kafka系列——KafkaProducer源码分析
实例化过程
在KafkaProducer的构造方法中,根据配置项主要完成以下对象或数据结构的实例化
① 配置项中解析出 clientId,用于跟踪程序运行情况,在有多个KafkProducer时,若没有配置 client.id则clientId 以前 辍”producer-”后加一个从 1 递增的整数

② 根据配置项创建和注册用于Kafka metrics指标收集的相关对象,用于对 Kafka 集群相关指标的追踪

③ 实例化分区器,用于为消息指定分区,客户端可以通过实现Partitioner 接口自定义消息分配分区的规则,默认使用 DefaultPartitioner(该分区器分配分区的规则是:若消息指定了Key,则对Key取hash值,然后与可用的分区总数求模; 若没有指定Key,则DefalutPartitioner通过一个随机数与可用的总分区数取模)
![]()
④ 实例化消息Key和Value进行序列化操作的Serializer,默认ByteArraySerializer(可自定义,但消费端也要指定相应的 反序列化操作) ⑤ 根据配置实例化一组拦截器(ProducerInterceptor)
![]()
⑥ 实例化用于消息发送相关元数据信息的MetaData对象,MetaData由用于控制MetaData进行更新操作的相关配置信 息与集群信息Cluster(保存集群中所有主题与分区的各种信息)组成
![]()
⑦ 实例化用于存储消息的RecordAccumulator,作用类似一个队列(后面详细介绍)
⑧ 根据指定的安全协议${security.protocol}创建一个 ChannelBuilder,然后创建NetworkClient实例,这个对象的底层是 通过维持一个Socket连接来进行TCP通信的,用于生产者与各个代理进行 Socket 通信
⑨ 由NetworkClient对象构造一个用于数据发送的Sender实例sender 线程,最后通过sender创建一个KafkaThread线 程,启动该线程,该线程是一个守护线程,在后台不断轮询,将消息发送给代理

消息发送过程介绍
首先,若客户端定义了拦截器链,则消息会经过每个拦截器的onSend方法进行处理,而后才会进入KafkaProducer的 doSend方法进行发送的处理,doSend方法处理流程如下:
① 阻塞式获取MetaData,超过${max.block.ms}时间依旧未获取到,则抛TimeoutException,消息发送失败
② 对消息的key与value进行序列化
③ 根据消息计算其将要发往的分区,若客户端发送消息时指定partitionId,则直接返回所指定的partitionId,否则根据分 区器定义的分区分配策略计算出 partitionId
④ 消息长度有效性检查,超过${max.request.size}或${buffer.memory}所设阈值,都会抛RecordTooLargeException
⑤ 创建TopicPartition对象(记录消息的topic与分区信息),在RecordAccumulator中会为每个TopicPartiton对象创建一 个双端队列(后面介绍)
⑥ 构造Callback对象,该对象最终会交由ProducerBatch处理
⑦ 写BufferPool操作,这一步是调用RecordAccumulator.append()方法将ProducerRecord写入RecordAccumulator 的BufferPool中,并返回处理结果(后面介绍)
RecordAccumulator介绍
其作用相当于一个缓冲队列,会根据主题和分区(TopicPartition对象)对消息进行分组,每一个TopicPartition对象会对应 一个双端队列Deque
![]()
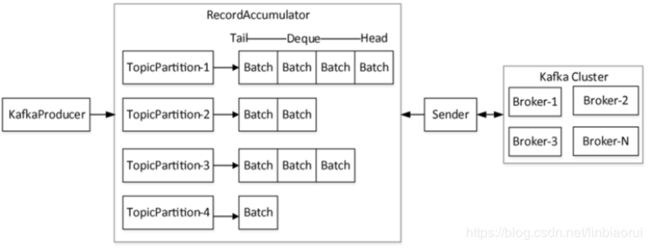
RecordAccumulator追加消息append()流程
①![]() 记录当前正在进行append消息的线程数,方便当客户端调用 KafkaProducer.close()强制关闭发送消息操作时放弃未处理完的请求,释放资源
记录当前正在进行append消息的线程数,方便当客户端调用 KafkaProducer.close()强制关闭发送消息操作时放弃未处理完的请求,释放资源
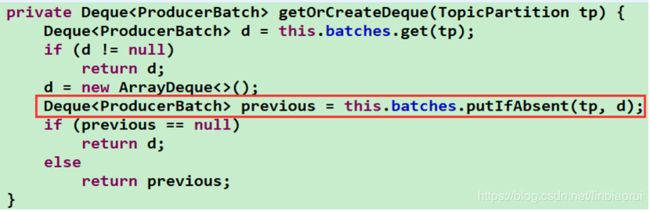
②![]() 根据TopicPartition获取or创建消息对应的双端队列 Deque
根据TopicPartition获取or创建消息对应的双端队列 Deque
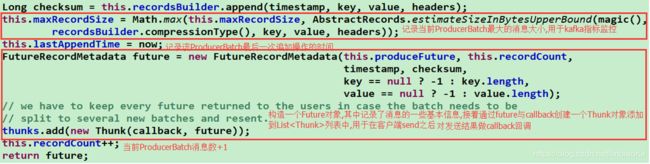
③尝试将消息写入其所属的缓冲区

