序列化与反序列化
序列化与反序列化的含义
在平时写代码过程中,对象是可复用的,但是这个前提条件是只有当JVM处于运行时,这些对象才可能存在。在现实应用中,就可能要求在JVM停止运行之后能保存指定的对象,并在将来重新读取被保存的对象。Java对象序列化就能够完成这个功能。
简单点理解就是
序列化:把对象的状态信息转化为可存储或可传输的形式,也就是把对象转化为字节序列的过程即为对象的序列化。
反序列化:就是序列化的逆过程,把字节数组反序列化为对象,把字节序列会恢复为对象的过程,就是反序列化。
Java语言本身为我们提供了序列化的操作,下面就通过简单实例进行梳理。
Java序列化操作
直接上实例吧
自己编写的序列化类
package com.learn.serializable.self;
import com.learn.serializable.ref.ISerializer;
import java.io.*;
/**
* Created by liman on 2018/8/12.
* QQ:657271181
* e-mail:[email protected]
*
* 简单的序列化和反序列化实现
*/
public class JavaSerializer implements ISerializer{
/**
* 序列化操作
* @param obj
* @param
* @return
*/
@Override
public byte[] serializer(T obj) {
ObjectOutputStream objectOutputStream = null;
try {
objectOutputStream = new ObjectOutputStream(new FileOutputStream(new File("test")));
objectOutputStream.writeObject(obj);
} catch (IOException e) {
e.printStackTrace();
}finally {
if(objectOutputStream!=null){
try {
objectOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return null;
}
/**
* 反序列化操作
* @param data
* @param clazz
* @param
* @return
*/
@Override
public T deSerializer(byte[] data, Class clazz) {
ObjectInputStream objectInputStream = null;
try {
objectInputStream = new ObjectInputStream(new FileInputStream(new File("test")));
return (T)objectInputStream.readObject();
} catch (Exception e) {
e.printStackTrace();
}finally {
if(objectInputStream!=null){
try {
objectInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return null;
}
}
实例类,需要实现serializable接口
package com.learn.serializable.self;
import java.io.Serializable;
/**
* Created by liman on 2018/8/12.
* QQ:657271181
* e-mail:[email protected]
*/
public class User implements Serializable{
private String username;
private int age;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"username='" + username + '\'' +
", age=" + age +
'}';
}
}
测试代码:
package com.learn.serializable.self;
import com.learn.serializable.ref.ISerializer;
/**
* Created by liman on 2018/8/12.
* QQ:657271181
* e-mail:[email protected]
*
* 简单序列化实例
*/
public class SimpleSerializerDemo {
public static void main(String[] args) {
ISerializer serializer = new JavaSerializer();
User user = new User();
user.setAge(18);
user.setUsername("liman");
byte[] serializerByte = serializer.serializer(user);//序列化
//反序列化
User serializeUser = serializer.deSerializer(serializerByte, User.class);
System.out.println(serializeUser.toString());
}
}
上述的代码,序列化的时候会在工程目录的根目录下输出一个test的文件,反序列化的时候会读取这个文件,然后将对象输出,序列化后的文件如下图所示:

序列化的一些细节
serialVersionUID
这个字段在实际编码的过程中,如果没有指定,那么java编译器会自动给这个对象进行一个摘要算法,只要文件有任何改动,这个serialVersionUID就会截然不同,可以保证这么多类中,这个编号是唯一的。这个字段更多的作用,就是在反序列化的时候,JVM会根据传过来的serialVersionUID字段与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化操作,否则就会出现序列化版本不一致的异常,抛出一个经典的异常——InvalidCastException.
serialVersionUID有两种生成方式:
1:默认的1L,例:private static final long serialVersionUID = 1L;
2:根据类名、接口名、成员方法及属性等生成一个64位的哈希字段。当实现了serializable接口的类没有这个字段的时候,Java序列化机制会根据编译的Class自动生成一个serialVersionUID做序列化版本比较用,在这种情况下,如果Class文件没有发生变化,就算再编译多次,serialVersionUID也不会变化。
静态变量序列化
对象序列化的时候,并不会保存静态变量的状态。这个在上面的例子做一个修改就可以看出来
User中增加一个静态的num属性
package com.learn.serializable.self;
import java.io.Serializable;
/**
* Created by liman on 2018/8/12.
* QQ:657271181
* e-mail:[email protected]
*/
public class User implements Serializable{
private String username;
private int age;
//静态变量并不会被序列化
public static int num = 5;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"username='" + username + '\'' +
", age=" + age +
'}';
}
}
测试代码
package com.learn.serializable.self;
import com.learn.serializable.ref.ISerializer;
/**
* Created by liman on 2018/8/12.
* QQ:657271181
* e-mail:[email protected]
*
* 简单序列化实例
*/
public class SimpleSerializerDemo {
public static void main(String[] args) {
ISerializer serializer = new JavaSerializer();
User user = new User();
user.setAge(18);
user.setUsername("liman");
byte[] serializerByte = serializer.serializer(user);//序列化
user.num = 10;
//反序列化
User serializeUser = serializer.deSerializer(serializerByte, User.class);
System.out.println(serializeUser.toString());
//这里输出的是10,并不是5
System.out.println(serializeUser.num);
}
}
运行结果
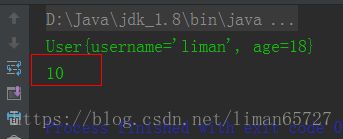
上述的输出结果并不是5,并不是序列化之前的结果,如果序列化了静态变量,输出的结果应该是5,而这里是10。其实也比较好理解,序列化保存的是对象的状态,而静态变量是属于类的状态,因此序列化并不保存静态变量。
父类的序列化
先看一个比较的实例,在之前的实例中增加一个SuperUser对象,如下所示:
package com.learn.serializable.self;
/**
* Created by liman on 2018/8/12.
* QQ:657271181
* e-mail:[email protected]
*/
public class SuperUser {
String sex;
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
}
然后让User继承至这个类,再在测试代码中增加如下代码:

上述实例中父类没有继承实例化接口,也就是Java没法对其实例化,但是User能进行实例化,并且对其中相关属性进行了设置。但在反序列化过程中,发现输出来的值为null,即最后一行代码输出为null。
结论:
1、当一个父类没有实现序列化时,子类继承该父类实现了序列化,在反序列化该子类之后,是没有办法获得父类的属性值的。
2、当一个父类实现了序列化,子类会自动实现序列化,不需要在显示的继承serializable接口,这一点可以通过修改上述代码后得到验证。
3、当一个对象的实例变量引用了其他对象,序列化该对象时也会把引用对象进行序列化,但是前提是该引用对象也实现了序列化接口。
Transient关键字
这个关键字的作用就是控制变量的序列化,在变量声明前加上这个关键字,这个字段就不会被序列化,在反序列化后,transient变量的值被设为初始值。可以在上述实例中的User对象中增加一个属性,声明为transient,会发现在反序列化的时候输出依旧为null。
序列化实现深克隆
深复制与浅复制,这个自己之前在设计模式中已经做过总结,这里再重新梳理一下。
浅复制
被复制的对象与原对象所有的变量有相同的值(废话),但是对于原对象中的引用类型,仍然指向原引用。(有点抽象)通过实例可以进一步理解。
实现一个邮件功能,告诉别人约一个饭局
Email代码,没有实现Serializable接口的。
package com.learn.clone;
/**
*
* @author liman
* @createtime 2018年8月13日
* @contract 15528212893
* @comment:
*
*/
public class Email {
private String content;
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
Person实例代码:
package com.learn.clone;
public class Person implements Cloneable{
private String name;
private Email email;
public Person(String name) {
super();
this.name = name;
}
@Override
protected Person clone() throws CloneNotSupportedException {
return (Person)super.clone();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Email getEmail() {
return email;
}
public void setEmail(Email email) {
this.email = email;
}
}
测试示例代码
package com.learn.clone;
/**
*
* @author liman
* @createtime 2018年8月13日
* @contract 15528212893
* @comment:
* 浅复制的示例
*/
public class CloneDemo {
public static void main(String[] args) throws CloneNotSupportedException {
Email email = new Email();
email.setContent("今天晚上要不要约一波饭?");
Person p1 = new Person("liman");
p1.setEmail(email);
Person p2 = p1.clone();
p2.setName("test");
p2.getEmail().setContent("今晚不约饭了,咱约架吧");
System.out.println(p1.getName()+"->"+p1.getEmail().getContent());
System.out.println(p2.getName()+"->"+p2.getEmail().getContent());
}
}
执行结果:

这就尴尬了,p2修改了邮件内容,结果p1的邮件内容也修改了,这就是浅复制,p2在复制了p1对象的时候,邮件对象只是复制了引用,并没有在内存区中新开辟一段区域用于存储邮件内容,所以这就是浅复制,但是可以利用序列化实现深复制
深复制
还是上述示例,个个代码如下:
Email实现了Serializable接口
package com.learn.clone.deepClone;
import java.io.Serializable;
/**
*
* @author liman
* @createtime 2018年8月13日
* @contract 15528212893
* @comment:
*
*/
public class Email implements Serializable{
private String content;
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
Person示例代码:
package com.learn.clone.deepClone;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class Person implements Cloneable,Serializable{
private String name;
private Email email;
public Person(String name) {
super();
this.name = name;
}
protected Person deepClone() throws IOException, ClassNotFoundException {
// 序列化
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
// 反序列化
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (Person) ois.readObject();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Email getEmail() {
return email;
}
public void setEmail(Email email) {
this.email = email;
}
}
测试代码:
package com.learn.clone.deepClone;
import java.io.IOException;
/**
*
* @author liman
* @createtime 2018年8月13日
* @contract 15528212893
* @comment:
*
*/
public class DeepCloneDemo {
public static void main(String[] args) throws ClassNotFoundException, IOException {
Email email = new Email();
email.setContent("今天晚上约一波饭");
Person p1 = new Person("liman");
p1.setEmail(email);
Person p2 = p1.deepClone();
p2.setName("test");
p2.getEmail().setContent("今晚约一波架");
System.out.println(p1.getName()+"->"+p1.getEmail().getContent());
System.out.println(p2.getName()+"->"+p2.getEmail().getContent());
}
}
运行结果:

现在约饭和约架就正常了, 序列化的原理就是将JVM中的对象序列化到一个流中,然后再从流中读取出来的对象就和原对象不一样。可以利用这一点实现深复制,但前提是所有引用的对象都必须实现Serializable接口,同时被克隆对象需要实现Cloneable接口。
常用的序列化框架
前面介绍的是Java自带的序列化框架,这个框架有优点也有缺点。优点是由java本身提供,使用非常方便。缺点也很明显,就是不支持跨语言处理,性能相对来说并不是很好,序列化后产生的数据相对较大。
XML序列化框架
WebService用的较多,性能较低,不做重点介绍
JSON序列化框架
有Jackson,FastJson(阿里开源的)GSON(google的),还有的就是Hessian(较好的跨平台性,Dubbo就是采用的这个实现),Protobuf(google的一种数据交换格式,独立于语言,跨平台)
Protobuf序列化框架
下面会重点介绍Protobuf的原理,及其使用方法,Protobuf非常适合用于对性能要求较高的RPC调用。Protobuf本身是跨平台的,所以其有自己的语法和编译器,本文会先介绍相关使用,实例介绍完成之后,会分析其编码压缩格式。
这一篇文章介绍的比较全面:protobuf深入分析
protobuf的hello world
关于protobuf的语法,这里不做详细的探讨,参考这篇博客就可以:protobuf语法简介
1、安装protobuf
protobuf在git上就有,直接git上搜索protobuf,出来的第一个就是,这里下载的是3.6.1-win32版本的,然后解压即可,这里没有做安装,直接解压到指定目录即可。

解压以后的目录如图所示,其中的bin文件夹下面就存在protoc.exe,这个就是protobuf的编译器,用于编译生成对应的语言文件。
2、编写proto文件
在bin目录下编写User.proto文件,这里我们简单定义两个属性,文件比较简单,如下所示
syntax = "proto2";
package com.learn.serializable.self;
option java_package="com.learn.serializable.self";
option java_outer_classname="UserProto";
message User{
required string name=1;
required int32 age=2;
}
这里为了简单,将文件直接放到了bin目录下。
3、用proto.exe直接编译文件

输出后,在输出目录下会多一个文件夹,这个文件夹的形式和在user.proto文件中定义的package一样。

编译之后,protobuf会自动生成对应的.java文件,然后直接将这个文件拷贝到项目中,就可以使用
4、在项目中简单使用生成的文件
首先需要引入指定的maven依赖
com.google.protobuf
protobuf-java
3.5.1
org.apache.commons
commons-lang3
3.3.2
com.thoughtworks.xstream
xstream
1.4.10
然后可以将上一步生成的文件拷贝到工程目录下,整个文件有700多行,已经为我们封装了相关的序列化操作。
5、简单测试protobuf的序列化与反序列化
package com.learn.serializable.self;
import com.google.protobuf.ByteString;
import com.google.protobuf.InvalidProtocolBufferException;
/**
* Created by liman on 2018/8/14.
* QQ:657271181
* e-mail:[email protected]
*
* Protobuf实现序列化的实例
*/
public class ProtobufDemo{
public static void main(String[] args) throws InvalidProtocolBufferException {
//利用protobuf进行序列化
UserProto.User user = UserProto.User.newBuilder().setName("liman").setAge(18).build();
ByteString bytes = user.toByteString();
System.out.println(bytes.size());
//利用protobuf进行反序列化
UserProto.User nUser = UserProto.User.parseFrom(bytes);
System.out.println(nUser);
}
}
运行结果:

可以看到,两个属性的对象,压缩到了9个byte,这个压缩比非常惊人,下面就会参考前面大牛的博客,梳理一下protobuf的存储方式。
Protobuf原理简单分析
总的来说,protobuf使用varint(zigzag)作为编码方式,使用T-L-V作为存储方式。
Varint编码方式
Varint是一种紧凑的数字的表示方式,值越小的数字,就能减少表示数字的字节数。
通常对于int32类型的数字,都需要4个byte来表示,但是采用varint方式,对于很小的int32类型的直接,可以压缩到一个byte来表示。
varint编码中,每一个byte的最高位都有特殊含义,如果该位为1,表示后续的byte也是该数字的一部分,如果该位为0,则表示结束。
下面以300为例,介绍一下varint的编码方式
300的二进制编码(32位):0000 0000 0000 0000 0000 0001 0010 1100
转换成varint编码需要经过以下几个步骤:
1、截取末尾7位,并在最高位补1,得到1010 1100;
2、继续截取后面的7位,并在最高位补0(因为后面都是补位用的0)得到0000 0010;
3、拼接数据,得到 1010 1100 0000 0010(第一步得到的数值在高位)
zigzag编码方式
在计算机内部,一个负数采用补码的形式会被表示成一个很大的整数。计算机中针对负数采用的是补码的形式进行计算,由于会补上大量的1,并不利于压缩编码,后面会结合实际的例子解释zigzag的编码方式。
下面以-2为例,解释一下zigzag编码
-2的二进制编码(32位):1111 1111 1111 1111 1111 1111 1111 1110(补码形式)先导有很多1,无法完成压缩
1:数据位(符号位除外)取反:1000 0000 0000 0000 0000 0000 0000 0001
2:循环左移1位:0000 0000 0000 0000 0000 0000 0000 0011
最后得到的即为-2的zigzag编码。
但是在程序中不是这么做的,而是采用了巧妙的异或运算。在程序中实现如下所示(这里还是以-2为例):
1、将-2的补码左移一位(左移,末尾补0)得到:1111 1111 1111 1111 1111 1111 1111 1100
2、将-2的补码右移32位(右移,末尾补符号位)得到:1111 1111 1111 1111 1111 1111 1111 1111
3、将上述两个结果异或得到:0000 0000 0000 0000 0000 0000 0000 0011
操作非常巧妙,这就使得在程序实现过程就比较简单,下面就是实现zigzag编码的代码:
package com.learn.zigzag;
/**
*
* @author liman
* @createtime 2018年8月15日
* @contract 15528212893
* @comment:
* 实现zigzag编码
*/
public class ZigzagDemo {
public static void main(String[] args) {
Integer num = -2;
Integer result=transZigzagNum(num);
System.out.println(result);
System.out.println(Integer.toBinaryString(result));
}
/**
* 将数据转换成zigzag编码格式
* @param num
* @return
*/
public static Integer transZigzagNum(int num) {
return (num<<1)^(num>>31);
}
}
有了上面的zigzag编码方式之后,正数、负数、0都有了统一的编码格式,zigzag最大的好处就是消除了负数很多1的补位码,方便进行压缩,通过zigzag编码转换成原数据,这点在程序中也比较好实现:
/**
* 将数据由zigzag转换为原数据
* @param num
* @return
*/
public static Integer getOriginFromZiazag(int num) {
return (num>>>1)^-(num & 1);
}这个就是逆过程,只是在右移的时候,用到了无符号右移操作。
存储方式(T-L-V的存储方式)
通过zigzag完成了数据的编码,然后通过varint完成数据的压缩,接下来就是数据存储的问题了。这个时候就是基于T-L-V的方式进行存储
这里还需要详细的介绍:to be continued ......,还有一个varint的java实现
总结:
这篇文章从简单的序列化操作入手,到后面的介绍protobuf,在分布式架构中protobuf是目前用的较多的序列化框架,这是本篇文章的重点所在。
protobuf性能好主要体现在序列化后的数据体积小,并且序列化速度快,最终传输效率高。主要原因如下:
1、编码和解码方式比较简单,只需要用到位运算
2、采用protobuf自带的编译器完成序列化后的数据量体积小(数据压缩效果好)
3、采用了独特的编码方式 varint压缩,zigzag编码,并用T-L-V格式存储数据。
序列化技术的选型
其实目前谈这个问题还有点早,但是先备着,毕竟是前辈总结的经验
1、对性能要求不高的场景,可以采用XML和SOAP序列化技术
2、对性能要求比较高的场景,采用Hessian,protobuf,Thrift,Avro都可以
3、基于前后端分离的场景或者独立对外的服务,采用JSON比较好。
4、动态类型语言的场景可以采用Avro
除此之外,序列化的时长开销,性能开销,是否跨平台等,都是要考虑的,这个都是后话了。