druid+superset安装和简单使用
最近一直在折腾大数据框架,后续会把KYLIN框架也玩起来
首安装 druid 最开始是使用docker 安装方式,因为配置文件认证的KEY报错,自己编译又没有通过,直接放弃,然后直接下载安装包,ZOOKEEPER我是用docker 安装的, 没有用官方数据
首先安装环境 官方说明,我本机其实是4G内存双核 也能跑起来
Java 8 or higher
Linux, Mac OS X, or other Unix-like OS (Windows is not supported)
8G of RAM
2 vCPUs直接下载安装包
curl -O http://static.druid.io/artifacts/releases/druid-0.10.1-bin.tar.gz
tar -xzf druid-0.10.1-bin.tar.gz
cd druid-0.10.1主要目录:
LICENSE- the license files.bin/- scripts useful for this quickstart.conf/*- template configurations for a clustered setup.conf-quickstart/*- configurations for this quickstart.extensions/*- all Druid extensions.hadoop-dependencies/*- Druid Hadoop dependencies.lib/*- all included software packages for core Druid.quickstart/*- files useful for this quickstart.
Start up Zookeeper ZK安装,我本机是用docker安装的,并且是版本3.2的,仍然可用
curl http://www.gtlib.gatech.edu/pub/apache/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz -o zookeeper-3.4.6.tar.gz
tar -xzf zookeeper-3.4.6.tar.gz
cd zookeeper-3.4.6
cp conf/zoo_sample.cfg conf/zoo.cfg
./bin/zkServer.sh start初始化druid之前,必须先启动zookeeper,分布式协调者ZK
bin/init初始化后,就可以启动相关服务
java `cat conf-quickstart/druid/historical/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/historical:lib/*" io.druid.cli.Main server historical
java `cat conf-quickstart/druid/broker/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/broker:lib/*" io.druid.cli.Main server broker
java `cat conf-quickstart/druid/coordinator/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/coordinator:lib/*" io.druid.cli.Main server coordinator
java `cat conf-quickstart/druid/overlord/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/overlord:lib/*" io.druid.cli.Main server overlord
java `cat conf-quickstart/druid/middleManager/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/middleManager:lib/*" io.druid.cli.Main server middleManager每条服务启动都有日志记录,也需要相关配置文件,会为我们建立目录如log和var
如果需要重启,需要删掉var目录,然后重启bin/init
摄入数据
在druid-0.10.1目录下执行,否则就找不到数据文件
curl -X 'POST' -H 'Content-Type:application/json' -d @quickstart/wikiticker-index.json localhost:8090/druid/indexer/v1/task执行之后会返回成功的信息 像这样就OK
{"task":"index_hadoop_wikiticker_2019-04-02T07:30:01.399Z"}再执行查询数据
curl -L -H'Content-Type: application/json' -XPOST --data-binary @quickstart/wikiticker-top-pages.json http://localhost:8082/druid/v2/?pretty返回结果集如下 没有全部复制结果,知道返回这样的数据结构就一切正常
{"task":"index_hadoop_wikiticker_2017-11-18T16:07:55.681Z"}localhost:druid-0.10.-data-binary @quickstart/wikiticker-top-pages.json http://localhost:8082/druid/v2/?pretty
[ {
"timestamp" : "2015-09-12T00:46:58.771Z",
"result" : [ {
"edits" : 33,
"page" : "Wikipedia:Vandalismusmeldung"
}, {
"edits" : 28,
"page" : "User:Cyde/List of candidates for speedy deletion/Subpage"
}, {
"edits" : 27,
"page" : "Jeremy Corbyn"
}, {
"edits" : 21,
"page" : "Wikipedia:Administrators' noticeboard/Incidents"
}, {
"edits" : 20,
"page" : "Flavia Pennetta"
}, {
"edits" : 18,
"page" : "Total Drama Presents: The Ridonculous Race"
}, {
"edits" : 18,
"page" : "User talk:Dudeperson176123"
}, {
"edits" : 18,
"page" : "Wikipédia:Le Bistro/12 septembre 2015"
}, {
"edits" : 17,
"page" : "Wikipedia:In the news/Candidates"
}
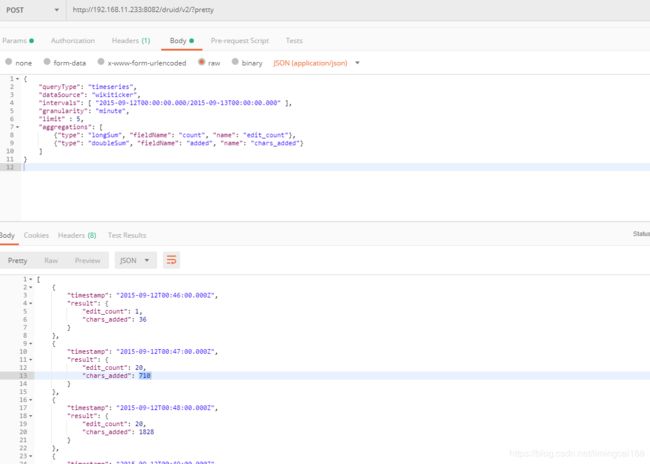
} ]下面把自己测试用的数据也贴上 从数据源” wikiticker”中进行时间序列查询
{
"queryType": "timeseries",
"dataSource": "wikiticker",
"intervals": [ "2015-09-12T00:00:00.000/2015-09-13T00:00:00.000" ],
"granularity": "minute",
"limit" : 5,
"aggregations": [
{"type": "longSum", "fieldName": "count", "name": "edit_count"},
{"type": "doubleSum", "fieldName": "added", "name": "chars_added"}
]
}
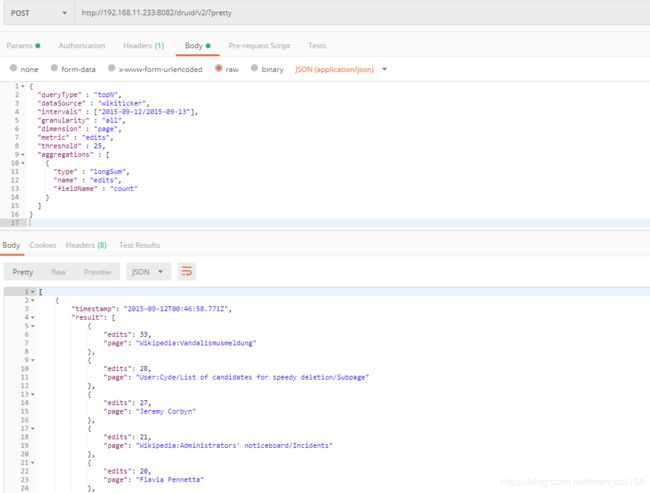
查询 topN
{
"queryType" : "topN",
"dataSource" : "wikiticker",
"intervals" : ["2015-09-12/2015-09-13"],
"granularity" : "all",
"dimension" : "page",
"metric" : "edits",
"threshold" : 25,
"aggregations" : [
{
"type" : "longSum",
"name" : "edits",
"fieldName" : "count"
}
]
}
访问可视化界面
http://192.168.11.233:8081/#/datasources/wikipedia
http://192.168.11.233:8090/console.html


