python爬虫基础知识的总结
什么是爬虫?
一、爬虫概述
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序。
1.获取页面(如urllib、requests等)
2.提取信息(Beautiful Soup、pyquery、lxml等)
3.保存数据(MySQL、MongoDB等)
4.自动化程序
二、关于JS渲染的页面?
1.使用urllib、requests 等库请求当前页面时,只是得到html代码,它不会帮助我们去继续加载这个JS文件。
2.使用基本HTTP请求库得到的源代码可能和浏览器的页面源代码不太一样,对于这种情况,我们可以分析其后台Ajax接口,也可以使用Selenium、
Splash 这样的库来实现模拟JS渲染。
三、会话和Cookies
...
四、代理的基本原理
1.代理实际上指的就是代理服务器,代理网络用户去取得网络信息。形象的说,网络信息中转站。
本机 -----------> 代理服务器 --------------> Web服务器
请求 请求
本机 <----------- 代理服务器 <-------------- Web服务器
响应 响应
这样我们同样可以正常访问网页,这过程中Web服务器识别出真是IP 就不再是我们本机IP了,就可以成功IP伪装,这就是
代理的基本原理
2.代理的作用
1)突破自身IP访问限制,访问一些平时不能访问的站点
2)访问一些单位或团体内部资源
3)提高访问速度
4)隐藏真是IP,防止自身IP被封锁
3.爬虫代理
对于爬虫来说,爬虫爬虫速度过快,爬虫可能遇到同一个IP访问过去频繁的问题,此时网站就会让我们输入验证码或者直接封锁
IP,这样带给爬虫极大不便。
使用代理隐藏真是IP,让服务器误以为是代理服务器在请求自己。这样在爬取过程中通过不断的更换代理,就不会被封锁,可以
达到很好的效果
4.代理分类
1)FTP 代理服务器:访问 FTP 服务器,上传。下载以及缓存功能,端口 21、2121 等
2)HTTP 代理服务器:访问网页,内容过滤和缓存功能,端口 80、8080、3128等
3)SSL/TLS 代理:访问加密网站,一般有SSL 或TLS加密功能(最高支持128位加密功能),端口 443
4)RTSP 代理:Real 流媒体服务器,一般有缓存功能,端口:554
5)Telnet 代理:主要用于telnet远程控制(黑客入侵计算机时常用于隐藏身份),端口为23
6)POP3/SMTP 代理:POP3/SMTP 方式收发邮件,一般有缓存功能,端口:110/25
基本库的使用
一、urllib
在Python3中,urllib已经不存在urllib2,统一为urllib,官方文档链接:https://docs.python.org/3/library/urllib.html
urllib库,是Python 内置的HTTP请求库
它包含如下四个模块:
request:基本的HTTP请求模块
error:异常处理模块
parse:工具模块
robotparser(用的比较少):识别网站的robots.txt文件
1.urlopen()
urllib.request模块提供最基本的HTTP请求方法,同时它还带有处理授权验证码、重定向、浏览器Cookies以及其他内容。
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(type(response))
output:
进行分析,HTTPResponse类型对象,包含read(),readinfo(),getheader(name),getheaders(),fileno()等方法,以及msg、version
、status、reason、debuglevel、closed等属性。
urllib.request.urlopen(url, data=None, [timeout,]*, cafile=None, capath=None, cadefault=False, context=None)
data (附加数据)、timeout(超时时间)等
# timeout 参数
import socket
import urllib.error
import urllib.request
try:
response = urllib.request.urlopen("http://httpbin.org/get", timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('TIME OUT')
#其他参数
除了data参数和timeout参数外, 还有 context 参数,它必须是ssl.SSLContext 类型,用来指定SSL 设置。
此外, cafile 和 capath 这两个参数分别指定 CA证书和它的路径,这个在请求 HTTPS链接时会有用。
前面讲解了 urlopen() 方法的用法, 通过这个最基本的方法, 我们可以完成简单的请求和网页抓取。 若需要更加详细的信息,可以参考
官方文档: https://docs.python.org/3/library/urllib.request.html2.Request()class urllib.request.Request(url, data=None, headers={}, orgin_req_host=None, unverifiable=False, method=None)示例:
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'USER-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2132.2 Safari/537.36',
'Host':'httpbin.org'
}
dict = {
'name':'Germey'
}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url = url, headers=headers, data = data, method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))3、高级用法
1)文件上传
# requests 可以模拟提交一些数据
# import requests
# files = {'file': open('favicon.ico', 'rb')}
# r = requests.post("http://www.baidu.com", files = files)
# print(r.text)
2)Cookies
使用requests, 获取和设置Cookies 只需一步即可完成
示例1:
import requests
r = requests.get("https://www.baidu.com")
print(r.cookies)
for key,value in r.cookies.items():
print(key + '=' + value)
运行出结果,发现是RequestCookieJar类型,然后用items() 方法将其转化为元组组成在列表,遍历出
Cookie 的名称和值
示例2:
import requests
cookies = 'tgw_l7_route=9553ebf607071b8b9dd310a140c349c5; ' \
'_zap=74b7fdae-0800-4485-85b3-aa07447a91cf;' \
' _xsrf=vyBIBWAXr6lQuxsCNIzKwJSb4zjqxRaS;' \
' d_c0="APAh_lT6mA6PTlfodNHDUqm1slkUFNb60xo=|1543564338";' \
' capsion_ticket="2|1:0|10:1543564343|14:capsion_ticket|44:YzRlNGViM2IxNjY5NDVkNDhlOGM1OTM4ZmFjODVjMDQ=|fcd395175baab35d7a674f5b7639097551230b1a0c5be9d34bc5ebe4b1f3f0f0"; ' \
'z_c0="2|1:0|10:1543564360|4:z_c0|92:Mi4xcUthWUF3QUFBQUFBOENILVZQcVlEaVlBQUFCZ0FsVk5TRHJ1WEFEdWdEQ29zYTJQUzVNMDNCejdGNldZUnNCdVBB|8a367dc007da80cb3a844af327cf67cfe9b248f95cf5e585c46be5d0b396caab"; ' \
'tst=r; ' \
'q_c1=ab8ffad7fa864108bda8ff3971b5054b|1543564362000|1543564362000'
jar = requests.cookies.RequestsCookieJar()
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2132.2 Safari/537.36',
'Host':'www.zhihu.com'
}
for cookie in cookies.split(';'):
key, value = cookie.split('=', 1)
jar.set(key, value)
r = requests.get('http://www.zhihu.com', cookies=jar, headers= headers)
print(r.text)
3、会话维持
1)Cookies 会话,请求这个网址时,可以设置一个Cookie,名称叫做number,内容
是123456789, 随后访问http://httpbin.org/cookies
import requests
requests.get("http://httpbin.org/cookies/set/number/123456789")
a = requests.get("http://httpbin.org/cookies")
print(a.text)
结果如下:
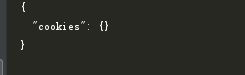
随后,使用session()
import requests
s = requests.Session()
s.get("http://httpbin.org/cookies/set/number/123456789")
b = s.get("http://httpbin.org/cookies")
print(b.text)
output: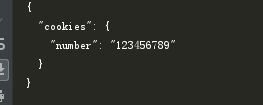
以上Cookie与Session可以对比出,利用Session,可以做到模拟同一个会话而不用担心Cookies的
问题。