循环神经网络应用案例
基础介绍可以参考:
https://blog.csdn.net/lilong117194/article/details/82958326
https://blog.csdn.net/lilong117194/article/details/81978203
tensorflow的编程堆栈示意图:
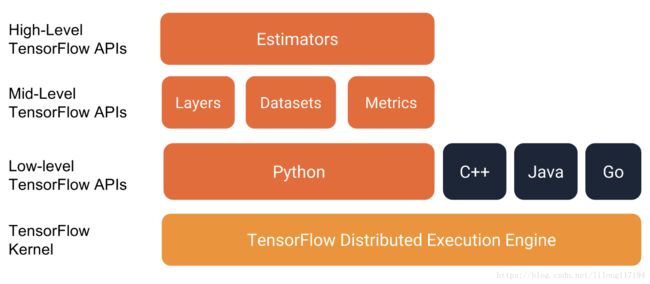
强烈建议使用以下API编写TensorFlow程序:
- 评估器Estimators,代表一个完整的模型。 Estimator API提供方法来训练模型,判断模型的准确性并生成预测。
- 训练集Datasets,它构建了一个数据输入管道。Datasets API具有加载和操作数据的方法,并将其输入到你的模型中。Datasets API与Estimators API良好地协作。
1. 基于TFlearn的iris分类
下面介绍利用tensorflow的一个高层封装TFlearn。
iris数据集需要通过4个特征来分辨三种类型的植物,iris数据集中总共包含了150个样本,下面是TFlearn解决iris分类问题:
数据集
鸢尾花数据集包含四个特征和一个标签。这四个特征确定了单个鸢尾花的以下植物学特征:
- 萼片长度
- 萼片宽度
- 花瓣长度
- 花瓣宽度
下表显示了数据集中的三个示例:
| 萼片长度 | 萼片宽度 | 花瓣长度 | 花瓣宽度 | 种类(标签) |
|---|---|---|---|---|
| 5.1 | 3.3 | 1.7 | 0.5 | 0(Setosa) |
| 5.0 | 2.3 | 3.3 | 1.0 | 1(Versicolor) |
| 6.4 | 2.8 | 5.6 | 2.2 | 2(virginica) |
完整代码:
from sklearn import model_selection
from sklearn import datasets
from sklearn import metrics
import tensorflow as tf
import numpy as np
from tensorflow.contrib.learn.python.learn.estimators.estimator import SKCompat
# 导入TFlearn
learn = tf.contrib.learn
# 自定义softmax回归模型:在给定输入的训练集、训练集标签,返回在这些输入上的预测值、损失值以及训练步骤
def my_model(features, target):
# 将预测目标转化为one-hot编码的形式,共有三个类别,所以向量长度为3
target = tf.one_hot(target, 3, 1, 0)
# 计算预测值及损失函数:封装了一个单层全连接的神经网络
logits = tf.contrib.layers.fully_connected(features, 3, tf.nn.softmax)
loss = tf.losses.softmax_cross_entropy(target, logits)
# 创建模型的优化器,并优化步骤
train_op = tf.contrib.layers.optimize_loss(
loss, # 损失函数
tf.contrib.framework.get_global_step(), # 获取训练步骤并在训练时更新
optimizer='Adam', # 定义优化器
learning_rate=0.01) # 定义学习率
# 返回给定数据集上的预测结果、损失值以及优化步骤
return tf.arg_max(logits, 1), loss, train_op
# 加载iris数据集,并划分为训练集和测试集
iris = datasets.load_iris()
x_train, x_test, y_train, y_test = model_selection.train_test_split(
iris.data, iris.target, test_size=0.2, random_state=0)
#将数据转化成TensorFlow要求的float32格式
x_train, x_test = map(np.float32, [x_train, x_test])
# 封装和训练模型,输出准确率
classifier = SKCompat(learn.Estimator(model_fn=my_model, model_dir="Models/model_1"))
classifier.fit(x_train, y_train, steps=100)
# 预测
y_predicted = [i for i in classifier.predict(x_test)]
# 计算准确度
score = metrics.accuracy_score(y_test, y_predicted)
print('Accuracy: %.2f%%' % (score * 100))
运行结果:
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_task_type': None, '_task_id': 0, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x12a8484e0>, '_master': '', '_num_ps_replicas': 0, '_num_worker_replicas': 0, '_environment': 'local', '_is_chief': True, '_evaluation_master': '', '_train_distribute': None, '_device_fn': None, '_tf_config': gpu_options {
per_process_gpu_memory_fraction: 1.0
}
, '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_secs': 600, '_log_step_count_steps': 100, '_session_config': None, '_save_checkpoints_steps': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_model_dir': 'Models/model_1'}
INFO:tensorflow:Create CheckpointSaverHook.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from Models/model_1/model.ckpt-300
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Saving checkpoints for 300 into Models/model_1/model.ckpt.
