如何提高文本生成任务中的文本多样性
1. 引言
在文本生成任务中,经典模型Seq2Seq虽然取得了很大的进步,但是由于其目标函数采用的是极大似然估计,即:
1 / ∣ S ∣ ∑ ( T , S ) ∈ S log p ( T ∣ S ) 1 /|\mathcal{S}| \sum_{(T, S) \in \mathcal{S}} \log p(T | S) 1/∣S∣(T,S)∈S∑logp(T∣S)其中, S S S表示给定的输入句子, T T T表示输出句子。因此,会导致一个问题,即生成的句子一般是训练集中比较高频的回复,这样的回复虽然是比较安全的,但是却会使得回复变得平淡无奇,缺乏多样性。因此,很多学者对该模型进行改进,希望可以提高文本生成的多样性,从2015年以来,提高文本多样性的方法大致可以分为四类:
- 第一类:采用新的模型对Beam Search得到的候选序列进行重排,比如MMI-bidi等。
- 第二类:引入内容的形式,对输出文本先预测一个关键词,然后对其进行补全,比如Seq2BF等。
- 第三类:直接修改Beam Search算法,对每个时间步的条件概率施加多样性惩罚,比如MMI-antiLM、diverseRL、DBS等。
- 第四类:直接修改训练时的损失函数,比如ITF-loss等
本文将对这些方法进行汇总和对比。
2. MMI-antiLM、MMI-bidi方法
为了使得生成的句子更加多样性,李纪为博士等人(2015)采用了最大互信息(Maximum Mutual Information,MMI)作为目标损失函数,在一定程度上提高了文本生成的多样性和趣味性。
论文地址:《A Diversity-Promoting Objective Function for Neural Conversation Models》
2.1 MMI-antiLM、MMI-bidi损失函数
在文本生成任务中,令 S S S表示给定的输入句子 S = { s 1 , s 2 , … , s N s } S=\left\{s_{1}, s_{2}, \dots, s_{N_{s}}\right\} S={s1,s2,…,sNs},其中, N s N_{s} Ns表示输入句子的词汇数量,即句子的长度,令 T T T表示输出句子 T = { t 1 , t 2 , … , t N t , E O S } T=\left\{t_{1}, t_{2}, \ldots, t_{N_{t}}, E O S\right\} T={t1,t2,…,tNt,EOS}, N t N_{t} Nt表示输出句子的词汇数量,即句子的长度,则MMI目标损失函数可以表示为:
log p ( S , T ) p ( S ) p ( T ) \log \frac{p(S, T)}{p(S) p(T)} logp(S)p(T)p(S,T)这样一来,损失函数不仅仅考虑了输入句子,还考虑输出句子的出现频率,因此,不会偏袒于那些高频率的回复。该损失函数可以进一步表达为:
T ^ = arg max T { log p ( T ∣ S ) − log p ( T ) } \hat{T}=\underset{T}{\arg \max }\{\log p(T | S)-\log p(T)\} T^=Targmax{logp(T∣S)−logp(T)}可以发现,其实MMI损失函数可以看成是在极大似然估计的基础上,添加了一项对输出句子概率的惩罚项,用更通用的形式可以表达为:
T ^ = arg max T { log p ( T ∣ S ) − λ log p ( T ) } \hat{T}=\underset{T}{\arg \max }\{\log p(T | S)-\lambda \log p(T)\} T^=Targmax{logp(T∣S)−λlogp(T)}其中, λ \lambda λ为惩罚参数,表示高频率回复的惩罚。作者将这种目标函数记为MMI-antiLM。根据贝叶斯公式,有:
log p ( T ) = log p ( T ∣ S ) + log p ( S ) − log p ( S ∣ T ) \log p(T)=\log p(T | S)+\log p(S)-\log p(S | T) logp(T)=logp(T∣S)+logp(S)−logp(S∣T)将该式代入目标函数有:
