工作流平台airflow简介
airflow 介绍
airflow 是什么
Airflow is a platform to programmatically author, schedule and monitor
workflows.
airflow 是一个编排、调度和监控workflow的平台,由Airbnb开源,现在在Apache Software Foundation 孵化。airflow 将workflow编排为tasks组成的DAGs,调度器在一组workers上按照指定的依赖关系执行tasks,具有非常强大的表达能力。。同时,airflow 提供了丰富的命令行工具和简单易用的用户界面以便用户查看和操作,并且airflow提供了监控和报警系统。
airflow 核心概念
DAGs:即有向无环图(Directed Acyclic Graph),将所有需要运行的tasks按照依赖关系组织起来,描述的是所有tasks执行的顺序。
Operators:可以简单理解为一个class,描述了DAG中一个具体的task具体要做的事。其中,airflow内置了很多operators,如BashOperator 执行一个bash 命令,PythonOperator 调用任意的Python 函数,EmailOperator 用于发送邮件,HTTPOperator 用于发送HTTP请求, SqlOperator 用于执行SQL命令…同时,用户可以自定义Operator,这给用户提供了极大的便利性。
Tasks:Task 是 Operator的一个实例,也就是DAGs中的一个node。
Task Instance:task的一次运行。task instance 有自己的状态,包括"running", “success”, “failed”, “skipped”, "up for retry"等。
Task Relationships:DAGs中的不同Tasks之间可以有依赖关系,如 TaskA >> TaskB,表明TaskB依赖于TaskA。
通过将DAGs和Operators结合起来,用户就可以创建各种复杂的 workflow了。
Connections: 管理外部系统的连接信息,如外部MySQL、HTTP服务等,连接信息包括conn_id/hostname / login / password/schema 等,可以通过界面查看和管理,编排workflow时,使用conn_id 进行使用。
Pools: 用来控制tasks执行的并行数。将一个task赋给一个指定的pool,并且指明priority_weight,可以干涉tasks的执行顺序。
XComs:在airflow中,operator一般(not always)是原子的,也就是说,他们一般独立执行,同时也不需要和其他operator共享信息,如果两个operators需要共享信息,如filename之类的, 推荐将这两个operators组合成一个operator。如果实在不能避免,则可以使用XComs (cross-communication)来实现。XComs用来在不同tasks之间交换信息。
Trigger Rules:指task的触发条件。默认情况下是task的直接上游执行成功后开始执行,airflow允许更复杂的依赖设置,包括all_success(所有的父节点执行成功),all_failed(所有父节点处于failed或upstream_failed状态),all_done(所有父节点执行完成),one_failed(一旦有一个父节点执行失败就触发,不必等所有父节点执行完成),one_success(一旦有一个父节点执行成功就触发,不必等所有父节点执行完成),dummy(依赖关系只是用来查看的,可以任意触发)。另外,airflow提供了depends_on_past,设置为True时,只有上一次调度成功了,才可以触发。
airflow 的守护进程
airflow 系统在运行时有许多守护进程,它们提供了 airflow 的全部功能。守护进程包括 Web服务器-webserver、调度程序-scheduler、执行单元-worker、消息队列监控工具-Flower等。下面是 apache-airflow 集群、高可用部署的主要守护进程。
webserver
webserver 是一个守护进程,它接受 HTTP 请求,允许你通过 Python Flask Web 应用程序与 airflow 进行交互,webserver 提供以下功能:
- 中止、恢复、触发任务。
- 监控正在运行的任务,断点续跑任务。
- 执行 ad-hoc 命令或 SQL 语句来查询任务的状态,日志等详细信息。
- 配置连接,包括不限于数据库、ssh 的连接等。
webserver 守护进程使用 gunicorn 服务器(相当于 java 中的 tomcat )处理并发请求,可通过修改{AIRFLOW_HOME}/airflow.cfg文件中 workers 的值来控制处理并发请求的进程数。
例如:
workers = 4 #表示开启4个gunicorn worker(进程)处理web请求
启动 webserver 守护进程:
$ airfow webserver -D
scheduler
scheduler 是一个守护进程,它周期性地轮询任务的调度计划,以确定是否触发任务执行。
启动的 scheduler 守护进程:
$ airfow scheduler -D
worker
worker 是一个守护进程,它启动 1 个或多个 Celery 的任务队列,负责执行具体 的 DAG 任务。
当设置 airflow 的 executors 设置为 CeleryExecutor 时才需要开启 worker 守护进程。推荐你在生产环境使用 CeleryExecutor :
executor = CeleryExecutor
启动一个 worker守护进程,默认的队列名为 default:
$ airfow worker -D
flower
flower 是一个守护进程,用于是监控 celery 消息队列。启动守护进程命令如下:
$ airflow flower -D
默认的端口为 5555,您可以在浏览器地址栏中输入 "http://hostip:5555" 来访问 flower ,对 celery 消息队列进行监控。
airflow 的守护进程是如何一起工作的?
