超实时性单目标跟踪网络——Siamese RPN(CVPR2018 spotlight论文)
今年sensetime在CVPR上的表现力压国内其他科研机构,直逼谷歌。以44篇论文(3oral,11spotlight,28poster)在国内一骑绝尘。其中有一篇北航大四学生李博为一作的论文SiamRPN在单目标tracking领域很有参考性。
Siamese RPN
论文地址: 戳链接
论文标题:
| High Performance Visual Tracking with Siamese Region Proposal Network |
|---|
发表会议: CVPR2018
论文领域: 单目标追踪
论文代码: 暂无
论文目的
对输入视频进行单目标追踪,对于很多初级CVer会直接认为目标追踪就是对每一帧的detection。其实这是不准确的,这样做一来运算速度慢(实时性不好),二来performance也难以理想,三来只能针对你能识别的目标进行tracking。
VOT单目标追踪是有规则的:给你一段视频,然后在视频的第一帧给一个bbox(框住你要tracking的对象),然后要在视频播放的过程中一直tracking这个对象。整个tracking过程是一个offline(线下)的,也就是local one-shot detection task。
首先你得明白,框住的这个对象你的分类模型未必认识,比如一个异型物体——你根本找不到跟这个物体有关的训练集。所以,通常地对每一帧detection来进行tracking的,在这里就失效了。
用深度学习来解决上述单目标问题,就是siamese系列论文之目的所在。(源起于Oxford的论文Siamese FC)
先看看另一篇文章Siamese FC的网络结构
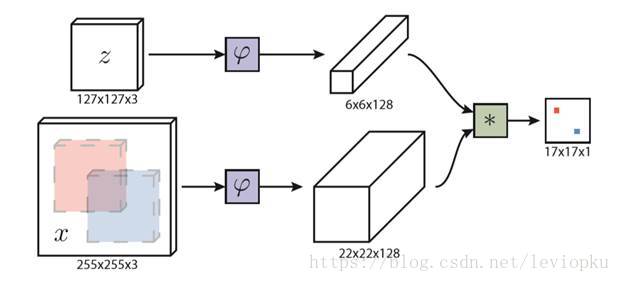
网络结构非常简单,巧妙地利用了一个叫做相关滤波的操作。怎么理解呢?就是把首帧中的目标的提取物当作检测帧的卷积核,这样一来,卷积操作就在检测帧中找到与首帧目标相似的目标,通过输出的FeatureMap的score来体现。可以看到最后的输出是一张17x17的score map。
说明:bbox = bounding box FRcnn = faster rcnn
- 一般在视频的首帧会给你一个bbox(含四个参数x, y, w, h),这个bbox框出的范围就是你要tracking的,预处理之后就变成上图中的 z z 。
- φ就是提取函数(这里用到一个全卷积网络),把φ训练出来就是整个 siamese s i a m e s e FC F C 的训练目标。
- 上图的 ∗ ∗ 表示的就是相关滤波,就是用一个FeatureMap卷积另一个Feature
Map的操作。最后生成一张17x17的概率(score)分布表,概率最大的那个就是目标位置,映射会原图像就可以得到输出bbox。
显然,Siamese FC有一些问题:
1. bbox的大小一直不会变,视频中的目标由远及近等情况的时候,会在图像中变大,但bbox框并不会变大。
2. 容易检测错误对象,比如跟踪人的时候,有另一个人走过来,bbox可能立马框到别人。这是因为供于提取特征的数据过于单一(首帧)。
Siamese RPN做了些什么呢
看名字也看得出来,把FC改成了RPN,RPN来自FasterR-CNN,而Siamese(孪生)来自Siamese FC。所以这篇文章就是把两种方法一凑,这么想来,发顶会论文也没那么难哈哈哈。(
注:这篇文章的实验结果在VOT2017实时准确率这项benchmark中傲视群雄,却只在CVPR上中一个spotlight,没达到oral级别,很重要的原因是因为此文没有网络结构和数学理论的较大创新。)
先看看SiamRPN的网络结构,可以跟SiamFC对比着看:

模板帧用的是视频的首帧,检测帧就是视频流中的一帧。SiamRPN的前一部分和SiamFC一样:都是先通过一个 全卷积网络提取高层特征(图1中的φ和图2中的CNN)。不同的是SiamFC把输出直接用来进行 相关滤波(图1中的 ∗ ∗ ),而SiamRPN接入的是一个RPN(有2个分支:分类、回归)。
想细究RPN可以参读我的另一篇博文《 分析RPN》
也用不着被链接带跑,仅看这篇博文足够看懂。
分类,就是做一个二分类,是“目标”和“不是目标”
回归,是bounding box回归,给出的是偏移量(dx, dy, dw, dh)
如果你没有FasterRcnn的基础,估计有点难理解的是BoundingBox回归,不急,待我细细道来。
首先明白一个叫anchor的东西
计算机不知道目标可能出现在哪里,为了不漏掉任何一个细节,只能傻fufu全局找,以每一个pixel为中心生成 k k 个大小预设定框(这些框就是anchors),看目标在不在这些框里(RPN中的分类网络干这事儿)。如果到这儿就结束了,那SiamRPN就跟SiamFC一个德行了,因为框是预设定大小的,不会随物体的变大变小而变动。而回归网络干的就是这个事儿!!
把anchor框的位置(x, y)和大小(w, h)进行调整,所以只需要得到偏移量
(dx, dy, dw, dh),原参数加上偏移量就可以得到最后的bbox了。偏移公式如下:
y y j j pro p r o = = y y j j an a n + + dy d y l l reg r e g ∗ ∗ h h l l an a n
w w l l pro p r o = = w w l l an a n ∗ ∗ e e dwl d w l
h h l l pro p r o = = h h l l an a n ∗ ∗ e e dhl d h l
这里歪一下楼:为什么不直接把x,y,w,h输出出来,这不更省事儿吗?
我刚接触rcnn的时候也在想,为什么不能通过一个神经网络解决这四个参数,非得通过RPN这种复杂考虑。这是有原因的,直接输出x,y,w,h也行,就是效果很差。用回归实现偏移的前提就是 原本anchor的四个参数和groundtruth相差不大,这样就可以把调节过程当作一个线性过程,如此一来才能通过回归算法建模。

图3具体的操作流程,就是比图2 稍微详细点。不过也可以看出这个网络是双支(孪生)全并行结构,从siamese network(前部分)是2并行,到后面的RPN到4并行最后又到2并行。相比FasterRcnn并行度做得更高,因为FRcnn的RPN到ROI的过程中没有做到并行。这跟网络目的有关,FRcnn不仅需要定位还需要对目标进行分类,只能先定位再识别。这也是Siamese RPN能做到超实时的原因之一(帧率达到160+ fps)。其实达到这么高的帧率还依赖近年来的GPU的提升,比如单看网络结构的话,SiamRPN不应该比SiamFC更快。
VOT chanllenge有一个benchmark叫做 EFO。
因为性能的比较常常因为计算机性能不同而不够直观,EFO评价标准考虑到了这一点,使用600×600的图像,做30*30窗口的滤波,来得到机器的性能。然后使用跟踪算法处理每帧图像的评价时间除以以上滤波操作的时间,得到了一个归一化的性能参数,就是EFO
而SiamRPN的EFO也比SiamFC高很多(前者23,后者8),我个人猜测,可能是计算资源部署方案比较优胜吧。有其他高见可以在评论里留言。
实验结果
作者先拿SiamRPN虐了一下VOT2015的各大算法,在四个benchmark中都达到了最佳:

在各种挑战赛中,经常有鱼和熊掌不可兼得的时候,考虑到实时性,准确率又达不到很好等等。能做到各种benchmark都很厉害的算法,就是很666的算法。
和VOT2016的各大算法比较:

除错误率之外,其他三项benchmark也全碾压。
继续看VOT2017比赛:

这次没有比四项 benchmark b e n c h m a r k (因为并没有碾压到别人),这次比实时准确率。
帧率达到25fps的算法才有资格称为“实时”,在所有实时算法里只有SiamRPN的准确率最高,完全达到了实时tracking的state-of-the-art。本着很多场景下实时才能用的原则来看,SiamRPN称得上应用性很强的算法了。