Redis原理分析(一)
一、Redis字符串内部
Redis内部的字符串是以数组形式储存的。在C语言中,字符串的结尾是以NULL(0x\0)作为结束符号,但是在redis里面,如果像C语言一样的话,如果需要获取某字符串,需要进行数组的遍历扫描,这样的时间复杂度为O(n),这样Redis表示我受不起。
所以Redis自己定义了一种数据结构,叫做SDS(Simple Dynamic String),这种数据结构有一个很大的特点就是带字节数组的长度信息,这样有什么好处呢?
比如我现在要查找一个字符串“c”,如果按第一种形式的话要在数组[a,NULL,a,b,NULL,c,NULL]中需要遍历每一个数组元素,直到遍历7次到最后一个NULL才能找到字符串c
如果使用SDS结构的话将类似于[ { [a] , 1 } , { [a , b] , 2 } , { [c] , 1 } ]的数组结构(为了说明这里暂时假设SDS结构只有长度和数组内容两个字段,其他后续补充),这样的话遍历3次就行了。
例子可能不是特别恰当,但重点是说明在结构中加入长度所带来的好处。
下面看看完整的SDS结构
struct SDS {
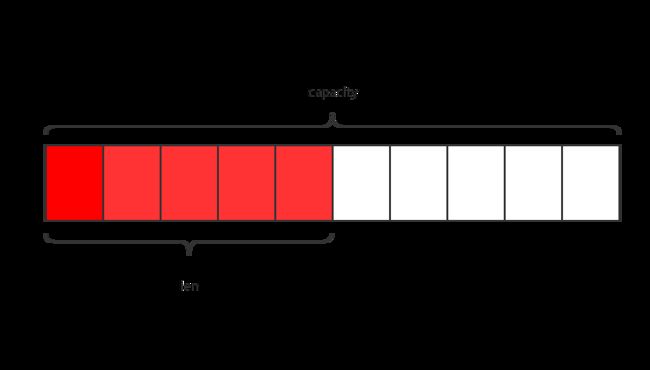
T capacity; //数组容量
T len; //数组长度
byte flags; //特殊标志符,不理会
byte[] content; //数组长度
} 如结构所示,真正存储数据内容是content,下面解释其他字段的含义
capacity:该字段表示所分配的数组长度,也即content的所分配的长度。
len:表示content的实际长度
加入我们对字符串进行修改的操作如果新增的字符串还在数组容量以内则继续在原数组中添加字符串,如果加入后数组没有了冗余的空间,那么则创建一个新的数组,再把旧的数组复制过来(在理解上可以联想到java中ArrayList操作)。总结来说,修改字符串就是对数组的复制和对内存的重新分配操作,因此如果字符串的长度非常大,那么内存的开销也会非常大。
/*追加 SDS 字符串 */
sds sdscatlen(sds s,const void *t,size_t len){
size_t curler = sdslen(s); //原来字符串
//按需调整空间,如果capacity不够容纳追加的长度,就会重新分配字节数组并且复制原字符串的内容追加到新数组中
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL; //内存不足
memcpy(s+curlen , t, len); //追加目标字符串到字节数组中
ssdsetlen(s,curlen+len); //设置追加后的长度值
s[curlen+len] = '\0'; //让字符串以\0结尾,便于调试打印
return s;
}我们可以注意到上面的结构中用到了范型T,为什么不用int(占四个字节)呢?因为如果在数组字符串很短的时候,可以用占用内存比较小的byte(占一个字节)或者short(占两个字节)。可以看出Redis对内存的优化做到了极致,不同的数组长度使用不同的结构体表示。
Redis规定了字符串数组最大不能够超过512MB,在创建字符串的时候len和capacity是一样长的,在大多数场景我们不会对redis字符串使用append操作。
二、Redis的存储方式
Redis根据数组长度的大小分为两种数组结构:embstr和raw。
当数组长度超过44字节的时候采用raw形式存储,小于或等于44采用embstr结构。
那么问题来了,为什么是44字节作为分界线呢,这要分别从这两种类型开始讲起。
首先看看Redis的对象头信息
struct RedisObject{
int4 type; //4bit
int4 encoding; //4bit
int24 lru; //24bit
int32 refcount; //32bit
void *ptr; //64bit
}robj;type:对象的类型
encoding:对象的存储形式(embstr或者raw)
lru:lru信息
refcount:对象的引用计数器,当引用计数器为0的时候则对象会被销毁,内存被回收
*ptr:指针指向对象内容的具体位置
可知,一个RedisObject一共需要占据(4+4+24+32+64)/ 8 = 16 个字节
再看看SDS结构题的大小
struct SDS{
int8 capacity; //1byte
int8 len; //1byte
int8 flags; //1byte
byte[] content; //内联数组,长度为capacity
}字段含义上面已经解释过了,这里主要看需要占据的内存空间为 (1+1+1)+capacity >=3 ,至少要占据3字节
下面再看看embstr和raw在内存中存储形式的区别:

如上图,embstr和raw形式的最大区别是对象头RedisObject和SDS在内存中是否是连续存在一起的。
再embstr中,RedisObject和SDS是连续存在一起的,再分配内存的时候只需要调用malloc方法分配一次即可;但是在raw中需要调用malloc分配两次内存,因为其两个对象头在内存地址上是不连续的。
而内存分配器jemallopc和tcmalloc中分配内存大小的单元都说2的整数次方字节,为了能够容纳embstr对象,至少需要分配大于其最小占用的空间(19字节),则需要分配32字节,如果再长一点就需要分配64字节,那再长呢?如果分配内存大于64字节,那么redis认为这是一个大字节的字符串,则不再使用embstr存储,改用raw。
当分配到了临界值64字节的时候,字符串的最大长度是44字节。计算如下:
RedisObject占用16字节
SDS中capacity,len,flag各占1个字节,加起来就是3个字节
所以字符串内容数组content最大占用64-3-16=45字节
但content又是以NULL结尾的,所以还需要减1个字节,所以是44字节。
三、扩容策略
在字符串长度小于1MB的时候,每次对字符串进行修改时,若修改后的数组长度超过数组长度,其扩容数组长度扩容为原来的两倍,也就是保留100%冗余空间。当字符串长度大于1MB的时候,为了避免加倍后冗余空间过大而导致内存的浪费,则每次扩容最多分配1MB大小的空间