DCGAN深度卷积生成对抗网络&python自动绘图
GAN
生成对抗网络
是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。
举例说明
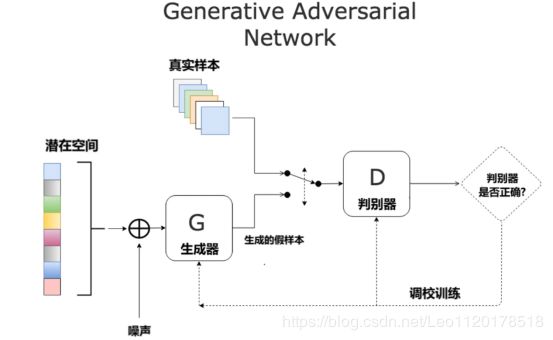
我们可以通过一个简单的例子来解释GAN的基本原理。我们使用情侣间的拍照片来解释GAN的原理,男生给女友拍照,男生的拍照技术通常很烂(。。。),我们把生成网络比作是男友,那么判别网络就是女友,男生拍完一张照片后给女友看,生成网络负责从随机生成数据,在这里比作是照片。拍完一张给女友看,那么女友就可以看做是判别网络,负责找出男生给出的数据与真实值之间的差别,不断的拍照不断的判别,直到找到判别网络无法判断是生成的还是真实数据为止。
GAN生成对抗网络
就是由两个神经网络组成,一个生成网络,与一个判别网络,让两个神经网络以相互博弈的方式进行学习。
什么是DCGAN
DCGAN是GAN的一个变体。
Deep Convolutional GAN 深度卷积生成对抗网络。
里面有生成器和判别器两个模型
生成模型和判别模型都运用了深度卷积 神经网络的生成对抗网络
Gan里面生成模型和判别模型也是用到了神经网络。
在DCGAN中生成器用到了反卷积神经网络,判别器用到了卷积神经网络。
卷积神经网络基本原理
经过卷积层提取它的一些特征信息。池化层进行亚采样,再经过卷积层池化层。将信息逐层深入的去解析。例如给出一张带有各种形状的图片,最后经过处理提取出一些简单的特征代表该图像
反 卷积神经网络的基本原理
由简单到复杂地反向生成。例如,简单的给出一些图像的特征,最后经过一层一层的处理,最后生成图像。
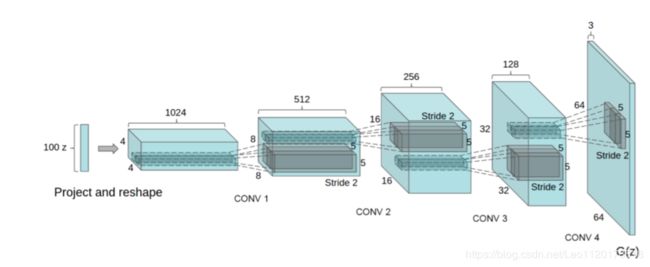
判别器模型
自动生成图片
本篇论文中的程序主要是引用论文UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS中提出的DCGAN模型,进行自动绘图的代码实现。首先是对判别器生成器模型的定义,然后进行数据集的训练,本文用到的数据集有几万张,由于图像像素小,所以用CPU训练是完全可以跑起来的。
核心算法主要用到了一类称为深度卷生成对抗网络(DCGAN)的CNN,DCGAN的全称是Deep Convolutional Generative Adversarial Networks,意即深度卷积对抗生成网络,它是由Alec Radford在论文Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks中提出的。它是在GAN的基础上增加深度卷积网络结构,用于专门生成图像样本,它的一些架构特征表明这种算法非常适合无监督学习。
通过使用DCGAN对各种图像数据集进行训练,DCGAN中的生成器G和判别器D的含义以及损失都和原始GAN中完全一致,于判别器D,判别器D的结构是一个卷积神经网络,它的输入是一张图像,输入的图像经过若干层卷积后得到一个卷积特征,输出是这张图像为真实图像的概率。对于生成器G,它的输入为随机噪声输入。通过搭建模型深度卷积生成对抗网络,可以学习从生成器和鉴别器中的对象部分到场景的表示之间的层次结构,并能顺利的完成图形生成任务。
编程环境
OS:Ubuntu 16.04
Python2.7
TensorFlow 1.4 CPU版本
Pilliow(Python的图像处理库)
numpy(数学函数库)
代码
判别器模型:
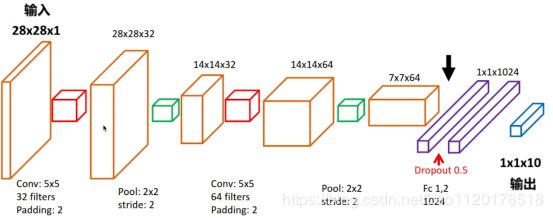
第一层:卷积层,输入图像大小为64643,卷积核大小55,输出的深度大小为64,padding=2,表示输出的大小不变,因此需要在外围补零2圈。添加 Tanh 激活层。
第二层:池化层,使用的是MaxPool2D,pool_size=(2, 2)
第三层:第二层卷积层Conv2D,卷积核大小55,128个过滤器,并且使用tanh激活函数。
第四层:池化层MaxPool2D,池化层的过滤器大小pool_size=(2, 2))。
第五层:第三层卷积层Conv2D,激活函数继续使用tanh。
第六层:MaxPool2D池化层,pool_size=(2, 2)。然后是将六底层的输出进行扁平化的操作Flatten,进行reshape
第七层:全连接层,输出神经元的个数为1024个
第八层:全连接层,输出神经元的个数为1个。最后添加Sigmoid 激活层。
生成器模型:
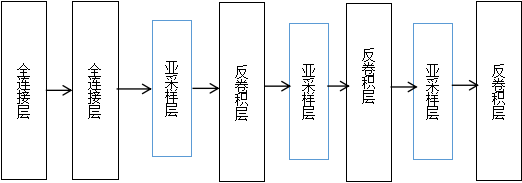
第一层:全连接层Dense,这个地方的长和宽是要原始图片反推过来的,然后reshape成图像长度。输入的维度是 100,采用正态分布的随机数,输出维度(也就是说神经元个数)是1024 的全连接层
第二层:全连接层Dense,输出是8192 个神经元的全连接层。然后进行批标准化,对数据进行标准化的操作,把激活函数tanh转换一下。然后再进行reshape操作,转换一下形状,把高和宽转换为88的一个形状Reshape重新改变形状。
第三层:亚采样层,池化的反操作,向上层采样。
第四层:反卷积层Conv2D,参数和上面的一样。输出通道是1616的图像
第五层:亚采样层UpSampling2D,池化的反操作,向上层采样。高和宽变成32*32
第六层:反卷积层Conv2D,添加激活函数tanh
第七层:亚采样层UpSampling2D,池化的反操作,向上层采样,图像的高和宽变成64 x 64像素。
