Python scikit-learn 学习笔记—手写数字识别
这是一个手写数字的识别实验,是一个sklearn在现实中使用的案例。原例网址里有相应的说明和代码。
首先实验的数据量为1797,保存在sklearn的dataset里。我们可以直接从中获取。每一个数据是有image,target两部分组成。Image是一个尺寸为8*8图像,target是图像的类别,在我们看来类别就是手写的数字0-9.
代码一开始,将数据载入。
# Standard scientific Python imports
import matplotlib.pyplot as plt
# Import datasets, classifiers and performance metrics
from sklearn import datasets, svm, metrics
# The digits dataset
digits = datasets.load_digits()之后,抽取了前四个训练数据将他们画了出来。里面enumerate函数用法参见如下网址:
http://blog.csdn.net/suofiya2008/article/details/5603861
images_and_labels = list(zip(digits.images, digits.target))
for index, (image, label) in enumerate(images_and_labels[:4]):
plt.subplot(2, 4, index + 1)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Training: %i' % label)然后训练器为向量机分类器SVC。
向量机的原理可以看一下这一篇博客:
http://www.cnblogs.com/v-July-v/archive/2012/06/01/2539022.html
这里它只规定了参数gamma
更多的可选参数在如下网址中:
http://scikit-learn.org/0.13/modules/generated/sklearn.svm.SVC.html#sklearn.svm.SVC
在SVM中,我尝试变换了一下内核函数,除了kernel=’sigmoid‘效果比较差,其他的效果差别不大。
# To apply a classifier on this data, we need to flatten the image, to
# turn the data in a (samples, feature) matrix:
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
# Create a classifier: a support vector classifier
classifier = svm.SVC(gamma=0.001,kernel='poly')
# We learn the digits on the first half of the digits
classifier.fit(data[:n_samples / 2], digits.target[:n_samples / 2])之后是训练和测试环节,在这里它将所有的数据分成了两部分。一半去做训练集,一半去做测试集。
# Now predict the value of the digit on the second half:
expected = digits.target[n_samples / 2:]
predicted = classifier.predict(data[n_samples / 2:])
print("Classification report for classifier %s:\n%s\n"
% (classifier, metrics.classification_report(expected, predicted)))
print("Confusion matrix:\n%s" % metrics.confusion_matrix(expected, predicted))
这里说一下测试的参数。首先是precision,recall,f1-score,support这四个参数。

f1-score是通过precision,recall两者算出来的。计算公式如下图:
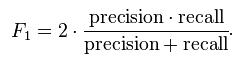
support为支持度,表示识别出来的数据个数。
其次是混淆矩阵:在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。混淆矩阵是通过将每个实测像元的位置和分类与分类图像中的相应位置和分类像比较计算的。混淆矩阵的每一列代表了实际测得信息,每一列中的数值等于实际测得像元在分类图象中对应于相应类别的数量;混淆矩阵的每一行代表了数据的分类信息,每一行中的数值等于分类像元在实测像元相应类别中的数量。
之后将几个测试集中的数据画下来就好啦~
images_and_predictions = list(zip(digits.images[n_samples / 2:], predicted))
for index, (image, prediction) in enumerate(images_and_predictions[:4]):
plt.subplot(2, 4, index + 5)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Prediction: %i' % prediction)
原例网址
http://scikit-learn.org/stable/auto_examples/classification/plot_digits_classification.html#example-classification-plot-digits-classification-py