Python如何编写爬虫程序,附高级爬虫实现思路
今天和大家一起用Python写一个入门爬虫,作为基础课程的最后一讲。也希望给那些学习Python很久却没有思路,不知道如何实现一个爬虫的同学带带节奏,本节课会通过最简单的方式,实现抓取远程网页,并且获取所有图片地址的程序。
如果一直看我文章的朋友可能会知道,我在第一讲中立下了一个新年flag。

但是要自己打脸了,由于公司技术升级,开发语言从php升级为java。所以接下来的一段时间内没有办法保证Python实战和高级的课程日更。公司定的目标是3个月实现一个不大不小的java项目,需要把之前的php代码用java重写,并考虑后期的微服务,大数据等问题,所以接下来我的学习精力会迁移到java上,并保证java课程日更。
学习路线初步定为:java基础,servlet,ssm框架使用,spring源码学习,以及日常踩的一些坑,目的是能快速达到项目开发要求。
当然Python的学习不会扔掉,更新频率改为每周更新一次高级或者实战课程,希望对大家有帮助,对自己有提高。
废话就说这么多,看一下Python如何实现爬虫程序?
学完此次课程,我能做什么?
学完此次课程,大家会对如何实现爬虫有自己的实现思路,针对不同的站,通过不同的方法完成资料的获取,重点是分析和思路。
学习此次课程,需要多久?
5-10分钟代码学习,思路理解因人而异。
课程内容
再重复一下,本节课的重点是思路,代码量很少,只是一个基本的流程。看一下如何实现:
第一步,找共同点。如果我们要获取某个网址下的所有图片,首先我们查看元素,分析图片的HTML代码。
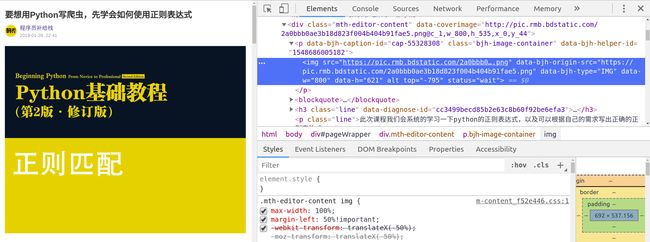
第二步,根据需求写正则表达式,上一节课已经讲了正则匹配,没看的同学可以关注我,看一下课程记录,下面我们看一下代码:
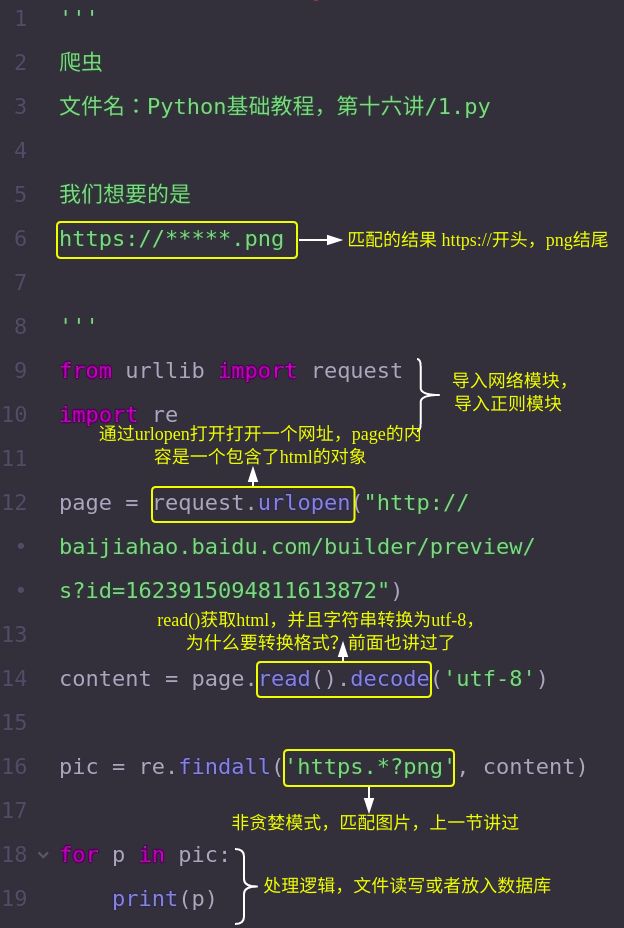
输出结果:
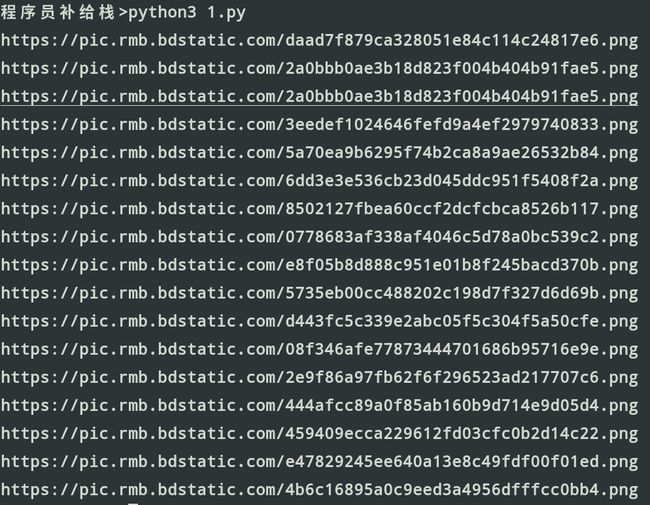
这就是我们想要的,全部的图片地址。
第三步,处理结果。
我们可以把结果存到文件或者数据库里,在其他场景使用。
分析一下:这个简易的爬虫是不是很简单?并没有我们想象中那么复杂,实际上有用的代码只有5-7行。其他再复杂的爬虫也是在这个基础上做的完善。首先我们分析了网页代码,知道了我们需要匹配的HTML代码为 https://到.png的内容。通过网络模块,获取网页内容,通过正则模块匹配出所有图片,最后循环处理,保存也好入库也好,总之拿到了所有图片路径怎么玩都可以。
爬虫进阶
如果互联网上所有的资源都这样就好了,下面介绍我的两个实战项目思路,这两种情况大家都会碰到:
需要登录怎么办?
对于需要先登录再抓取的网站,第一步先模拟登录,保存cookie。随后的所有请求带上cookie就可以登录状态访问了,如果不太明白的同学可以看一下cookie和session的区别和联系。
有图片验证码怎么办?
还有一种特别多的情况是,登陆时需要验证码怎么办?思路是先获取到登录页面的html。匹配出验证码的图片地址,通过程序识别或者打码平台来识别图片,然后带上验证码登录,保存cookie。由于图片验证码的网站非常容易被刷,所以现在的滑动二维码才会越来越多。
多线程
资源较少还好说,如果需要抓取的内容过多,简易大家学习一下多线程,了解了相关思路可以学习一下爬虫的相关框架。
我想要全站的资源,怎么办?
爬虫这个词非常形象,像一只虫子一样,爬来爬去,可以把某个网站看做是一张网,爬虫进入首页后,通过各级菜单(超链接)跳转至二级菜单,三级菜单等,依次找到最后一页的内容,通常一个网站的目录深度不会太多,基本都是3-5层,即首页-分类列表-详细信息。
小结
通过本次的课程,你能写一个自己的爬虫吗?如果有任何疑问欢迎评论或者私信,我会第一时间回复。
关注公众号,回复 Python基础 下载全部代码+PDF版电子书
