Transformer文本生成与tensorflow实现
1. 引言
前面介绍了文本生成任务中的经典模型——Seq2Seq,以及一些常见的attention机制,虽然在文本生成任务中取得了相当出色的成绩,但是随着数据量的增大和语料长度的增大,RNN固有的序贯性严重阻碍了训练的速度,因此,本文将介绍另一个经典的模型——Transformer,该模型是由谷歌在2017年提出来的模型,模型完全摒弃了RNN和CNN的结构,只采用了attention的机制,在训练速度和生成效果都得到了不错的提升。
- 论文地址:《Attention is all you need》
2. Transformer原理介绍
在大多数的文本生成模型中,都采用encoder-decoder的结构,encoder将输入序列 ( x 1 , … , x n ) \left(x_{1}, \dots, x_{n}\right) (x1,…,xn)转化为一个上下文向量 Z = ( z 1 , … , z n ) \mathbf{Z}=\left(z_{1}, \dots, z_{n}\right) Z=(z1,…,zn),然后将上下文向量传递给decoder,decoder生成输出序列 ( y 1 , … , y m ) \left(y_{1}, \dots, y_{m}\right) (y1,…,ym)。Transformer模型也是采用encoder-decoder的结构,只不过在encoder和decoder中不再采用RNN或者CNN,而是采用堆叠的self-attention和point-wise的形式。
2.1 Transformer模型结构
Transformer模型的encoder采用的是堆叠6层的形式,每一层由两个子层组成,第一个子层是一层multi-head self-attention层,第二个子层是一层Position-wise Feed-Forward Networks,其中,每个子层都带有残差连接和layer normalization,即每个子层的最终输出为:
LayerNorm ( x + Sublayer ( x ) ) \text{LayerNorm}(x+\text{Sublayer}(x)) LayerNorm(x+Sublayer(x))其中, Sublayer ( x ) \text{Sublayer}(x) Sublayer(x)表示每个子层的输出。
Transformer模型的decoder也是采用堆叠6层的形式,每一层的结构与encoder类似,只是每一层多了一层multi-head attention,用来融合encoder的输出,并且每一层的第一层multi-head attention添加了mask机制,即在每一步解码时,会将后面的序列遮挡住,这样才可以防止模型作弊。具体的模型结构如下图所示:
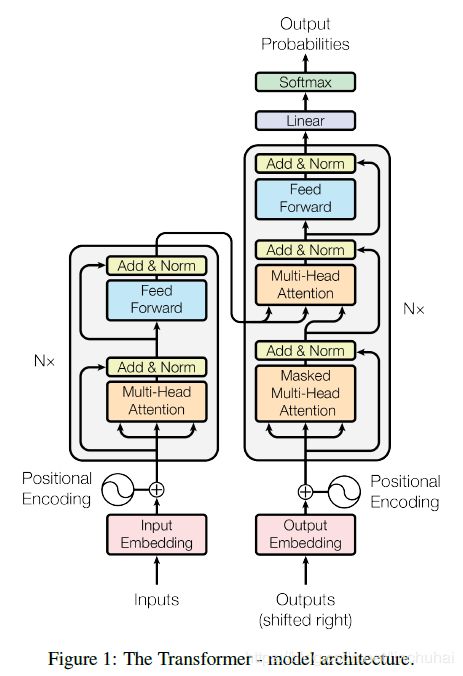
2.2 Transformer模型的attention机制
在上一节我们知道,Transformer模型的注意力机制主要是在multi-head attention这一子层,在介绍这一层的结构之前,先介绍一下scaled dot-product attention结构,对于attention机制,其实可以看做是从一个query向量映射到一个key向量,然后将keys向量对应的values向量作为输出的过程。在scaled dot-product attention结构中,有三个输入矩阵,分别是 Q 、 K 、 V Q、K、V Q、K、V,分别对应query、keys和values,其中, Q 、 K Q、K Q、K的维度大小都是 d k d_k dk, V V V的维度大小是 d v d_v dv。在该结构中,首先 Q 、 K Q、K Q、K会进行点积,然后将点积后的矩阵进行scale,即除以 d k \sqrt{d_{k}} dk,然后经过一层softmax层得到权重矩阵,再与 V V V进行点积得到最终的输出,具体的计算公式如下:
( Q , K , V ) = softmax ( Q K T d k ) V (Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V (Q,K,V)=softmax(dkQKT)V之所以要进行scale,是因为 Q 、 K Q、K Q、K进行点积后,往往会使得值比较大,此时传入softmax层后,可能会使得权重分布过于极端,会导致梯度非常小,因此,为了避免这个问题,对点积后的矩阵统一除以 d k \sqrt{d_{k}} dk。具体如下图所示:
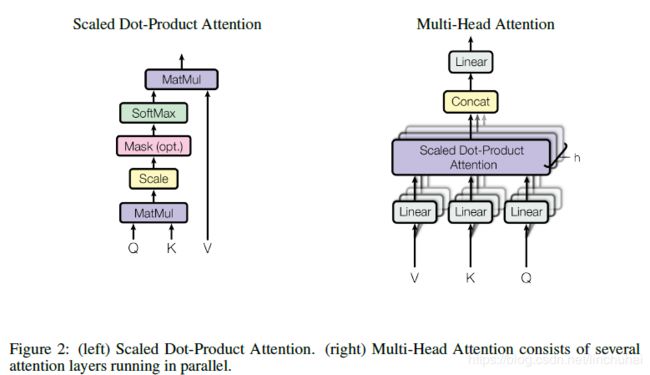
multi-head attention子层的结构如上图所示,对于原始输入,作者会将输入 Q 、 K 、 V Q、K、V Q、K、V先进行 h h h次线性变换,每次线性变换会将输入分别转化为三个维度更小的 Q 、 K 、 V Q、K、V Q、K、V矩阵,每个矩阵的维度 d k = d v = d model / h d_{k}=d_{v}=d_{\text { model }} / h dk=dv=d model /h,其中 d model d_{\text { model }} d model 为原始输入的维度,然后将变换后的 Q 、 K 、 V Q、K、V Q、K、V传入我们上面介绍的scaled dot-product attention,最后再将 h h h个输出进行拼接,然后经过一层线性变换后重新将维度转化为 d model d_{\text { model }} d model 。具体的计算公式如下:
MultiHead ( Q , K , V ) = Concat ( h e a d 1 , … , head h ) W O \text{MultiHead}(Q, K, V)=\text { Concat} (head _{1}, \ldots, \text { head }_{h} ) W^{O} MultiHead(Q,K,V)= Concat(head1,…, head h)WO其中, head i = \text{head}_{\mathrm{i}}= headi= Attention ( Q W i Q , K W i K , V W i V ) \left(Q W_{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right) (QWiQ,KWiK,VWiV), W i Q ∈ R d model × d k W_{i}^{Q} \in \mathbb{R}^{d_{\text{model}} \times d_{k}} WiQ∈Rdmodel×dk, W i K ∈ R d model × d k W_{i}^{K} \in \mathbb{R}^{d_{\text { model }} \times d_{k}} WiK∈Rd model ×dk, W i V ∈ R d model × d v W_{i}^{V} \in \mathbb{R}^{d_{\operatorname{model}} \times d_{v}} WiV∈Rdmodel×dv, W O ∈ R h d v × d m o d e l W^{O} \in \mathbb{R}^{h d_{v} \times d_{\mathrm{model}}} WO∈Rhdv×dmodel。
