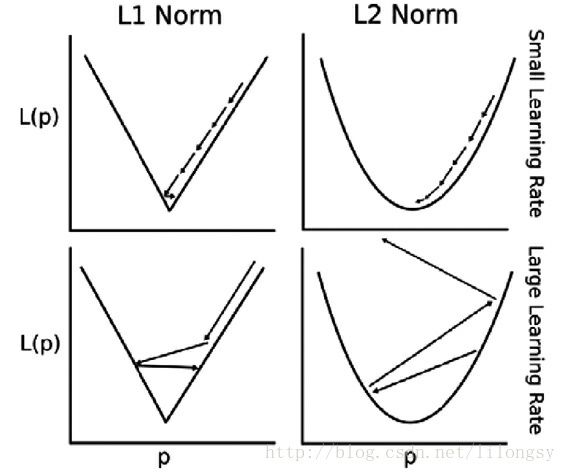
改变损失函数和学习率来观察收敛性
改变损失函数和学习率来观察收敛性的变化。
# Linear Regression: L1 vs L2
# 改变损失函数和学习率来观察收敛性的变化
#----------------------------------
#
# This function shows how to use TensorFlow to
# solve linear regression via the matrix inverse.
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn import datasets
from tensorflow.python.framework import ops
ops.reset_default_graph()
# Create graph
sess = tf.Session()
# Load the data
# iris.data = [(Sepal Length, Sepal Width, Petal Length, Petal Width)]
iris = datasets.load_iris()
x_vals = np.array([x[3] for x in iris.data])
y_vals = np.array([y[0] for y in iris.data])
# Declare batch size and number of iterations
batch_size = 25
learning_rate = 0.05 # 学习率0.4将不会收敛
iterations = 50
# Initialize placeholders
x_data = tf.placeholder(shape=[None, 1], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
# Create variables for linear regression
A = tf.Variable(tf.random_normal(shape=[1,1]))
b = tf.Variable(tf.random_normal(shape=[1,1]))
# Declare model operations
model_output = tf.add(tf.matmul(x_data, A), b)
# 损失函数改为L1正则损失函数
loss_l1 = tf.reduce_mean(tf.abs(y_target - model_output))
# Declare optimizers
my_opt_l1 = tf.train.GradientDescentOptimizer(learning_rate)
train_step_l1 = my_opt_l1.minimize(loss_l1)
# Initialize variables
init = tf.global_variables_initializer()
sess.run(init)
# Training loop
loss_vec_l1 = []
for i in range(iterations):
rand_index = np.random.choice(len(x_vals), size=batch_size)
rand_x = np.transpose([x_vals[rand_index]])
rand_y = np.transpose([y_vals[rand_index]])
sess.run(train_step_l1, feed_dict={x_data: rand_x, y_target: rand_y})
temp_loss_l1 = sess.run(loss_l1, feed_dict={x_data: rand_x, y_target: rand_y})
loss_vec_l1.append(temp_loss_l1)
if (i+1)%25==0:
print('Step #' + str(i+1) + ' A = ' + str(sess.run(A)) + ' b = ' + str(sess.run(b)))
