MySQL排序规则
1、MySQL的排序规则是干什么的?
我们在使用 Navicat for MySQL 或 MySQL Workbench 创建数据库的时候,除了数据库名称和字符集外,我们还可以设置 Collation【排序规则】 (当然我们也可以使用默认的排序规则),那么这里的排序规则到底是干什么的?

排序规则概念:是指对指定字符集下不同字符的比较规则。排序规则有以下特征:
- 它和字符集(
CHARSET)相关 - 每种字符集都有多种它支持的排序规则
- 每种字符集都会默认指定一种排序规则为默认值。
排序规则作用:排序规则指定后,它会影响我们使用 ORDER BY语句查询的结果顺序,会影响到 WHERE条件中大于小于号的筛选结果,会影响 DISTINCT、GROUP BY、HAVING 语句的查询结果。另外,mysql 建索引的时候,如果索引列是字符类型,也会影响索引创建,只不过这种影响我们感知不到。总之,凡是涉及到字符类型比较或排序的地方,都和排序规则有关。
2、排序规则设置及优先级
2.1 排序规则设置
排序规则设置可以分为:MySQL实例级别、库级别、表级别、列级别以及SQL指定。
2.1.1 MySQL实例级别设置
实例级别的排序规则设置就是 MySQL 配置文件或启动指令中的 collation_connection 系统变量。
实例级别设置排序规则
可以通过修改mysql的配置文件 my.ini来修改相应的排序规则,修改好后,重启mysql服务。
查看MySQL实例级别的字符集和排序规则
show variables like '%character%';
show variables like '%collation%';

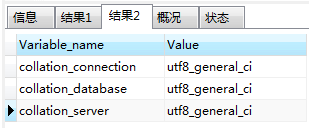
从上图可以看到,当前实例级别的字符集是 utf8,排序规则是 utf8-general_ci。
2.1.2 库级别设置
库级别设置排序规则
在创建数据库的时候指定数据集和排序规则
CREATE DATABASE TESTDB
DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
查看库级别排序规则
show create database testdb;

2.1.3 表级别设置
表级别设置排序规则
在创建表的时候指定表的数据集和排序规则
use testdb;
CREATE TABLE user(
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
查看表级别排序规则
show table status from testdb like 'user';
-- testdb 为数据库名, user 为要查看的表名

2.1.4 列级别设置
列级别设置排序规则
在创建表的时候指定列的数据集和排序规则
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
查看列级别排序规则
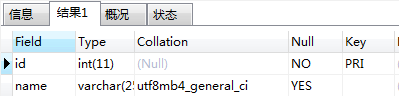
show full columns from user;
2.1.5 SQL指定设置
SQL语句中指定排序规则
SELECT id, name FROM `user`
ORDER BY name COLLATE utf8mb4_unicode_ci;
2.2 排序规则优先级
优先级顺序是 SQL语句 > 列级别设置 > 表级别设置 > 库级别设置 > 实例级别设置
也就是说,如果SQL语句中指定了排序规则,则以其指定为准,否则以下一级为准(也就是列级别),如果列级别没有指定,默认是继承表级别的设置,以此类推。
3、几种常用排序规则介绍
我们以字符集utf8mb4为例,常用的排序规则有:utf8mb4_general_ci、utf8mb4_bin、utf8mb4_unicode_ci。
3.1 utf8mb4_general_ci
ci即case insensitive,不区分大小写。没有实现Unicode排序规则,在遇到某些特殊语言或者字符集,排序结果可能不一致,但是,在绝大多数情况下,这些特殊字符的顺序并不需要那么精确。另外,在比较和排序的时候速度更快。
3.2 utf8mb4_bin
将字符串每个字符用二进制数据编译存储,区分大小写,而且可以存二进制的内容。
3.3 utf8mb4_unicode_ci
不区分大小写,基于标准的Unicode来排序和比较,能够在各种语言之间精确排序,在特殊情况下,Unicode排序规则为了能够处理特殊字符的情况,实现了略微复杂的排序算法,所以兼容度比较高,但是性能不高。