对于encoder中的每一层multi-head attention,每一个时间步都会融合各个时间步的信息,随着层数的加深,其信息量会更加丰富。而对于decoder中的multi-head attention,有两个地方需要注意,首先是每一层中的第一层multi-head attention,为了避免在每次解码时偷看到后面的信息,需要添加一个mask层,也就是在 Q Q Q和 K K K计算完之后,将后面的序列的值置为 − ∞ -\infty −∞,这样经过softmax之后就可以转变为0。另一个需要注意的地方是第二层multi-head attention,该层会将encoder的输出作为 K 、 V K、V K、V的输入,这样在每次decoder时,就可以注意到encoder中的局部信息。
2.3 Position-wise Feed-Forward Networks
Transformer模型的每一层中除了multi-head attention层之外,还有一层position-wise feed-forward子层,该子层含有两层全连接层,第一层全连接层带有Relu激活函数,其输出维度为 d f f = 2048 d_{f f}=2048 dff=2048,第二层全连接层的输出维度为 d m o d e l d_{model} dmodel,具体的计算公式如下:
F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \mathrm{FFN}(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2} FFN(x)=max(0,xW1+b1)W2+b2
2.4 Positional Encoding
由于Transformer没有采用RNN或CNN,因此,单独用self-attention是没法引入序列的时序信息的,因此,Transformer对位置也进行了embedding,其计算公式如下:
P E ( p o s , 2 i ) = sin ( pos / 1000 0 2 i / d model ) P E ( p o s , 2 i + 1 ) = cos ( pos / 1000 0 2 i / d model ) PE_{(p o s, 2 i)}=\sin \left(\operatorname{pos} / 10000^{2 i / d_{\operatorname{model}}}\right) \\ PE_{(p o s, 2 i+1)}=\cos \left(\operatorname{pos} / 10000^{2 i / d_{\operatorname{model}}}\right) PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)其中 p o s pos pos表示序列中第几个位置, i i i表示embedding的维度,每个位置的embedding维度跟词汇的embedding维度一致,都为 d m o d e l d_{model} dmodel,然后在encoder或decoder的输入时,将词汇的embedding和位置的embedding进行相加,这样就能引入序列的时序信息,作者之所以采用正弦曲线作为位置信息的编码方式,是因为 P E p o s + k PE_{p o s+k} PEpos+k可以用 P E p o s PE_{p o s} PEpos经过线性变换得到,当句子的长度超过训练时的最大长度时,对于那些超出的位置信息,就可以用短一点的位置信息经过线性变换得到。
3. Transformer的tensorflow实现
采用tensorflow对Transformer进行复现,代码如下:
import config
import numpy as np
import tensorflow as tf
from config import transformer_config
class Transformer(object):
def __init__(self,
embedding_size=transformer_config.embedding_size,
num_layers=transformer_config.num_layers,
keep_prob=transformer_config.keep_prob,
learning_rate=transformer_config.learning_rate,
learning_decay_steps=transformer_config.learning_decay_steps,
learning_decay_rate=transformer_config.learning_decay_rate,
clip_gradient=transformer_config.clip_gradient,
is_embedding_scale=transformer_config.is_embedding_scale,
multihead_num=transformer_config.multihead_num,
label_smoothing=transformer_config.label_smoothing,
max_gradient_norm=transformer_config.clip_gradient,
encoder_vocabs=config.encoder_vocabs + 2,
decoder_vocabs=config.decoder_vocabs + 2,
max_encoder_len=config.max_encoder_len,
max_decoder_len=config.max_decoder_len,
share_embedding=config.share_embedding,
pad_index=None
):
self.embedding_size = embedding_size
self.num_layers = num_layers
self.keep_prob = keep_prob
self.learning_rate = learning_rate