T ^ = arg max T { ( 1 − λ ) log p ( T ∣ S ) + λ log p ( S ∣ T ) − λ log p ( S ) } = arg max T { ( 1 − λ ) log p ( T ∣ S ) + λ log p ( S ∣ T ) } \begin{aligned} \hat{T} &=\arg \max _{T}\{(1-\lambda) \log p(T | S) +\lambda \log p(S | T)-\lambda \log p(S) \} \\ &=\arg \max _{T}\{(1-\lambda) \log p(T | S)+\lambda \log p(S | T)\} \end{aligned} T^=argTmax{(1−λ)logp(T∣S)+λlogp(S∣T)−λlogp(S)}=argTmax{(1−λ)logp(T∣S)+λlogp(S∣T)}作者将这种目标函数记为MMI-bidi。
2.2 如何使用
在真实的训练过程中,如果直接将MMI-antiLM和MMI-bidi两种损失函数作为训练时的损失函数,那么训练将会非常艰难,会导致语法紊乱和解码难的问题,因此,作者在真实训练过程中,还是采用极大似然估计作为模型训练的损失函数,但是在预测时才采用MMI损失函数。
对于MMI-antiLM损失函数,我们知道,当 λ \lambda λ比较大时,此时损失函数会减弱第一项的权重,导致生成的句子会出现一些语法上的错误,特别是当句子比较长时,当 λ \lambda λ设置比较小时,作者发现该问题还是会出现。我们知道,对于decoder,每一个词的输出都依赖于前面词汇的输出和encoder得到的语义向量,但是,随着句子长度的增长,encoder的语义向量对后面词语的影响会慢慢减弱,因此,输出句子的通顺程度到了后面主要还是依赖于语言模型而不是输入句子,那么,对于后面词语的生成,其实可以不采用多样性惩罚,因此,对于MMI-antiLM损失函数中的 p ( T ) p(T) p(T)项,作者在实际使用时进行了如下改进:
U ( T ) = ∏ k = 1 N t p ( t k ∣ t 1 , t 2 , … , t k − 1 ) ⋅ g ( k ) U(T)=\prod_{k=1}^{N_{t}} p\left(t_{k} | t_{1}, t_{2}, \ldots, t_{k-1}\right) \cdot g(k) U(T)=k=1∏Ntp(tk∣t1,t2,…,tk−1)⋅g(k)其中, g ( k ) g(k) g(k)表示对输出句子每一个词语的权重,其计算公式如下:
g ( k ) = { 1 if k ≤ γ 0 if k > γ g(k)=\left\{\begin{array}{ll}{1} & {\text { if } k \leq \gamma} \\ {0} & {\text { if } k>\gamma}\end{array}\right. g(k)={10 if k≤γ if k>γ其中, γ \gamma γ为一个阈值参数,表示当长度大于该值后,则将对应的 p ( T ) p(T) p(T)项置为0,也就是说对生成句子后面的词语不施加多样性惩罚,多样性只取决于前面几个词汇。这样一来,MMI-antiLM的损失函数可以改写为:
log p ( T ∣ S ) − λ log U ( T ) \log p(T | S)-\lambda \log U(T) logp(T∣S)−λlogU(T)
另外,作者在真实应用时,还加入句子长度作为另一项正则项,即:
S c o r e ( T ) = p ( T ∣ S ) − λ U ( T ) + γ N t Score(T)=p(T | S)-\lambda U(T)+\gamma N_{t} Score(T)=p(T∣S)−λU(T)+γNt其中, γ \gamma γ表示惩罚参数。
对于MMI-bidi损失函数,我们知道其实就是 log p ( T ∣ S ) \log p(T | S) logp(T∣S)和 log p ( S ∣ T ) \log p(S |T) logp(S∣T)两项之间的加权平均,因为在推理时,作者在训练时,分成两个Seq2Seq模型进行训练,即先训练一个输入句子 S S S到输出句子 T T T的Seq2Seq模型,记为 m o d e l 1 model_1 model1,然后训练一个输出句子 T T T到输入句子 S S S的Seq2Seq模型,记为 m o d e l 2 model_2 model2。接着,对于一个输入句子 S S S,会使用 m o d e l 1 model_1 model1通过Beam_search先生成 N b e s t N_{best} Nbest个候选的句子,然后利用 m o d e l 2 model_2 model2计算每个候选句子的 log p ( S ∣ T ) \log p(S |T) logp(S∣T),最后根据计算结果对200个候选句子进行重排,从而提高输出句子的多样性。