INFO:tensorflow:loss = 0.66411054, step = 301
INFO:tensorflow:Saving checkpoints for 400 into Models/model_1/model.ckpt.
INFO:tensorflow:Loss for final step: 0.64143056.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from Models/model_1/model.ckpt-400
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
Accuracy: 100.00%
下图说明了特征,隐藏层和预测(并未显示隐藏层中的所有节点):
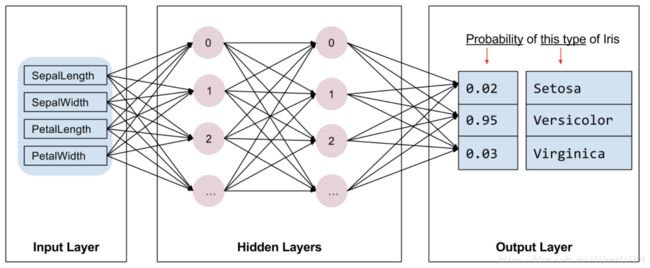
下面是评估器(Estimator)编程的基本概念:
Estimator是TensorFlow对完整模型的高级表示。它处理初始化,记录,保存和恢复以及许多其他功能的细节。
Estimator是从tf.estimator.Estimator派生的通用类。 TensorFlow提供了一系列定制的评估器(例如LinearRegressor)来实现常用的ML算法。除此之外,也可以编写自己的定制评估器。但建议在刚开始使用TensorFlow时使用内置的Estimator。在获得内置的Estimator的专业知识后,就可以通过创建定制Estimator来优化模型。
要根据内置的Estimator编写TensorFlow程序,必须执行以下任务:
- 创建一个或多个输入函数。
- 定义模型的特征列。
- 实例化Estimator,指定特征列和各种超参数。
- 在Estimator对象上调用一个或多个方法,传递适当的输入函数作为数据源。
2. lstm预测正弦函数
下面是利用lstm来实现预测正弦函数sin。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import numpy as np
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.estimators.estimator import SKCompat
from tensorflow.python.ops import array_ops as array_ops_
import matplotlib.pyplot as plt
learn = tf.contrib.learn
# 设置神经网络的参数
HIDDEN_SIZE = 30 # LSTM中隐藏的节点个数
NUM_LAYERS = 2 # LSTM的层数
TIMESTEPS = 10 # 循环神经网路的截断长度
TRAINING_STEPS = 3000 # 循环轮数
BATCH_SIZE = 32 # batch大小
TRAINING_EXAMPLES = 10000 # 训练数据的个数
TESTING_EXAMPLES = 1000 # 测试数据的个数
SAMPLE_GAP = 0.01 # 采样间隔
# 定义生成正弦数据的函数
def generate_data(seq):
X = []
y = []
# 序列的第i项和后面的TIMESTEPS-1项合在一起作为输入;第i + TIMESTEPS项作为输
# 出。即用sin函数前面的TIMESTEPS个点的信息,预测第i + TIMESTEPS个点的函数值。
for i in range(len(seq) - TIMESTEPS):
X.append([seq[i: i + TIMESTEPS]])
y.append([seq[i + TIMESTEPS]])
return np.array(X, dtype=np.float32), np.array(y, dtype=np.float32)
# 用正弦函数生成训练和测试数据集合。
test_start = (TRAINING_EXAMPLES + TIMESTEPS) * SAMPLE_GAP # (10000+10)*0.01=100
test_end = test_start + (TESTING_EXAMPLES + TIMESTEPS) * SAMPLE_GAP # 100+(1000+10)*0.01=110
train_X, train_y = generate_data(np.sin(np.linspace(
0, test_start, TRAINING_EXAMPLES + TIMESTEPS, dtype=np.float32)))
test_X, test_y = generate_data(np.sin(np.linspace(
test_start, test_end, TESTING_EXAMPLES + TIMESTEPS, dtype=np.float32)))
# 定义lstm模型
def lstm_model(X, y, is_training):
# 使用多层的LSTM结构。
cell = tf.nn.rnn_cell.MultiRNNCell([
tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE)
for _ in range(NUM_LAYERS)])
# 使用TensorFlow接口将多层的LSTM结构连接成RNN网络并计算其前向传播结果。
outputs, _ = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32)
#print(len(outputs))
output = outputs[:, -1, :]
# 对LSTM网络的输出再做加一层全链接层并计算损失。注意这里默认的损失为平均平方差损失函数。
predictions = tf.contrib.layers.fully_connected(
output, 1, activation_fn=None)
# 只在训练时计算损失函数和优化步骤。测试时直接返回预测结果。
if not is_training:
return predictions, None, None
# 计算损失函数。
loss = tf.losses.mean_squared_error(labels=y, predictions=predictions)
# 创建模型优化器并得到优化步骤。
train_op = tf.contrib.layers.optimize_loss(
loss, tf.train.get_global_step(),
optimizer="Adagrad", learning_rate=0.1)
return predictions, loss, train_op
"""
定义测试方法
"""
def run_eval(sess, test_X, test_y):
# 将测试数据以数据集的方式提供给计算图。
ds = tf.data.Dataset.from_tensor_slices((test_X, test_y))
ds = ds.batch(1)
X, y = ds.make_one_shot_iterator().get_next()
# 调用模型得到计算结果。这里不需要输入真实的y值。
with tf.variable_scope("model", reuse=True):
prediction, _, _ = lstm_model(X, [0.0], False)
# 将预测结果存入一个数组。
predictions = []
labels = []
for i in range(TESTING_EXAMPLES):
p, l = sess.run([prediction, y])
predictions.append(p)
labels.append(l)
# 计算mse作为评价指标。
predictions = np.array(predictions).squeeze()
labels = np.array(labels).squeeze()
rmse = np.sqrt(((predictions - labels) ** 2).mean(axis=0))
print("Root Mean Square Error is: %f" % rmse)
#对预测的sin函数曲线进行绘图。
plt.figure()
plt.plot(predictions, label='predictions')
plt.plot(labels, label='real_sin')
plt.legend()
plt.show()
"""
执行训练和测试
"""
# 将训练数据以数据集的方式提供给计算图。
print(train_X.shape)
print(train_y.shape)
ds = tf.data.Dataset.from_tensor_slices((train_X, train_y))
ds = ds.repeat().shuffle(1000).batch(BATCH_SIZE)
X, y = ds.make_one_shot_iterator().get_next()
# 定义模型,得到预测结果、损失函数,和训练操作。
with tf.variable_scope("model"):
_, loss, train_op = lstm_model(X, y, True)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 测试在训练之前的模型效果。
print ("Evaluate model before training.")
run_eval(sess, test_X, test_y)
# 训练模型。
for i in range(TRAINING_STEPS):
_, l = sess.run([train_op, loss])
if i % 1000 == 0:
print("train step: " + str(i) + ", loss: " + str(l))
# 使用训练好的模型对测试数据进行预测。
print ("Evaluate model after training.")
run_eval(sess, test_X, test_y)
运行结果:
(10000, 1, 10)
(10000, 1)
Evaluate model before training.