self.learning_decay_steps = learning_decay_steps
self.learning_decay_rate = learning_decay_rate
self.clip_gradient = clip_gradient
self.encoder_vocabs = encoder_vocabs
self.decoder_vocabs = decoder_vocabs
self.max_encoder_len = max_encoder_len
self.max_decoder_len = max_decoder_len
self.share_embedding = share_embedding
self.is_embedding_scale = is_embedding_scale
self.multihead_num = multihead_num
self.label_smoothing = label_smoothing
self.max_gradient_norm = max_gradient_norm
self.pad_index = pad_index
self.build_model()
def build_model(self):
# 初始化变量
self.encoder_inputs = tf.placeholder(tf.int32, [None, None], name='encoder_inputs')
self.encoder_inputs_length = tf.placeholder(tf.int32, [None], name='encoder_inputs_length')
self.batch_size = tf.placeholder(tf.int32, [], name='batch_size')
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
self.decoder_inputs = tf.placeholder(tf.int32, [None, None], name='decoder_inputs')
self.decoder_targets = tf.placeholder(tf.int32, [None, None], name='decoder_targets')
self.decoder_inputs_length = tf.shape(self.decoder_inputs)[1]
self.decoder_targets_length = tf.placeholder(tf.int32, [None], name='decoder_targets_length')
self.targets_mask = tf.sequence_mask(self.decoder_targets_length, self.max_decoder_len,
dtype=tf.float32, name='masks')
self.itf_weight = tf.placeholder(tf.float32, [None, None], name='itf_weight')
# embedding层
with tf.name_scope("embedding"):
# encoder_embedding = tf.get_variable(
# 'encoder_embedding', [self.encoder_vocabs, self.embedding_size],
# initializer=tf.random_normal_initializer(0., self.embedding_size ** -0.5)
# )
zero = tf.zeros([1, self.embedding_size], dtype=tf.float32) # for padding
# embedding_table = tf.Variable(tf.random_uniform([self.voca_size-1, self.embedding_size], -1, 1))
encoder_embedding = tf.get_variable(
# https://github.com/tensorflow/models/blob/master/official/transformer/model/embedding_layer.py
'embedding_table',
[self.encoder_vocabs - 1, self.embedding_size],
initializer=tf.random_normal_initializer(0., self.embedding_size ** -0.5))
front, end = tf.split(encoder_embedding, [self.pad_index, self.encoder_vocabs - 1 - self.pad_index])
encoder_embedding = tf.concat((front, zero, end), axis=0) # [self.voca_size, self.embedding_size]
encoder_position_encoding = self.positional_encoding(self.max_encoder_len)
if not self.share_embedding:
decoder_embedding = tf.get_variable(
'decoder_embedding', [self.decoder_vocabs, self.embedding_size],
initializer=tf.random_normal_initializer(0., self.embedding_size ** -0.5)
)
decoder_position_encoding= self.positional_encoding(self.max_decoder_len)
# encoder
with tf.name_scope("encoder"):
encoder_inputs_embedding, encoder_inputs_mask = self.add_embedding(
encoder_embedding, encoder_position_encoding, self.encoder_inputs,tf.shape(self.encoder_inputs)[1]
)
self.encoder_outputs = self.encoder(encoder_inputs_embedding, encoder_inputs_mask)
# decoder
with tf.name_scope('decoder'):
if self.share_embedding:
decoder_inputs_embedding, decoder_inputs_mask = self.add_embedding(
encoder_embedding, encoder_position_encoding, self.decoder_inputs,self.decoder_inputs_length
)
else:
decoder_inputs_embedding, decoder_inputs_mask = self.add_embedding(
decoder_embedding, decoder_position_encoding, self.decoder_inputs,self.decoder_inputs_length
)
self.decoder_outputs, self.predict_ids= self.decoder(decoder_inputs_embedding, self.encoder_outputs,
decoder_inputs_mask,encoder_inputs_mask)
# loss
with tf.name_scope('loss'):
# label smoothing
self.targets_one_hot = tf.one_hot(
self.decoder_targets,
depth=self.decoder_vocabs,
on_value=(1.0 - self.label_smoothing) + (self.label_smoothing / self.decoder_vocabs),
off_value=(self.label_smoothing / self.decoder_vocabs),
dtype=tf.float32
)
loss = tf.nn.softmax_cross_entropy_with_logits(
labels=self.targets_one_hot,
logits=self.decoder_outputs
)
if config.use_itf_loss:
loss *= self.itf_weight
else:
loss *= self.targets_mask
self.loss = tf.reduce_sum(loss) / tf.reduce_sum(self.targets_mask)
# 优化函数,对学习率采用指数递减的形式
self.global_step = tf.train.get_or_create_global_step()
learning_rate = tf.train.exponential_decay(self.learning_rate, self.global_step,
self.learning_decay_steps, self.learning_decay_rate,
staircase=True)
optimizer = tf.train.AdamOptimizer(learning_rate)
trainable_params = tf.trainable_variables()
gradients = tf.gradients(self.loss, trainable_params)
clip_gradients, _ = tf.clip_by_global_norm(gradients, self.max_gradient_norm)
self.train_op = optimizer.apply_gradients(zip(clip_gradients, trainable_params))
# summary
tf.summary.scalar('loss', self.loss)
self.merged = tf.summary.merge_all()
def encoder(self, encoder_inputs_embedding, encoder_inputs_mask):
# multi-head attention mask
encoder_self_attention_mask = tf.tile(
tf.matmul(encoder_inputs_mask, tf.transpose(encoder_inputs_mask, [0, 2, 1])),
[self.multihead_num, 1, 1]
)
encoder_outputs = encoder_inputs_embedding
for i in range(self.num_layers):
# multi-head selt-attention sub_layer
multi_head_outputs = self.multi_head_attention_layer(
query=encoder_outputs,
key_value=encoder_outputs,
score_mask=encoder_self_attention_mask,
output_mask=encoder_inputs_mask,
activation=None,
name='encoder_multi_' + str(i)
)
# point-wise feed forward sub_layer
encoder_outputs = self.feed_forward_layer(
multi_head_outputs,
output_mask=encoder_inputs_mask,
activation=tf.nn.relu,
name='encoder_dense_' + str(i)
)
return encoder_outputs
def decoder(self, decoder_inputs_embedding, encoder_outputs, decoder_inputs_mask,encoder_inputs_mask):
# mask
decoder_encoder_attention_mask = tf.tile(
tf.transpose(encoder_inputs_mask,[0, 2, 1]),
[self.multihead_num, 1, 1]
)
decoder_self_attention_mask = tf.tile(tf.expand_dims(tf.sequence_mask(
tf.range(start=1, limit=self.decoder_inputs_length + 1),
maxlen=self.decoder_inputs_length,
dtype=tf.float32),axis=0
),[self.multihead_num*tf.shape(decoder_inputs_embedding)[0],1,1])
decoder_outputs = decoder_inputs_embedding