3. Seq2BF方法
2016年,北大Lili Mou等人提出了一种新的方法,即Seq2BF模型,该模型的基本思想是在decoder之前,先根据点态互信息(Pointwise Mutual Information,PMI)计算出一个与输入句子最相关的名词,作为输出句子的关键词,然后采用两个Seq2Seq模型分别对该词的前文和后文进行decode补全,最后作为预测的输出句子。
论文地址:《Sequence to Backward and Forward Sequences: A Content-Introducing Approach to Generative Short-Text Conversation》
3.1 关键词预测
在关键词预测这一步,作者采用了PMI作为计算指标,记输入句子中的每一个词汇为 w q w_{q} wq,输出句子中的每一个词汇为 w r w_{r} wr,则PMI的计算公式如下:
PMI ( w q , w r ) = log p ( w q , w r ) p ( w q ) p ( w r ) = log p ( w q ∣ w r ) p ( w q ) \operatorname{PMI}\left(w_{q}, w_{r}\right)=\log \frac{p\left(w_{q}, w_{r}\right)}{p\left(w_{q}\right) p\left(w_{r}\right)}=\log \frac{p\left(w_{q} | w_{r}\right)}{p\left(w_{q}\right)} PMI(wq,wr)=logp(wq)p(wr)p(wq,wr)=logp(wq)p(wq∣wr)在预测时,对于一个输入句子 w q 1 , ⋯ w q n w_{q_{1}}, \cdots w_{q_{n}} wq1,⋯wqn,计算输出句子词汇列表中每个词汇与输入句子的PMI分数,然后从中选择分数最高的词汇作为预测的关键词 w r ∗ = argmax w r PMI ( w q 1 ⋯ w q n , w r ) w_{r}^{*}=\operatorname{argmax}_{w_{r}} \operatorname{PMI}\left(w_{q_{1}} \cdots w_{q_{n}}, w_{r}\right) wr∗=argmaxwrPMI(wq1⋯wqn,wr),一般会限制该关键词为名词,具体的计算公式如下:
PMI ( w q 1 … w q n , w r ) = log p ( w q 1 ⋯ w q n ∣ w r ) p ( w q 1 ⋯ w q n ) ≈ log ∏ i = 1 n p ( w q i ∣ w r ) ∏ i = 1 n p ( w q i ) = ∑ i = 1 n log p ( w q i ∣ w r ) p ( w q i ) = ∑ i = 1 n PMI ( w q i , w r ) \operatorname{PMI}\left(w_{q_{1}} \ldots w_{q_{n}}, w_{r}\right)=\log \frac{p\left(w_{q_{1}} \cdots w_{q_{n}} | w_{r}\right)}{p\left(w_{q_{1}} \cdots w_{q_{n}}\right)} \\ \approx \log \frac{\prod_{i=1}^{n} p\left(w_{q_{i}} | w_{r}\right)}{\prod_{i=1}^{n} p\left(w_{q_{i}}\right)}=\sum_{i=1}^{n} \log \frac{p\left(w_{q_{i}} | w_{r}\right)}{p\left(w_{q_{i}}\right)}=\sum_{i=1}^{n} \operatorname{PMI}\left(w_{q_{i}}, w_{r}\right) PMI(wq1…wqn,wr)=logp(wq1⋯wqn)p(wq1⋯wqn∣wr)≈log∏i=1np(wqi)∏i=1np(wqi∣wr)=i=1∑nlogp(wqi)p(wqi∣wr)=i=1∑nPMI(wqi,wr)该近似计算假设 p ( w q i ) p\left(w_{q_{i}}\right) p(wqi)和 p ( w q i ∣ w r ) p\left(w_{q_{i}} | w_{r}\right) p(wqi∣wr)都是独立的。