Root Mean Square Error is: 0.688176
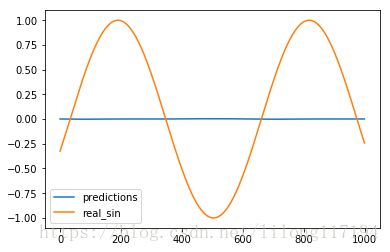
train step: 0, loss: 0.5273397
train step: 1000, loss: 0.000585775
train step: 2000, loss: 0.0003093369
Evaluate model after training.
Root Mean Square Error is: 0.007838
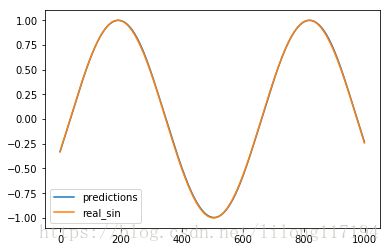
预测曲线基本重合与目标曲线。
3. tf.data.Dataset.from_tensor_slices和repeat()、shuffle()、batch()使用
- tf.data.Dataset.from_tensor_slices使用
(1)简单数组数列使用
import tensorflow as tf
import numpy as np
## 数据集对象实例化
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0]))
# # 迭代器对象实例化
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session() as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
运行结果:
1.0
2.0
3.0
4.0
5.0
end!
(2)多维数据使用
import tensorflow as tf
import numpy as np
dataset = tf.data.Dataset.from_tensor_slices(np.random.uniform(size=(5, 2)))
print('dataset:',dataset)
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session() as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
运行结果:
dataset: <TensorSliceDataset shapes: (2,), types: tf.float64>
[0.1792582 0.9751422]
[0.19793807 0.33374795]
[0.03978658 0.6808261 ]
[0.98788989 0.07403864]
[0.32259662 0.50171158]
end!
传入的数值是一个矩阵,它的形状为(5, 2),tf.data.Dataset.from_tensor_slices就会切分它形状上的第一个维度,最后生成的dataset中一个含有5个元素(但这里的元素个数不知道),每个元素的形状是(2, ),即每个元素是矩阵的一行。
(3)字典使用
import tensorflow as tf
import numpy as np
# 数据集对象实例化
dataset = tf.data.Dataset.from_tensor_slices(
{
"a": np.array([1.0, 2.0, 3.0, 4.0, 5.0]),
"b": np.random.uniform(size=(5, 2))
})
# 迭代器对象实例化
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session() as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
运行结果:
{'a': 1.0, 'b': array([0.04879087, 0.22908515])}
{'a': 2.0, 'b': array([0.11519196, 0.78684246])}
{'a': 3.0, 'b': array([0.86009348, 0.41073689])}
{'a': 4.0, 'b': array([0.80116343, 0.4113549 ])}
{'a': 5.0, 'b': array([0.545203 , 0.23978585])}
end!
对于复杂的情形,比如元素是一个python中的元组或者字典:在图像识别中一个元素可以是{”image”:image_tensor,”label”:label_tensor}的形式。 如上所示,这时函数会分别切分”label”中的数值以及”fea”中的数值,最后总dataset中的一个元素就是类似于{ “a”:1.0, “b”:[0.9,0.1] }的形式。
(4)复杂的tuple组合数据
import tensorflow as tf
import numpy as np
dataset = tf.data.Dataset.from_tensor_slices(
(np.array([1.0, 2.0, 3.0, 4.0, 5.0]), np.random.uniform(size=(5, 2)))
)
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session() as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
运行结果:
(1.0, array([0.61708973, 0.73534924]))
(2.0, array([0.64866959, 0.04011806]))
(3.0, array([0.07455173, 0.02324372]))
(4.0, array([0.53580828, 0.19761375]))
(5.0, array([0.63886913, 0.56859266]))
end!