for i in range(self.num_layers):
# masked multi-head selt-attention sub_layer
masked_multi_head_outputs = self.multi_head_attention_layer(
query=decoder_outputs,
key_value=decoder_outputs,
score_mask=decoder_self_attention_mask,
output_mask=decoder_inputs_mask,
activation=None,
name='decoder_first_multi_' + str(i)
)
# multi-head selt-attention sub_layer
multi_head_outputs = self.multi_head_attention_layer(
query=masked_multi_head_outputs,
key_value=encoder_outputs,
score_mask=decoder_encoder_attention_mask,
output_mask=decoder_inputs_mask,
activation=None,
name='decoder_second_multi_' + str(i)
)
# point-wise feed forward sub_layer
decoder_outputs = self.feed_forward_layer(
multi_head_outputs,
output_mask=decoder_inputs_mask,
activation=tf.nn.relu,
name='decoder_dense_' + str(i)
)
# output_layer
decoder_outputs = tf.layers.dense(decoder_outputs,units=self.decoder_vocabs,activation=None,name='outputs')
predict_ids = tf.argmax(decoder_outputs,axis=-1,output_type=tf.int32)
return decoder_outputs, predict_ids
def multi_head_attention_layer(self, query, key_value, score_mask=None, output_mask=None,
activation=None,name=None):
"""
multi-head self-attention sub_layer
:param query:
:param key_value:
:param score_mask:
:param output_mask:
:param activation:
:param name:
:return:
"""
with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
# 计算Q、K、V
V = tf.layers.dense(key_value,units=self.embedding_size,activation=activation,use_bias=False,name='V')
K = tf.layers.dense(key_value,units=self.embedding_size,activation=activation,use_bias=False,name='K')
Q = tf.layers.dense(query,units=self.embedding_size,activation=activation,use_bias=False,name='Q')
# 将Q、K、V分离为multi-heads的形式
V = tf.concat(tf.split(V, self.multihead_num, axis=-1),axis=0)
K = tf.concat(tf.split(K, self.multihead_num, axis=-1),axis=0)
Q = tf.concat(tf.split(Q, self.multihead_num, axis=-1),axis=0)
# 计算Q、K的点积,并进行scale
score = tf.matmul(Q, tf.transpose(K, [0, 2, 1])) / tf.sqrt(self.embedding_size / self.multihead_num)
# mask
if score_mask is not None:
score *= score_mask
score += ((score_mask - 1) * 1e+9)
# softmax
softmax = tf.nn.softmax(score,dim=2)
# dropout
softmax = tf.nn.dropout(softmax, keep_prob=self.keep_prob)
# attention
attention = tf.matmul(softmax,V)
# 将multi-head的输出进行拼接
concat = tf.concat(tf.split(attention, self.multihead_num, axis=0),axis=-1)
# Linear
Multihead = tf.layers.dense(concat,units=self.embedding_size,activation=activation,
use_bias=False,name='linear')
# output mask
if output_mask is not None:
Multihead *= output_mask
# 残差连接前的dropout
Multihead = tf.nn.dropout(Multihead, keep_prob=self.keep_prob)
# 残差连接
Multihead += query
# Layer Norm
Multihead = tf.contrib.layers.layer_norm(Multihead, begin_norm_axis=2)
return Multihead
def feed_forward_layer(self, inputs, output_mask=None, activation=None, name=None):
"""
point-wise feed_forward sub_layer
:param inputs:
:param output_mask:
:param activation:
:param name:
:return:
"""