3.2 Seq2BF模型
当关键词预测出来后,因为要将关键词包含在输出句子中,此时没法直接使用Seq2Seq模型,因此,作者在Seq2Seq模型的基础上进行了稍微修改,提出了Seq2BF模型。对于给定的输入句子 q = q 1 q 2 ⋯ q n \boldsymbol{q}=q_{1} q_{2} \cdots q_{n} q=q1q2⋯qn和输出句子 r = r 1 r 2 ⋯ r m \boldsymbol{r}=r_{1} r_{2} \cdots r_{m} r=r1r2⋯rm,我们知道传统的Seq2Seq模型是最大化如下的条件概率:
p ( r 1 , ⋯ , r m ∣ q ) = p ( r 1 ∣ q ) p ( r 2 ∣ r 1 , q ) ⋯ p ( r m ∣ r 1 ⋯ r m − 1 , q ) = ∏ i = 1 m p ( r i ∣ r 1 ⋯ r i − 1 , q ) p\left(r_{1}, \cdots, r_{m} | q\right)=p\left(r_{1} | q\right) p\left(r_{2} | r_{1}, q\right) \cdots p\left(r_{m} | r_{1} \cdots r_{m-1}, q\right)=\prod_{i=1}^{m} p\left(r_{i} | r_{1} \cdots r_{i-1}, q\right) p(r1,⋯,rm∣q)=p(r1∣q)p(r2∣r1,q)⋯p(rm∣r1⋯rm−1,q)=i=1∏mp(ri∣r1⋯ri−1,q)假设输出句子的关键词为 r k r_k rk,则此时输出句子可以被分解为前后两个子句子,即:
Backward sequence: r r − 1 , ⋯ , r 1 Forward sequence: r k + 1 , ⋯ , r m \begin{array}{ll}{\text { Backward sequence: }} & {r_{r-1}, \cdots, r_{1}} \\ {\text { Forward sequence: }} & {r_{k+1}, \cdots, r_{m}}\end{array} Backward sequence: Forward sequence: rr−1,⋯,r1rk+1,⋯,rm这样一来,原先的条件概率可以转化为:
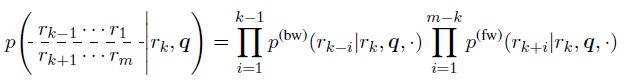
在具体的建模过程中,作者提出了三种模式的Seq2BF模型:①sep-B/F(分离Seq2BF):即对于前向和后向两个子句子分别采用两个生成器进行生成;②syn-B/F(同步Seq2BF):对于前向和后向两个子句子采用一个单层的RNN同时进行decode,但是采用不同的输出层进行输出。③asyn-B/F(异步Seq2BF):先采用一个解码器对后向句子进行解码,然后解码后将句子进行反向排序并与关键词拼接,然后作为另一个解码器的前缀输入,一直解码直到句子结束。作者在实验中发现采用第三种类型的Seq2BF模型效果最好,该模型的整体结构如下图所示:
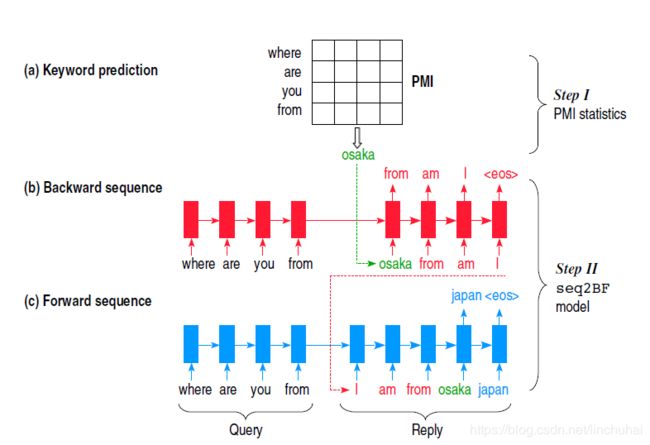
需要注意的是,在训练阶段,关键词的选择采用的是随机选取的方法,而在预测阶段,则采用PMI分数最高的词汇作为关键词。
4. diverseRL方法
2016年,李纪为博士在15年那篇的基础上又进行了改进,这次,他直接对Beam_search方法进行修改,使得Beam_search的搜索结果多样性更强,并且其通用性更强,可以迁移到很多其他的任务上。在参数的选择方面,引进了强化学习的思想,使得该方法更加灵活。
论文地址:《A Simple, Fast Diverse Decoding Algorithm for Neural Generation》
4.1 Diverse Beam_search