# L2 Loss
# Reinitialize graph
ops.reset_default_graph()
# Create graph
sess = tf.Session()
# Initialize placeholders
x_data = tf.placeholder(shape=[None, 1], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
# Create variables for linear regression
A = tf.Variable(tf.random_normal(shape=[1,1]))
b = tf.Variable(tf.random_normal(shape=[1,1]))
# Declare model operations
model_output = tf.add(tf.matmul(x_data, A), b)
# 损失函数改为L2正则损失函数
loss_l2 = tf.reduce_mean(tf.square(y_target - model_output))
# Declare optimizers
my_opt_l2 = tf.train.GradientDescentOptimizer(learning_rate)
train_step_l2 = my_opt_l2.minimize(loss_l2)
# Initialize variables
init = tf.global_variables_initializer()
sess.run(init)
loss_vec_l2 = []
for i in range(iterations):
rand_index = np.random.choice(len(x_vals), size=batch_size)
rand_x = np.transpose([x_vals[rand_index]])
rand_y = np.transpose([y_vals[rand_index]])
sess.run(train_step_l2, feed_dict={x_data: rand_x, y_target: rand_y})
temp_loss_l2 = sess.run(loss_l2, feed_dict={x_data: rand_x, y_target: rand_y})
loss_vec_l2.append(temp_loss_l2)
if (i+1)%25==0:
print('Step #' + str(i+1) + ' A = ' + str(sess.run(A)) + ' b = ' + str(sess.run(b)))
# Plot loss over time
plt.plot(loss_vec_l1, 'k-', label='L1 Loss')
plt.plot(loss_vec_l2, 'r--', label='L2 Loss')
plt.title('L1 and L2 Loss per Generation')
plt.xlabel('Generation')
plt.ylabel('L1 Loss')
plt.legend(loc='upper right')
plt.show()
如果学习率太小,算法收敛耗时将更长。但是如果学习率太大,算法有可能产生不收敛的问题。下面绘制iris数据的线性回归问题的L1正则和L2正则损失(见下图),其中学习率为0.05。
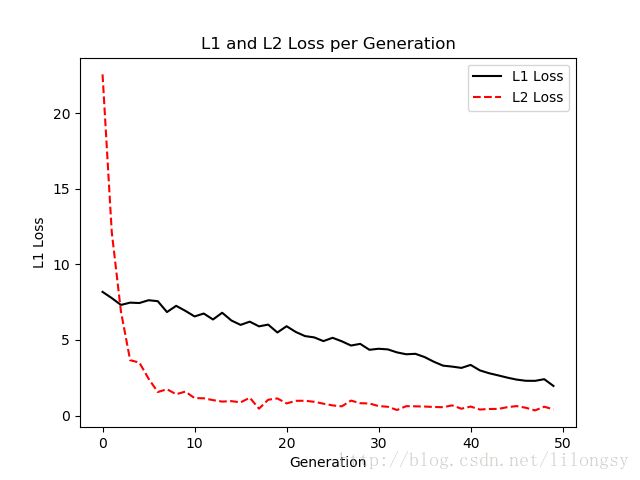
iris数据线性回归的L1正则和L2正则损失,学习率为0.05。
从上图中可以看出,当学习率为0.05时,L2正则损失更优,其有更低的损失值。当增加学习率为0.4时,绘制其损失函数(见下图)。
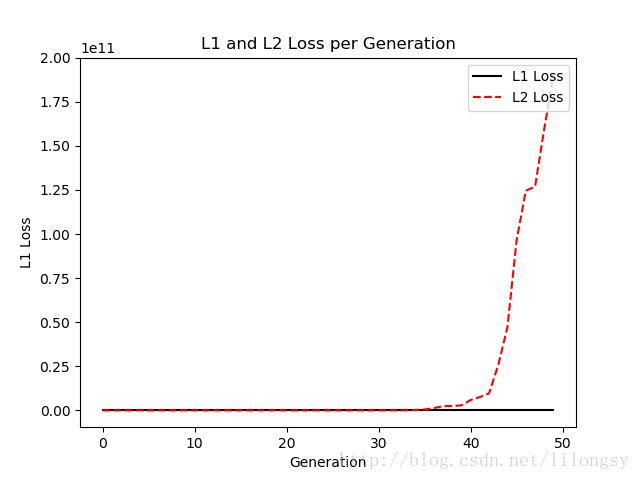
iris数据线性回归的L1正则和L2正则损失,学习率为0.4。其中L1正则损失不可见是因为它的y轴值太大。学习率大导致L2损失过大,而L1正则损失收敛。
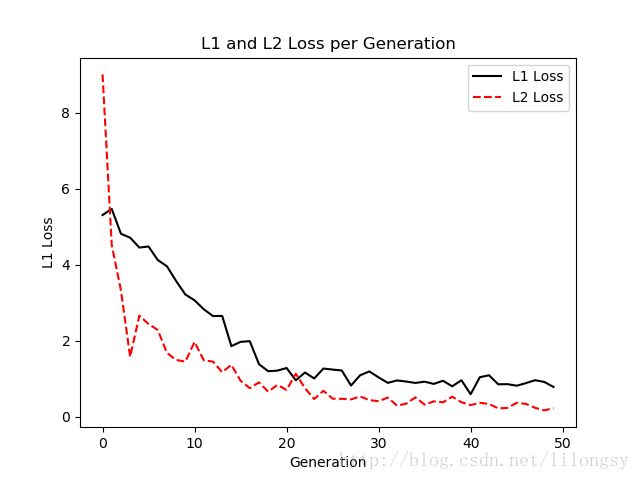
学习率0.1
这里清晰地展示大学习率和小学习率对L1正则和L2正则损失函数的影响。这里可视化的是L1正则和L2正则损失函数的一维情况,如下图。