第八层:反卷积层Conv2D,然后添加激活函数tanh。
def discriminator_model():
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(
64, # 64 个过滤器,输出的深度(depth)是 64
(5, 5), # 过滤器在二维的大小是(5 * 5)
padding='same', # same 表示输出的大小不变,因此需要在外围补零2圈
input_shape=(64, 64, 3) # 输入形状 [64, 64, 3]。3 表示 RGB 三原色
))
model.add(tf.keras.layers.Activation("tanh")) # 添加 Tanh 激活层
model.add(tf.keras.layers.MaxPool2D(pool_size=(2, 2))) # 池化层
model.add(tf.keras.layers.Conv2D(128, (5, 5)))
model.add(tf.keras.layers.Activation("tanh"))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Conv2D(128, (5, 5)))
model.add(tf.keras.layers.Activation("tanh"))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Flatten()) # 扁平化
model.add(tf.keras.layers.Dense(1024)) # 1024 个神经元的全连接层
model.add(tf.keras.layers.Activation("tanh"))
model.add(tf.keras.layers.Dense(1)) # 1 个神经元的全连接层
model.add(tf.keras.layers.Activation("sigmoid")) # 添加 Sigmoid 激活层
return model
# 定义生成器模型
# 从随机数来生成图片
def generator_model():
model = tf.keras.models.Sequential()
# 输入的维度是 100, 输出维度(神经元个数)是1024 的全连接层
model.add(tf.keras.layers.Dense(input_dim=100, units=1024))
model.add(tf.keras.layers.Activation("tanh"))
model.add(tf.keras.layers.Dense(128 * 8 * 8)) # 8192 个神经元的全连接层
model.add(tf.keras.layers.BatchNormalization()) # 批标准化
model.add(tf.keras.layers.Activation("tanh"))
model.add(tf.keras.layers.Reshape((8, 8, 128), input_shape=(128 * 8 * 8, ))) # 8 x 8 像素
model.add(tf.keras.layers.UpSampling2D(size=(2, 2))) # 16 x 16像素
model.add(tf.keras.layers.Conv2D(128, (5, 5), padding="same"))
model.add(tf.keras.layers.Activation("tanh"))
model.add(tf.keras.layers.UpSampling2D(size=(2, 2))) # 32 x 32像素
model.add(tf.keras.layers.Conv2D(128, (5, 5), padding="same"))
model.add(tf.keras.layers.Activation("tanh"))
model.add(tf.keras.layers.UpSampling2D(size=(2, 2))) # 64 x 64像素
model.add(tf.keras.layers.Conv2D(3, (5, 5), padding="same"))
model.add(tf.keras.layers.Activation("tanh"))
return model
# 构造一个 Sequential 对象,包含一个 生成器 和一个 判别器
# 输入 -> 生成器 -> 判别器 -> 输出
def generator_containing_discriminator(generator, discriminator):
model = tf.keras.models.Sequential()
model.add(generator)
discriminator.trainable = False # 初始时 判别器 不可被训练
model.add(discriminator)
return model
训练数据集代码
import os
import glob
import numpy as np
from scipy import misc
import tensorflow as tf
from network import *
def train():
# 确保包含所有图片的 images 文件夹在所有 Python 文件的同级目录下
if not os.path.exists("images"):