需要注意的是 airflow 的守护进程彼此之间是独立的,他们并不相互依赖,也不相互感知。每个守护进程在运行时只处理分配到自己身上的任务,他们在一起运行时,提供了 airflow 的全部功能。
- 调度器 scheduler 会间隔性的去轮询元数据库(Metastore)已注册的 DAG(有向无环图,可理解为作业流)是否需要被执行。如果一个具体的 DAG 根据其调度计划需要被执行,scheduler 守护进程就会先在元数据库创建一个 DagRun 的实例,并触发 DAG 内部的具体 task(任务,可以这样理解:DAG 包含一个或多个task),触发其实并不是真正的去执行任务,而是推送 task 消息至消息队列(即 broker)中,每一个 task 消息都包含此 task 的 DAG ID,task ID,及具体需要被执行的函数。如果 task 是要执行 bash 脚本,那么 task 消息还会包含 bash 脚本的代码。
- 用户可能在 webserver 上来控制 DAG,比如手动触发一个 DAG 去执行。当用户这样做的时候,一个DagRun 的实例将在元数据库被创建,scheduler 使同 #1 一样的方法去触发 DAG 中具体的 task 。
- worker 守护进程将会监听消息队列,如果有消息就从消息队列中取出消息,当取出任务消息时,它会更新元数据中的 DagRun 实例的状态为正在运行,并尝试执行 DAG 中的 task,如果 DAG 执行成功,则更新任 DagRun 实例的状态为成功,否则更新状态为失败。
示例
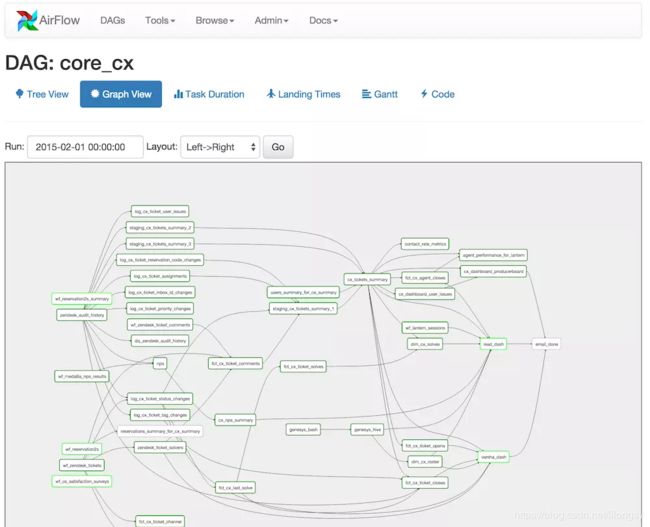
先来看一个简单的DAG。图中每个节点表示一个task,所有tasks组成一个DAG,各个tasks之间的依赖关系可以根据节点之间的线看出来。
DAGs
实例化DAG
# -*- coding: UTF-8 -*-
## 导入airflow需要的modules
from airflow import DAG
from datetime import datetime, timedelta
default_args = {
'owner': 'lxwei',
'depends_on_past': False, # 如上文依赖关系所示
'start_date': datetime(2018, 1, 17), # DAGs都有个参数start_date,表示调度器调度的起始时间
'email': ['[email protected]'], # 用于alert
'email_on_failure': True,
'email_on_retry': False,
'retries': 3, # 重试策略
'retry_delay': timedelta(minutes=5)
}
dag = DAG('example-dag', default_args=default_args, schedule_interval='0 0 * * *')
在创建DAGs时,我们可以显示的给每个Task传递参数,但通过default_args,我们可以定义一个默认参数用于创建tasks。
注意,schedule_interval 跟官方文档不一致,官方文档的方式已经被deprecated。
定义依赖关系
这个依赖关系是我自己定义的,key表示某个taskId,value里的每个元素也表示一个taskId,其中,key依赖value里的所有task。
"dependencies": {
"goods_sale_2": ["goods_sale_1"], # goods_sale_2 依赖 goods_sale1
"shop_sale_1_2": ["shop_sale_1_1"],
"shop_sale_2_2": ["shop_sale_2_1"],
"shop_sale_2_3": ["shop_sale_2_2"],
"etl_task": ["shop_info", "shop_sale_2_3", "shop_sale_realtime_1", "goods_sale_2", "shop_sale_1_2"],
"goods_sale_1": ["timelySalesCheck", "productDaySalesCheck"],
"shop_sale_1_1": ["timelySalesCheck", "productDaySalesCheck"],
"shop_sale_realtime_1": ["timelySalesCheck", "productDaySalesCheck"],
"shop_sale_2_1": ["timelySalesCheck", "productDaySalesCheck"],
"shop_info": ["timelySalesCheck", "productDaySalesCheck"]
}
定义tasks和依赖关系
首先,实例化operators,构造tasks。如代码所示,其中,EtlTask、MySQLToWebDataTransfer、MySQLSelector 是自定义的三种Operator,根据taskType实例化operator,并存放到taskDict中,便于后期建立tasks之间的依赖关系。
for taskConf in tasksConfs:
taskType = taskConf.get("taskType")
if taskType == "etlTask":
task = EtlTask(
task_id=taskConf.get("taskId"),
httpConnId=httpConn,
etlId=taskConf.get("etlId"),
dag=dag)
taskDict[taskConf.get("taskId")] = task
elif taskType == "MySQLToWebDataTransfer":
task = MySqlToWebdataTransfer(