对于一个输入句子 X X X和输出句子 Y Y Y,传统的Beam_search方法会根据 p ( Y ∣ X ) p(Y | X) p(Y∣X)选择 K K K个最优的候选生成句子,其中, K K K为beam_size的取值。其思想如下:在时间步 t − 1 t-1 t−1,编码器会保存当前 K K K个最优的已解码序列 Y t − 1 k = { y 1 k , y 2 k , … , y t − 1 k } , k ∈ [ 1 , K ] Y_{t-1}^{k}=\left\{y_{1}^{k}, y_{2}^{k}, \ldots, y_{t-1}^{k}\right\}, k \in[1, K] Yt−1k={y1k,y2k,…,yt−1k},k∈[1,K]以及他们的概率 S ( Y t − 1 ∣ X ) = log p ( y 1 , y 2 , … , y t − 1 ∣ X ) S\left(Y_{t-1} | X\right)=\log p\left(y_{1}, y_{2}, \dots, y_{t-1} | X\right) S(Yt−1∣X)=logp(y1,y2,…,yt−1∣X),然后在第 t t t个时间步时,Beam_search会对每个已解码序列进一步解码其后面的第 t t t个词汇,对每个序列同样选择 K K K个候选的词汇 y t k , k ′ , k ′ ∈ [ 1 , K ] y_{t}^{k, k^{\prime}}, k^{\prime} \in[1, K] ytk,k′,k′∈[1,K],这样一来,总共会产生 K × K K \times K K×K个新的候选序列:
[ Y t − 1 k , y t k , k ′ ] , k ∈ [ 1 , K ] , k ′ ∈ [ 1 , K ] \left[Y_{t-1}^{k}, y_{t}^{k, k^{\prime}}\right], k \in[1, K], k^{\prime} \in[1, K] [Yt−1k,ytk,k′],k∈[1,K],k′∈[1,K]他们的概率计算如下:
S ( Y t − 1 k , y t k , k ′ ∣ x ) = S ( Y t − 1 k ∣ x ) + log p ( y t k , k ′ ∣ x , Y t − 1 k ) S\left(Y_{t-1}^{k}, y_{t}^{k, k^{\prime}} | x\right)=S\left(Y_{t-1}^{k} | x\right)+\log p\left(y_{t}^{k, k^{\prime}} | x, Y_{t-1}^{k}\right) S(Yt−1k,ytk,k′∣x)=S(Yt−1k∣x)+logp(ytk,k′∣x,Yt−1k)然后根据这 K × K K \times K K×K候选序列的概率大小,从中选择 K K K个概率最大的候选序列作为当前时间步的候选序列,然后重复该过程一直到解码结束。具体的如下图所示:
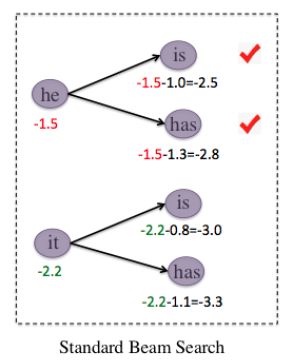
可以发现,虽然Beam_search在每个时间步都会选择 K K K个候选序列,但是每一步都会受到上一步的影响,当 K K K个父节点的概率相差比较大时,随着句子长度的增加,后续的 K K K个后续序列往往会集中到个别父节点上,如上图最开始的候选序列是‘he’和‘it’,但是到了第二步后,此时概率最大的两条候选序列都集中在’he’节点,从而导致最终出来的 K K K个候选序列都是比较相似的。因此,Diverse Beam_search对概率公式进行了简单的修正,在后面添加了一项惩罚项,即:
S ^ ( Y t − 1 k , y t k , k ′ ∣ x ) = S ( Y t − 1 k , y t k , k ′ ∣ x ) − γ k ′ \hat{S}\left(Y_{t-1}^{k}, y_{t}^{k, k^{\prime}} | x\right)=S\left(Y_{t-1}^{k}, y_{t}^{k, k^{\prime}} | x\right)-\gamma k^{\prime} S^(Yt−1k,ytk,k′∣x)=S(Yt−1k,ytk,k′∣x)−γk′其中, k ′ k^{\prime} k′为每个候选序列在同一个父节点下的排序, γ \gamma γ为超参数,称为Diversity rate。具体如下图所示:

这样一来,每一条候选序列都会受到内部排序的影响,因此那些在每个父节点排名靠前的序列会更容易进入到最终的候选序列,从而使得生成的候选序列更加多样性。
4.2 Diversity rate的选择
由于Diverse Beam_search引入了一个超参数 γ \gamma γ,对于不同的输入文本,该值应该是能够自动调整而不是固定为一个设定的值,因此,作者引入了强化学习的思想,当生成器训练好之后,会将模型的参数固定,然后设定一个 γ \gamma γ的候选集合 Γ \Gamma Γ,并将每种选择进行参数化 h γ ′ h_{\gamma^{\prime}} hγ′,接着,对于每一个输入 X X X,会通过encoder将其转化为一个向量表示 h X h_X hX,然后通过softmax计算当前输入在各个候选 γ \gamma γ值上的概率分布:
π ( γ ( X ) = γ ′ ∣ X ) = exp ( h X T ⋅ h γ ′ ) ∑ j = 1 j = ∣ Γ ∣ exp ( h X T ⋅ h Γ j ) \pi\left(\gamma(X)=\gamma^{\prime} | X\right)=\frac{\exp \left(h_{X}^{T} \cdot h_{\gamma^{\prime}}\right)}{\sum_{j=1}^{j=|\Gamma|} \exp \left(h_{X}^{T} \cdot h_{\Gamma_{j}}\right)} π(γ(X)=γ′∣X)=∑j=1j=∣Γ∣exp(hXT⋅hΓj)exp(hXT⋅hγ′)选择其中概率最大的 γ \gamma γ作为当前输入的 γ \gamma γ,然后采用Diverse Beam_search选择出最好的输出文本,最后,在整个验证集上计算每个输出文本的Bleu值作为奖励函数,记为 R ( γ ( X ) = γ ′ ) R\left(\gamma(X)=\gamma^{\prime}\right) R(γ(X)=γ′),然后寻求一种最优的策略,使得最终的期望奖励值最大化:
E π ( γ ( X ) = γ ′ ∣ X ) [ R ( γ ( X ) = γ ′ ) ) ] E_{\pi\left(\gamma(X)=\gamma^{\prime} | X\right)}\left[R\left(\gamma(X)=\gamma^{\prime}\right)\right) ] Eπ(γ(X)=γ′∣X)[R(γ(X)=γ′))]从而对参数进行更新:
∇ E ( θ ) = [ R ( γ ( X ) − b ] ∇ log π ( γ ( X ) = γ ′ ∣ X ) \nabla E(\theta)=\left[R(\gamma(X)-b] \nabla \log \pi\left(\gamma(X)=\gamma^{\prime} | X\right)\right. ∇E(θ)=[R(γ(X)−b]∇logπ(γ(X)=γ′∣X)
5. Diverse Beam Search方法
&ebsp;2018年,Ashwin K Vijayakumar等人也提出了一种新的Diverse Beam Search,简称DBS,该方法的大致思想是:将原先的Beam Search均分为 G G G个组,每个组含有 B ′ = B / G B^{\prime}=B / G B′=B/G条候选路径,对每个组还是按照Beam Search的思想进行解码,但是每个组在解码时还要考虑解码后的序列与前面每个组已经解码的序列之间的差异性。作者将该方法与李纪为博士的diverseRL方法、传统的Beam Search方法进行对比,发现在多个任务上都有效提升了文本生成的多样性。
论文地址:《DIVERSE BEAM SEARCH: DECODING DIVERSE SOLUTIONS FROM NEURAL SEQUENCE MODELS》
5.1 DBS原理介绍
在decoder时,每一步的输出概率都取决于其输入 x x x和前面的输出序列 y t − 1 , … , y 1 y_{t-1}, \dots, y_{1} yt−1,…,y1,记在第 t t t个时间步的对数概率为: θ ( y t ) = log Pr ( y t ∣ y t − 1 , … , y 1 , x ) \theta\left(y_{t}\right)=\log \operatorname{Pr}\left(y_{t} | y_{t-1}, \ldots, y_{1}, \mathbf{x}\right) θ(yt)=logPr(yt∣yt−1,…,y1,x),为了简化计算,将每一步的对数概率 θ ( ⋅ ) \theta(\cdot) θ(⋅)记为 y t y_t yt。由前面我们知道,Beam Search在每次解码时,都会从所有解码序列中选择概率最大的前 B B B条候选序列作为最终的输出序列,但是因为Beam Search的搜索方式很容易导致最终生成的 B B B条序列都集中在某几个父节点,从而导致最终的 B B B条输出序列有大部分都是非常接近的。因此,为了克服这个问题,DBS在每次解码时,在原先的概率公式上添加了一项差异项 Δ ( Y [ t ] ) \Delta\left(Y_{[t]}\right) Δ(Y[t]),用来衡量后续序列之间的多样性或差异性。