raise Exception("包含所有图片的 images文件夹不在此目录下,请添加")
# 获取训练数据
data = []
for image in glob.glob("images/*"):
image_data = misc.imread(image) # imread 利用 PIL 来读取图片数据
data.append(image_data)
input_data = np.array(data)
# 将数据标准化成 [-1, 1] 的取值, 这也是 Tanh 激活函数的输出范围
input_data = (input_data.astype(np.float32) - 127.5) / 127.5
# 构造 生成器 和 判别器
g = generator_model()
d = discriminator_model()
# 构建 生成器 和 判别器 组成的网络模型
d_on_g = generator_containing_discriminator(g, d)
# 优化器用 Adam Optimizer
g_optimizer=tf.keras.optimizers.Adam(lr=LEARNING_RATE,beta_1=BETA_1)
d_optimizer=tf.keras.optimizers.Adam(lr=LEARNING_RATE,beta_1=BETA_1)
# 配置 生成器 和 判别器
g.compile(loss="binary_crossentropy", optimizer=g_optimizer)
d_on_g.compile(loss="binary_crossentropy", optimizer=g_optimizer)
d.trainable = True
d.compile(loss="binary_crossentropy", optimizer=d_optimizer)
# 开始训练
for epoch in range(EPOCHS):
for index in range(int(input_data.shape[0] / BATCH_SIZE)):
input_batch = input_data[index * BATCH_SIZE : (index + 1) * BATCH_SIZE]
# 连续型均匀分布的随机数据(噪声)
random_data = np.random.uniform(-1, 1, size=(BATCH_SIZE, 100))
# 生成器 生成的图片数据
generated_images = g.predict(random_data, verbose=0)
input_batch = np.concatenate((input_batch, generated_images))
output_batch = [1] * BATCH_SIZE + [0] * BATCH_SIZE
# 训练 判别器,让它具备识别不合格生成图片的能力
d_loss = d.train_on_batch(input_batch, output_batch)
# 当训练 生成器 时,让 判别器 不可被训练
d.trainable = False
# 重新生成随机数据。很关键
random_data = np.random.uniform(-1, 1, size=(BATCH_SIZE, 100))
# 训练 生成器,并通过不可被训练的 判别器 去判别
g_loss = d_on_g.train_on_batch(random_data, [1] * BATCH_SIZE)
# 恢复 判别器 可被训练
d.trainable = True
# 打印损失
print("Epoch {}, 第 {} 步, 生成器的损失: {:.3f}, 判别器的损失: {:.3f}".format(epoch, index, g_loss, d_loss))
# 保存 生成器 和 判别器 的参数
# 大家也可以设置保存时名称不同(比如后接 epoch 的数字),参数文件就不会被覆盖了
if epoch % 10 == 9:
g.save_weights("generator_weight", True)
d.save_weights("discriminator_weight", True)
if __name__ == "__main__":
train()
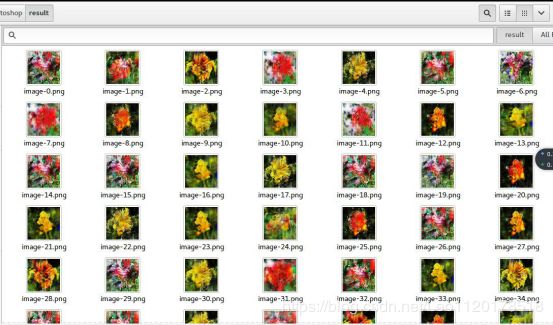
生成图片
# 加载训练好的 生成器 参数
g.load_weights("generator_weight")
# 连续型均匀分布的随机数据(噪声)
random_data = np.random.uniform(-1, 1, size=(BATCH_SIZE, 100))
# 用随机数据作为输入,生成器 生成图片数据
images = g.predict(random_data, verbose=1)
# 用生成的图片数据生成 PNG 图片
for i in range(BATCH_SIZE):
image = images[i] * 127.5 + 127.5
Image.fromarray(image.astype(np.uint8)).save("image-%s.png" % i)
生成结果
需要完整代码,可以评论或者邮箱O(∩_∩)O
+++++++仅供大家学习交流+++++