- repeat()、shuffle()、batch()使用
Dataset支持一类特殊的操作:Transformation。一个Dataset通过Transformation变成一个新的Dataset。通常我们可以通过Transformation完成数据变换,打乱,组成batch,生成epoch等一系列操作。
(1)batch的使用
import tensorflow as tf
import numpy as np
# 数据集对象实例化
dataset = tf.data.Dataset.from_tensor_slices(
{
"a": np.array([1.0, 2.0, 3.0, 4.0, 5.0]),
"b": np.random.uniform(size=(5, 2))
})
dataset = dataset.batch(2)
# 迭代器对象实例化
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session() as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
运行结果:
{'a': array([1., 2.]), 'b': array([[0.34187133, 0.40294537],
[0.14411398, 0.06565229]])}
{'a': array([3., 4.]), 'b': array([[0.58521367, 0.1550559 ],
[0.39541026, 0.87366261]])}
{'a': array([5.]), 'b': array([[0.10484032, 0.75835755]])}
end!
可以看出每两个数据组成一个batch
(2)shuffle的使用
shuffle的功能为打乱dataset中的元素,它有一个参数buffersize,表示打乱时使用的buffer的大小,建议设置不要太小,一般是1000:
import tensorflow as tf
import numpy as np
dataset = tf.data.Dataset.from_tensor_slices(
{
"a": np.array([1.0, 2.0, 3.0, 4.0, 5.0]),
"b": np.random.uniform(size=(5, 2))
})
dataset = dataset.shuffle(buffer_size=1000)
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session() as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
运行结果:
{'a': 3.0, 'b': array([0.60925085, 0.60532416])}
{'a': 2.0, 'b': array([0.66688525, 0.29313125])}
{'a': 1.0, 'b': array([0.10190033, 0.3020232 ])}
{'a': 4.0, 'b': array([0.20525341, 0.50205214])}
{'a': 5.0, 'b': array([0.4151064 , 0.00696569])}
(3)repeat的使用
repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch,假设原先的数据是一个epoch,使用repeat(2)就可以将之变成2个epoch:
import tensorflow as tf
import numpy as np
dataset = tf.data.Dataset.from_tensor_slices(
{
"a": np.array([1.0, 2.0, 3.0, 4.0, 5.0]),
"b": np.random.uniform(size=(5, 2))
})
dataset = dataset.repeat(3)
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session() as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
运行结果:
{'a': 1.0, 'b': array([0.14897444, 0.444479 ])}
{'a': 2.0, 'b': array([0.10113141, 0.89834262])}
{'a': 3.0, 'b': array([0.18748515, 0.95026317])}
{'a': 4.0, 'b': array([0.56672754, 0.26056881])}
{'a': 5.0, 'b': array([0.5487119 , 0.28498332])}
{'a': 1.0, 'b': array([0.14897444, 0.444479 ])}
{'a': 2.0, 'b': array([0.10113141, 0.89834262])}
{'a': 3.0, 'b': array([0.18748515, 0.95026317])}
{'a': 4.0, 'b': array([0.56672754, 0.26056881])}
{'a': 5.0, 'b': array([0.5487119 , 0.28498332])}
{'a': 1.0, 'b': array([0.14897444, 0.444479 ])}
{'a': 2.0, 'b': array([0.10113141, 0.89834262])}
{'a': 3.0, 'b': array([0.18748515, 0.95026317])}
{'a': 4.0, 'b': array([0.56672754, 0.26056881])}
{'a': 5.0, 'b': array([0.5487119 , 0.28498332])}
end!
参考:
https://zhuanlan.zhihu.com/p/27238630
https://www.cnblogs.com/hellcat/p/8569651.html