task_id = taskConf.get("taskId"),
sql= taskConf.get("sql"),
tableName=taskConf.get("tableName"),
mysqlConnId =mysqlConn,
httpConnId=httpConn,
dag=dag
)
taskDict[taskConf.get("taskId")] = task
elif taskType == "MySQLSelect":
task = StatusChecker(
task_id = taskConf.get("taskId"),
mysqlConnId = mysqlConn,
sql = taskConf.get("sql"),
dag = dag
)
taskDict[taskConf.get("taskId")] = task
else:
logging.error("error. TaskType is illegal.")
构建tasks之间的依赖关系,其中,dependencies中定义了上面的依赖关系,A >> B 表示A是B的父节点,相应的,A << B 表示A是B的子节点。
for sourceKey in dependencies:
destTask = taskDict.get(sourceKey)
sourceTaskKeys = dependencies.get(sourceKey)
for key in sourceTaskKeys:
sourceTask = taskDict.get(key)
if (sourceTask != None and destTask != None):
sourceTask >> destTask
常用命令
命令行输入airflow -h,得到帮助文档
backfill Run subsections of a DAG for a specified date range
list_tasks List the tasks within a DAG
clear Clear a set of task instance, as if they never ran
pause Pause a DAG
unpause Resume a paused DAG
trigger_dag Trigger a DAG run
pool CRUD operations on pools
variables CRUD operations on variables
kerberos Start a kerberos ticket renewer
render Render a task instance's template(s)
run Run a single task instance
initdb Initialize the metadata database
list_dags List all the DAGs
dag_state Get the status of a dag run
task_failed_deps Returns the unmet dependencies for a task instance
from the perspective of the scheduler. In other words,
why a task instance doesn't get scheduled and then
queued by the scheduler, and then run by an executor).
task_state Get the status of a task instance
serve_logs Serve logs generate by worker
test Test a task instance. This will run a task without
checking for dependencies or recording it's state in
the database.
webserver Start a Airflow webserver instance
resetdb Burn down and rebuild the metadata database
upgradedb Upgrade the metadata database to latest version
scheduler Start a scheduler instance
worker Start a Celery worker node
flower Start a Celery Flower
version Show the version
connections List/Add/Delete connections
其中,使用较多的是backfill、run、test、webserver、scheduler。其他操作在web界面操作更方便。另外,initdb 用于初始化metadata,使用一次即可;resetdb会重置metadata,清除掉数据(如connection数据), 需要慎用。
问题
在使用airflow过程中,曾把DAGs里的task拆分得很细,这样的话,如果某个task失败,重跑的代价会比较低。但是,在实践中发现,tasks太多时,airflow在调度tasks会很低效,airflow一直处于选择待执行的task的过程中,会长时间没有具体task在执行,从而整体执行效率大幅降低。
总结
airflow 很好很强大。如果只是简单的ETL之类的工作,可以很容易的编排。调度灵活,而且监控和报警系统完备,可以很方便的投入生产环节。
参阅
airflow 官网:https://airflow.apache.org/
github:https://github.com/apache/airflow
https://www.jianshu.com/p/2ecef979c606
https://www.jianshu.com/p/e878bbc9ead2