界面的东西就方便了,
下面介绍一款更好的可视化界面superset,并且更容易操作,也可以出各种报表等
首先要建立一个集群,后面连接druid需要集群目录,

添加druid数据源
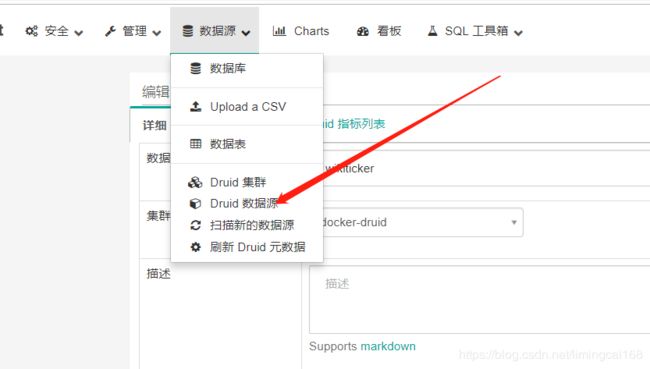
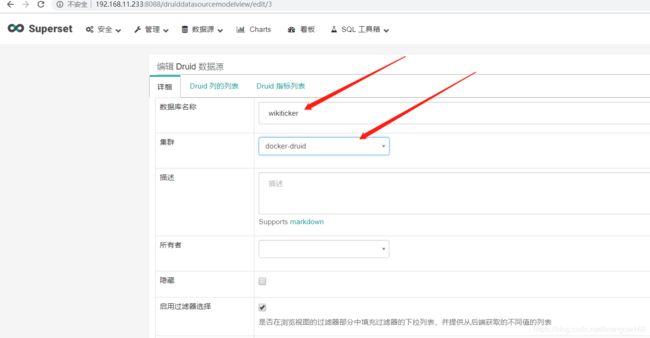
集群信息,那个可以随便命名,然后数据源里的集群名称,数据库名称就是 wikiticker

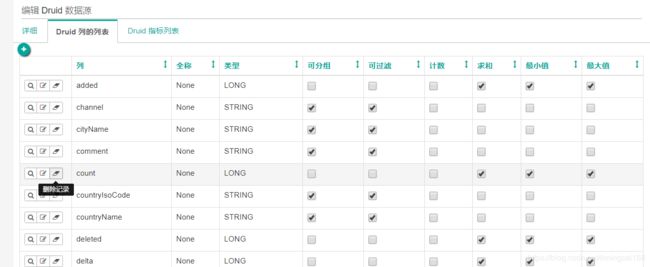
然后可以看到数据源的所有列信息
然后就选择各种图表出数据 这里要注意一下,因为历史数据,所以最近两周都是无数据,必须把条件去掉,分组信息必须给也叫指标,需要做各种聚合分组等

简单使用就是这些,查询速度非常快,后期再对数据进行处理和研究