④ 消息成功写入buffer后,会做如下处理
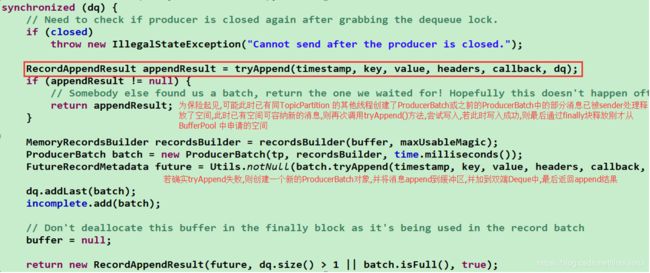
⑤ 若上述尝试append消息失败,即返回null,此时需要向BufferPool申请空间用于创建新的ProducerBatch对象,并将
![]()
消息append到新创建的ProducerBatch中,最后返回处理结果

Sender发送消息的基本流程
总体流程:从MetaData中获取集群信息→从RecordAccumulator中取出已满足发送条件的ProducerBatch→构造相关 网络层请求交由 NetworkClient 去执行
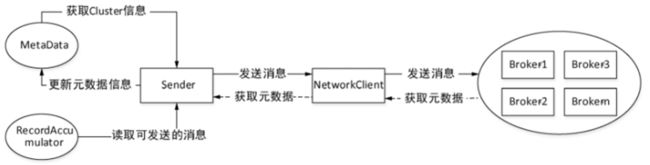
① 从MetaData中获取集群Cluster的信息![]()
② 获取各TopicPartition分区的 Leader 节点集合
![]()

③ 若第②步返回的result中的unknownLeaderTopics不为空(即存在没有找到Leader分区的主题),则遍历 unknownLeaderTopics将主题信息加入metaData中,然后调用metaData.requestUpdate()方法将needUpdate设置为 true,请求更新metaData 信息

④ 检测result中readyNodes集合各节点连接状态,若与某个节点的连接还未就绪则将该节点从readyNodes中移除,经过 NetworkClient.ready()方法处理之后,readyNodes集合中的所有节点均已与NetworkClient建立了连接

⑤ 根据readyNodes集合中的节点信息,到RecordAccumulator中取出每个topic分区对应的双端队列deque,并从每个 deque头部开始取ProducerBatch作为每个节点所要发送的消息集合
![]()
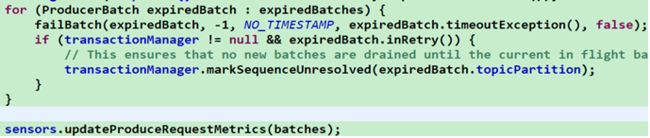
⑥ 根据配置项${request.timeout.ms}的值,默认是 30s,过滤掉请求已超时的ProducerBatch,若已超时则将该 ProducerBatch添加到过期队列List中,并将该ProducerBatch从双端队列中移除,同时释放内存空间;然后将过期的 ProducerBatch交由SenderMetrics进行处理,更新和记录相应的metrics信息
![]()
⑦ 遍历第⑤步得到的batches,根据batches分组的Node,将每 Node转化为一个ClientRequest对象,最终将 batches 转化 List
⑧ 遍历第⑦步得到的List
![]()
⑨ 在 send()方法中首先将ClinetRequest 添加到InFlightRequests 队列中,该队列记录了一系列正在被发送或是已发送 但还没收到响应的ClientRequest,然后调用Selector.send(Send send)方法,但此时数据并没有真的发送出去,只是暂存 在Selector内部相对应的KafkaChannel里面(每个Node对应一个KafkaChannel,用来记录每个Node对应的数据包,一个 KafkaChannel 一次只能存放一个数据包,在当前的数据包没有完整发出去之前不能存放下一个数据包,否则抛异常)

⑩ 在Sender的run(long now)方法的结尾调用NetworkClient.poll(long timeout,long now)方法真正进行读写操作,该方 法首先调用MetadataUpdater.maybeUpdate(long now)方法检查是否需要更新元数据信息,然后调用 Selector.poll(long timeout)方法执行真正的 I/O 操作,最后对已经完成的请求对其响应结果response 进行处理
![]()

Sender线程run()方法的控制逻辑
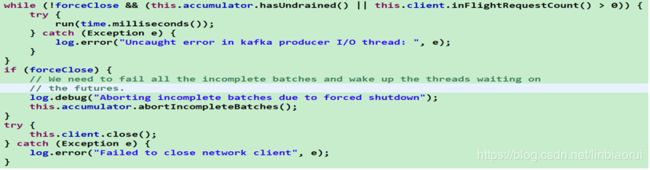
① 首先会通过标志位running来控制主循环,在running为true时一直循环调用run(long now)方法,直到KafkaProducer 调用close()方法时将runing设置为 false

② 若close操作是强制关闭,(如:在调用close()方法时设置timeout 为0,或是不正确的close()方法调用,如直接调用 KafkaProducer 实例化时创建的用于I/O操作的KafkaThread线程的close方法等,则调用RecordAcccumulator 的 abortIncompleteBatches()方法,丢弃未处理的请求,将未处理的ProducerBatch从其双端队列中移除,同时关闭 RecordBatch 释放空间;若是强制关闭,同时消息累加器尚有消息未发送(accumulator.hasUnsent())或者客户端尚有正 在处理(inFlightRequestCount()>0)的请求,则继续循环调用run(long now)方法,将RecordAccumulor中存储的未发送的 请求以及正在发送中的请求处理完毕;最后调用NetworkClinet.close()方法,关闭NetworkClinet持有的用于执行I/O 操作 的Selector及与其关联的连接通道KafkaChannel
这部分完~