}
private Entry entry(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + size);
Entry e = header;
// 为了减少链表遍历的次数,如果index 在 size/2之前的位置,那么从头遍历,直到size/2位置结束遍历
// 如果index 在 size/2之后的位置,那么从尾遍历,直到index位置结束遍历
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}
return e;
}
// Search Operations
public int indexOf(Object o) {// 与entry(int index)类似,不做解释
int index = 0;// 0就是第一个元素的位置
if (o == null) {
for (Entry e = header.next; e != header; e = e.next) {
if (e.element == null)
return index;
index++;
}
} else {
for (Entry e = header.next; e != header; e = e.next) {
if (o.equals(e.element))
return index;
index++;
}
}
return -1;
}
public int lastIndexOf(Object o) {// 与前边遍历类似,只不过从尾部遍历,不做解释
int index = size;
if (o == null) {
for (Entry e = header.previous; e != header; e = e.previous) {
index--;
if (e.element == null)
return index;
}
} else {
for (Entry e = header.previous; e != header; e = e.previous) {
index--;
if (o.equals(e.element))
return index;
}
}
return -1;
}
// Queue operations.
public E peek() {// 实现队列的操作,FIFO,当然是取第一个getFirst()
if (size == 0)// 如果LinkedList没有元素,返回null
return null;
return getFirst();
}
public E element() {
// 实现队列的操作,FIFO,当然是取第一个getFirst();
// 与peek()不同的是,如果LinkedList没有元素,则抛出异常而不是返回null
return getFirst();
}
public E poll() {
if (size == 0)// 如果LinkedList没有元素,返回null
return null;
return removeFirst();
}
public E remove() {
return removeFirst();
}
public boolean offer(E e) {
return add(e);
}
// Deque operations
public boolean offerFirst(E e) {// 双端队列Deque的实现,也就是头尾都可以操作
addFirst(e);
return true;
}
public boolean offerLast(E e) {
addLast(e);
return true;
}
public E peekFirst() {
if (size == 0)
return null;
return getFirst();
}
public E peekLast() {
if (size == 0)
return null;
return getLast();
}
public E pollFirst() {
if (size == 0)
return null;
return removeFirst();
}
public E pollLast() {
if (size == 0)
return null;
return removeLast();
}
/**
* stack LIFO操作实现
*/
public void push(E e) {
addFirst(e);
}
/**
* stack操作实现
*/
public E pop() {
return removeFirst();
} 
http://docs.oracle.com/javase/6/docs/api/java/util/Deque.html
ArrayList\LinkedList对比:
大量操作下,
arrayList的remove();add();比较慢,是因为每次remove或者add一个操作都会导致数组重新初始化,并且调用System.copy浅克隆。get(int i)操作较快,因为是数组定位的,当然很快。