Word2Vec Sent2Vec
好好研究了下Word2Vec和Sent2Vec的代码,推导了下公式,花费了不少的时间,不过清晰了很多。
源代码参考:https://github.com/klb3713/sentence2vec
理论上是分两部分,首先是进行Word2Vec的,获得词向量,以及权重等。然后再进行Sent2Vec的处理,基于已有的Word Vector以及网络权重。
Word2Vec
- 预测目标
总体的目标是,词向量作为输入(CBOW是多个词的sum,sg是单个词输入),加上权重之后,得到预测的词向量。
首先,会建立haffman tree,每个词就用一组数字来表示[1,0,1,1]。上面的“预测的词向量”,就变成预测这组编码了。变成一个softmax。同时,越高频的词,编码越少,对应要处理的权重也越少,加快效率。
然后,假设最长一共有N位的编码,那么就是Softmax有N个输出。假设词向量维度为M,那么就有权重的空间就是M*N的矩阵,对应代码里的 l2a = model.syn1[word.point]。
- CBOW
CBOW就是,对于当前处理的word,获得它前后窗口范围内的所有词,将他们的词向量各维度求平均,作为输入(对应代码里的 l1)。
然后,计算输出 fa = 1. / (1. + exp(-dot(l1, l2a.T)))。以及梯度 ga = (1. - word.code - fa) * alpha。
由于我们需要学习W和词向量X,所以,两次计算。
学习W时,model.syn1[word.point] += outer(ga, l1)(就是说,syn1代表的就是W这一层)。
学习词向量时,neu1e += dot(ga, l2a);model.syn0[word2.index] += neu1e。(就是说,syn0代表的就是X这一层,也即我们的词向量)。
为什么是上面的这两个公式呢?就要自己推导了。可以参考 http://blog.sina.com.cn/s/blog_839cd44d0101flea.html 里的说明:
要明白这用的是交叉熵作为衡量 Loss=ylogp(x)+(1-y)*log(1-p(x))。y是实际的值(注意,作者是用了 1 - word.code 作为label,事实上也可以是word.code),p(x) 是输出(也就是上面的fa,将上面的式子代进来求导)。这个交叉熵,对syn1(就是W)和syn0(就是X,也即词向量)分别求导,就可以算出它们各自的梯度。也就得到上面的两个公式了。
- Skip Gram
与CBOW不同,l1层,也就是作为X的输入,是单个单词的词向量,而不是多个单词的avg结果。
引用一张经典的图来说明:
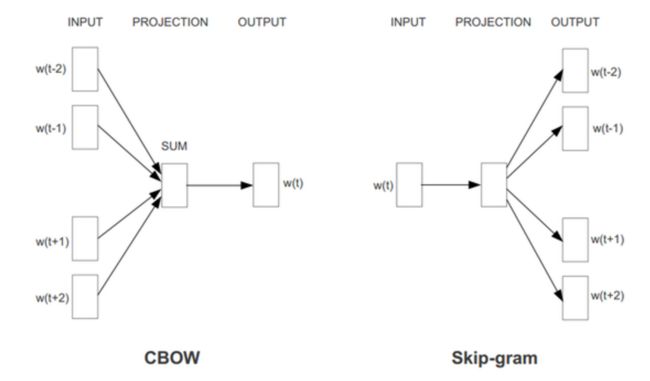
但是代码的实现,并不是以w(t) 为输入,而是反过来,分别以 w(t-2)、w(t-1)为输入,输出都是w(t)。
不管是哪种,SG都是两重循环了,比CBOW的要多一层。所以,效率上会慢点。
对了,不管CBOW还是SG,上下文窗口,都是随机出来的,已制定的MAX_WINDOW_SIZE为上限。
- hierarchical
其实就是上面预测目标说的事情,转成一个haffman tree,预测它的code。可以给每个tree node标上一个编号(word.point,1,2,3…),这样,就可以获得本次需要处理的W了(l2a = model.syn1[word.point])。
- negative
上面学的,其实都是正样本。所以,也要学下负样本,也即随机选择一个词作为输出。
首先,选择负样本,就是类似轮盘赌的形式。代码里有个小小的trick,http://blog.csdn.net/itplus/article/details/37998797 (这个blog推荐之,讲得很细)有讲,其实,越高频的词越有机会被抽到。
其次,这里的y,就不是code了,而是直接是 0 了。
labels = zeros(model.negative + 1)
labels[0] = 1 # 因为第一个是当前待处理的word,当然是1
gb = (labels - fb) * alpha
这里一样,要更新负样本的权重W(即syn1neg),以及neu1e。
Sent2Vec
建立在Word2Vec已经建立好的基础上(事实上,也可以建个模型,由词向量生成Sent2Vec,然后再由Sent2Vec和窗口内的Word2Vec来预测下一个词的Word2Vec,用BP来反向传播就行)。
论文《Distributed Representations of Sentences and Documents》,说起来简单,CBOW如下:

SG如下:
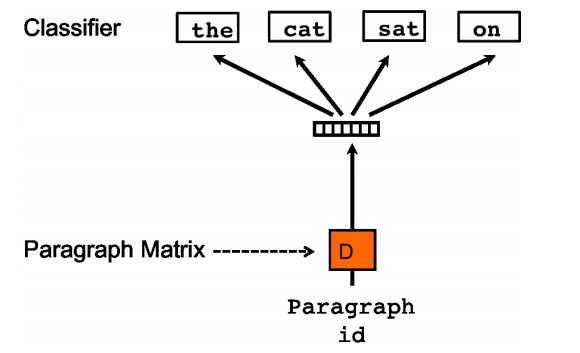
和Word2Vec的超级无敌像…
代码实现上,首先,sents[sent_no] 句向量是随机的。
然后,CBOW模型中,除了将窗口内的词向量求平均外,还加上句向量 l1 += sents[sent_no] 。然后,一样地以词向量作为输出,这时候,就不需要更新W(即syn1)了,所以,只需求一次梯度,更新 neu1e += dot(ga, l2a);self.sents[sent_no] += neu1e。
SG模型中,也是类似的。l1 = self.sents[sent_no]。预测的是窗口的多个单词。l2a = deepcopy(model.syn1[word2.point]) 。
通过多轮迭代,来获得sent vector。
补充
http://blog.csdn.net/mytestmy/article/details/26961315
这篇文章补充了其他的词表示方法,比如 one hot,n-gram,bag of words等等。