如果直接在Beam Search的基础上对每个序列计算两两之间的多样性,那么,该计算的复杂度将是 ∣ V ∣ B |\mathcal{V}|^{B} ∣V∣B,其中 ∣ V ∣ |\mathcal{V}| ∣V∣表示decoder的词汇数量,这在实际中将是不可行的。因此,DBS将原先的Beam Search的 B B B个候选序列分为了 G G G个组,然后依次对每个组采用Beam Search进行解码,对每个组进行解码时,都要确保前面的组固定不变,然后将当前组与前面的组计算多样性,因为此时计算序列的多样性只考虑当前组与前面组已经解码好的后续序列,因此,计算的复杂度大大降低,该形式也因此被称为双贪婪(doubly greedy)的形式。
记 Y [ t ] Y_{[t]} Y[t]表示Beam Search在 t t t时刻的 B B B个候选序列,将其分为 G G G个组 Y [ t ] g , g ∈ [ G ] Y_{[t]}^{g}, g \in[G] Y[t]g,g∈[G],此时,每个组就相当于Beam size为 B ′ = B / G B^{\prime}=B / G B′=B/G。DBS对每一组进行解码时,会在原先概率公式的基础上添加一项差异项 Δ ( y [ t ] , Y [ t ] g ) \Delta\left(\mathrm{y}_{[t]}, Y_{[t]}^{g}\right) Δ(y[t],Y[t]g),表示当前序列与第 g g g组的候选序列的差异性,其计算公式如下:
Δ ( y [ t ] , Y [ t ] g ) = ∑ b = 1 B ′ δ ( y [ t ] , y b , [ t ] g ) \Delta\left(\mathrm{y}_{[t]}, Y_{[t]}^{g}\right)=\sum_{b=1}^{B^{\prime}} \delta\left(\mathrm{y}_{[t]}, \mathrm{y}_{b,[t]}^{g}\right) Δ(y[t],Y[t]g)=b=1∑B′δ(y[t],yb,[t]g)其中, δ ( ⋅ , ⋅ ) \delta(\cdot, \cdot) δ(⋅,⋅)表示序列差异性的度量,其计算方式有多种,一会再讲。因此,每一组在每个时间步挑选出来的 B ′ B^{\prime} B′个候选序列可以表示为:
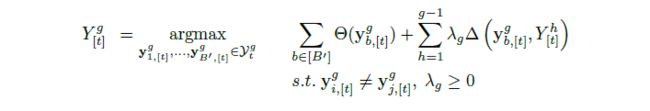
该方法即为DBS方法。具体的算法过程如下:


5.2 相关参数设置
通过前面的介绍我们知道,DBS引入了一些超参数的设置,比如组数 G G G、惩罚参数 λ \lambda λ、差异性度量函数 δ ( ⋅ , ⋅ ) \delta(\cdot, \cdot) δ(⋅,⋅)。作者在实验过程中,对这几个参数也分别进行了调优,并发现:
- 随着组数 G G G的增加,DBS的精度会不会提高,将组数 G G G设置为 B B B,即 G = B G=B G=B效果是最好的。
- λ \lambda λ不宜过高或过低,一般设置在0.2~0.8效果比较好。
- 对于差异项度量函数 δ ( ⋅ , ⋅ ) \delta(\cdot, \cdot) δ(⋅,⋅),作者对比了Hamming diversity、Cummulative diversity、n-gram diversity和Neural-embedding diversity四种计算方式,发现采用Hamming diversity效果相对比较好,该方法直接度量每个句子与其他组句子词汇使用的差异性。
6. ITF-loss方法
前面介绍的方法中,其实都是在模型训练结束后,对decoder方式进行改动而成的,而Ryo Nakamura等人在2018年提出的ITF-loss则直接改动训练时的MLE损失函数,该方法非常简单,不需要额外地训练其他模型,很容易迁移到各种模型当中。
论文地址:《Another Diversity-Promoting Objective Function for Neural Dialogue Generation》
6.1 ITF-loss原理介绍
在传统的Seq2Seq中,我们一般会采用Softmax Cross Entropy(后文简记为SCE)作为损失值的计算函数,其表达式如下:
L s c e = − log ( exp ( x c ) ∑ k = 1 ∣ V ∣ exp ( x k ) ) L_{\mathrm{sce}}=-\log \left(\frac{\exp \left(x_{c}\right)}{\sum_{k=1}^{|V|} \exp \left(x_{k}\right)}\right) Lsce=−log(∑k=1∣V∣exp(xk)exp(xc))其中, x k x_{k} xk表示第 k k k个单词的输出值, x c x_{c} xc表示真实值的输出值, ∣ V ∣ |V| ∣V∣表示输出词汇的数量。ITF-loss在训练时,对SCE损失函数施加了一个权重,其计算方式如下:
L I T F = w c L s c e w c = 1 f r e q ( token c ) λ \begin{aligned} L_{\mathrm{ITF}} &=w_{c} L_{\mathrm{sce}} \\ w_{c} &=\frac{1}{\mathrm{freq}\left(\text { token }_{c}\right)^{\lambda}} \end{aligned} LITFwc=wcLsce=freq( token c)λ1其中, w c w_{c} wc表示真实值对应的权重,与该真实值的词频刚好成反比,这样一来,对于那些高频的词汇,会使得他们的损失值越小,而对于低频的词汇,则会使得他们的损失值越大,从而使得模型更关注那些低频的词汇的损失,其实该方法与focal loss非常类似。
6.2 推理阶段的ITF-loss
在推理阶段,同样可以对每一步的输出施加一个权重,其计算方式如下:
y = argmax { log softmax ( w ⊙ x ) } y=\operatorname{argmax}\{\log \operatorname{softmax}(w \odot x)\} y=argmax{logsoftmax(w⊙x)}其中, w w w的计算方式与训练时权重的计算方式一样。但是作者在实验中发现,采用这样的ITF-loss进行推理时,会出现一些句子重复的情况,因此,在推理时,对权重的计算进行了如下修改:
s u p p r e s s o r ( x k ) = 1 { 1 + count ( token k ) } λ x k suppressor\left(x_{k}\right)=\frac{1}{\left\{1+\text { count }\left(\text { token }_{k}\right)\right\}^{\lambda}} x_{k} suppressor(xk)={1+ count ( token k)}λ1xk其中, count ( token k ) \text { count }(\text { token }_{k}) count ( token k)表示词汇 token k \text { token }_{k} token k在当前的已解码出的序列中出现的次数。这样有效抑制了重复句子的出现。
7. 总结
最后做一下总结吧:
- MMI两种损失函数与传统的极大似然估计相比的话,可以提高文本生成的多样性和趣味性。
- MMI-antiLM不需要额外训练一个模型,使用起来会方便一点。
- MMI-bidi需要训练两个模型,训练时间翻了一倍,另外,对于最终输出句子的重排,其实还是受到Seq2Seq生成的候选句子的限制,如果生成的候选句子多样性差,那么就算重排之后,其实也不一定能提高多样性。
- Seq2BF虽然通过预测关键词来提高文本生成的多样性,但是因为其关键词都限定为名词,而我们知道,有些回复其实是不包含名词的,此时如果强制要求回复必须包含预测的名词,那可能会出现错误。
参考文献
- A Diversity-Promoting Objective Function for Neural Conversation Models.
- Sequence to Backward and Forward Sequences: A Content-Introducing Approach to Generative Short-Text Conversation.
- A Simple, Fast Diverse Decoding Algorithm for Neural Generation.
- DIVERSE BEAM SEARCH: DECODING DIVERSE SOLUTIONS FROM NEURAL SEQUENCE MODELS.
- Another Diversity-Promoting Objective Function for Neural Dialogue Generation.