with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
# dense layer
inner_layer = tf.layers.dense(inputs,units=4 * self.embedding_size,activation=activation)
dense = tf.layers.dense(inner_layer,units=self.embedding_size,activation=None)
# output mask
if output_mask is not None:
dense *= output_mask
# dropout
dense = tf.nn.dropout(dense, keep_prob=self.keep_prob)
# 残差连接
dense += inputs
# Layer Norm
dense = tf.contrib.layers.layer_norm(dense, begin_norm_axis=2)
return dense
def add_embedding(self, embedding,position_encoding,inputs_data,data_length):
# 将词汇embedding与位置embedding进行相加
inputs_embedded = tf.nn.embedding_lookup(embedding,inputs_data)
if self.is_embedding_scale is True:
inputs_embedded *= self.embedding_size ** 0.5
inputs_embedded += position_encoding[:data_length, :]
# embedding_mask
embedding_mask = tf.expand_dims(
tf.cast(tf.not_equal(inputs_data, self.pad_index), dtype=tf.float32),
axis=-1
)
inputs_embedded *= embedding_mask
# embedding dropout
inputs_embedded = tf.nn.dropout(inputs_embedded, keep_prob=self.keep_prob)
return inputs_embedded,embedding_mask
def positional_encoding(self,sequence_length):
"""
positional encoding
:return:
"""
position_embedding = np.zeros([sequence_length, self.embedding_size])
for pos in range(sequence_length):
for i in range(self.embedding_size // 2):
position_embedding[pos, 2 * i] = np.sin(pos / np.power(10000, 2 * i / self.embedding_size))
position_embedding[pos, 2 * i + 1] = np.cos(pos / np.power(10000, 2 * i / self.embedding_size))
position_embedding = tf.convert_to_tensor(position_embedding, dtype=tf.float32)
return position_embedding
def train(self, sess, encoder_inputs, encoder_inputs_length, decoder_inputs,
decoder_targets, decoder_targets_length, itf_weight,
keep_prob=transformer_config.keep_prob):
feed_dict = {self.encoder_inputs: encoder_inputs,
self.encoder_inputs_length: encoder_inputs_length,
self.decoder_inputs: decoder_inputs,
self.decoder_targets: decoder_targets,
self.decoder_targets_length: decoder_targets_length,
self.keep_prob: keep_prob,
self.batch_size: len(encoder_inputs),
self.itf_weight: itf_weight}
_, train_loss = sess.run([self.train_op, self.loss], feed_dict=feed_dict)
return train_loss
def eval(self, sess, encoder_inputs_val, encoder_inputs_length_val, decoder_inputs_val,
decoder_targets_val, decoder_targets_length_val, itf_weight_val):
feed_dict = {self.encoder_inputs: encoder_inputs_val,
self.encoder_inputs_length: encoder_inputs_length_val,
self.decoder_inputs: decoder_inputs_val,
self.decoder_targets: decoder_targets_val,
self.decoder_targets_length: decoder_targets_length_val,
self.keep_prob: 1.0,
self.batch_size: len(encoder_inputs_val),
self.itf_weight: itf_weight_val}
val_loss = sess.run(self.loss, feed_dict=feed_dict)
summary = sess.run(self.merged, feed_dict=feed_dict)
return val_loss, summary
4. 总结
最后总结一下:
- Transformer由于采用纯attention的形式,因此,在训练时可以充分利用GPU的并行计算能力,极大提高了模型的训练速度。
- 由于Transformer在每一层都采用attention,因此,模型的解码能力要相对Seq2Seq更强。